




- @qq_18625571
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
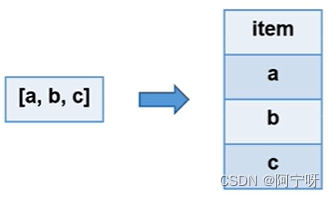
将一行数据拆分多行,即制表函数,接收一行数据,输出一行或多行数据。
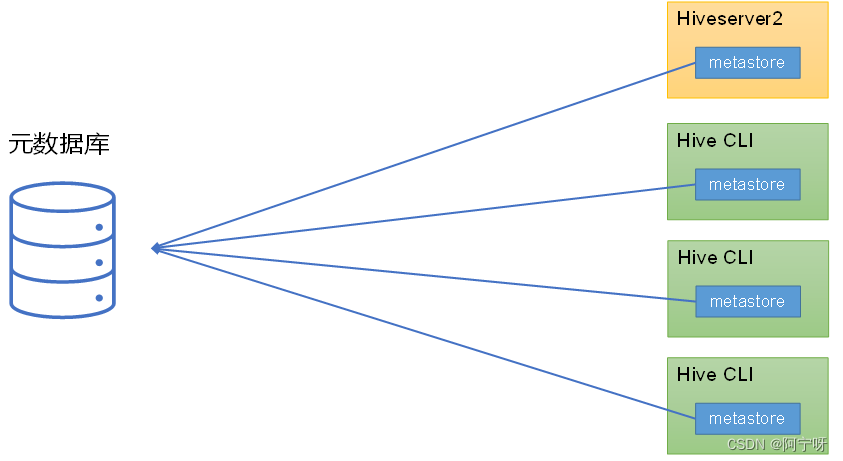
metastore为Hive CLI或Hiveserver2提供元数据访问接口。
小文件优化可以从两个方面解决,在Map端输入的小文件合并,在Reduce端输出的小文件合并。

Hive的计算任务由MapReduce完成,并行度调整分为Map端和Reduce端。
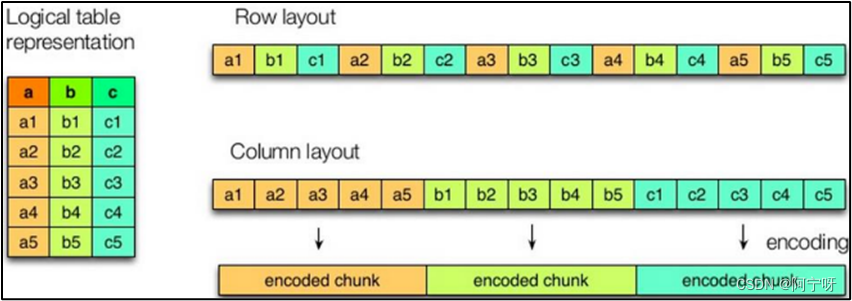
ORC是列式存储的文件格式,可以提高hive读写数据和处理数据的性能。左边为逻辑表。右边第一个为行式存储:取文件的一行数据存储到相邻的位置;第二个为列式存储:取文件的一列数据存储到相邻的位置。查询满足条件的一整行数据的时候,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。列式存储查找一行数据时需要去每个字段中找对应的每个列的值。因为每个字段的数据聚集存储,在查询只需
tushare ID:441914我是用jupyter做的分析,先导入相关的库,记得设置tushare的token。import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom matplotlib.collections import LineCollectionimport matplotlib.cm as c
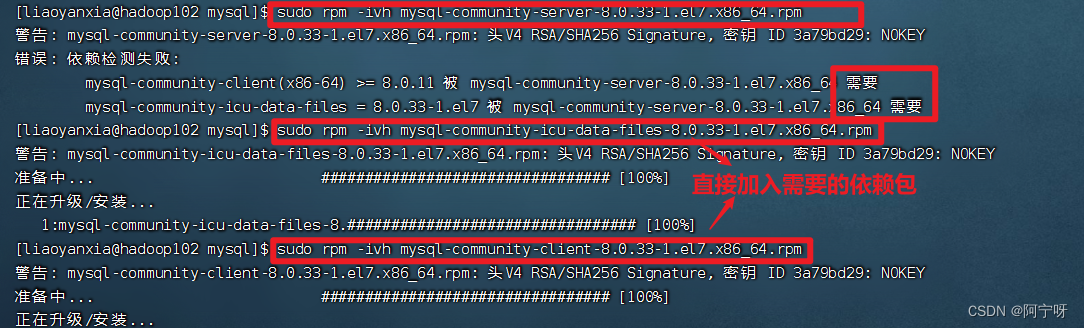
解决方法:用yum直接下载。
(3)如果ReduceTask的数量==1,则不管MapTask端输出多少分区文件,最终结果都交给一个 ReduceTask,即使用默认分区,只产生一个结果文件。(2)如果 1 < ReduceTask的数量 < getPartition的结果数,则有部分分区数据无处存储,会抛出IO异常。(3)自定义Partition后,根据自定义的逻辑设置相应数量的ReduceTask。不设置时默认为1,则使用

