- @zjjcchina
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
商品 SPU 和 SKU 的添加、修改、 删除、复制、批处理、商品计划上下架、SEO、商。求负载、请求过滤、统一鉴权和限流,使用 Sentinel 进行服务的熔断和降级,使用。可以介绍项目是什么类型的(B2C、B2B2C、O2O 这类),为什么要做这个项目,SKU 以及销售属性、商品上下架和商品评论管理等)、内容广告模块、库存管理模。各类主要信息的概要统计,包括客户信息、 订单信息、商品信息、库存
例如:ambari-server setup –jdbc-db={database-type} –jdbc-driver={/jdbc/driver/path}2)创建rangerdba用户并授权。1)进入MySQL数据库。
摘要:企业级容器云实战,真正实现云上亿级流量永不宕机!若逢新雪初霁,满月当空。他带笑向我们走来,月色与雪色间,他是第三种绝色。他浑身上下都是宝,上知天文,下晓地理,中通人和,他就是我们的老朋友——雷神!世上有这样一个人,他能把你拉出深渊,助你跋涉沼泽,教你横渡江河,带你翻山越岭,陪你登顶高峰,和你一路看遍人生的风景。这个人……不是雷神,是你自己,其实人人皆为自度。雷神不空手,提前带来了圣诞礼物。汪

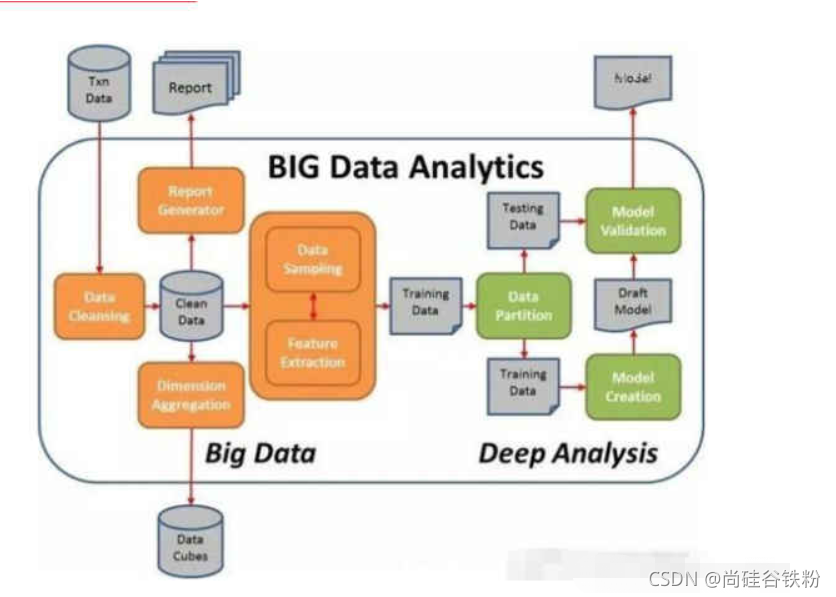
问题描述工业场景中,时序数据的可视化是一个无法回避的话题。时序数据的超大数据量给图形的展示性能带来了挑战,而通过降采样的方式减少图形的展示点数来迎合性能的同时,又会带来算法复杂度、算法可伸缩以及正确性等多方面的权衡。下面通过几种常用的可视化降采样算法的研究和实践对比,为时序数据的可视化降采样算法选择提供参考。我们使用实际生产中的一个案例作为算法描述的基础:需求将10w的点降采样到4000,以适配页