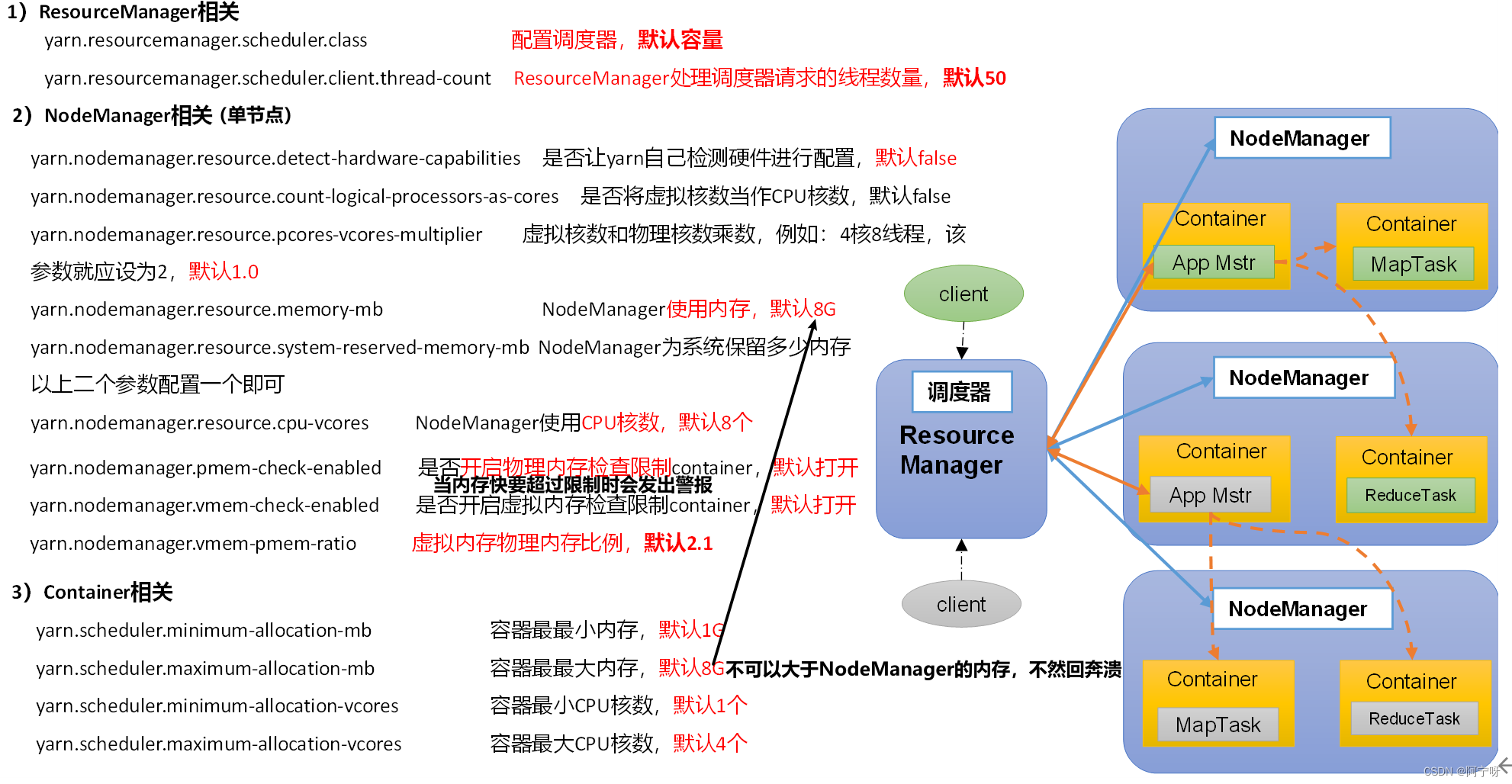
容量调度器,支持任务优先级的配置,在资源紧张时,优先级高的任务将优先获取资源。默认情况,Yarn将所有任务的优先级限制为0,若想使用任务的优先级功能,须开放该限制。(1)default队列占总内存的40%,最大资源容量占总资源60%,hive队列占总内存的60%,最大资源容量占总资源80%。(2)像双十一、618在资源紧张时期保证任务队列资源充足,给任务设置优先级,优先级高的先处理,即对任务进行降
源码中:job提交三个信息(jar包,xml,切片信息),在本地不需要提交jar包,只有在集群上才需要提交。
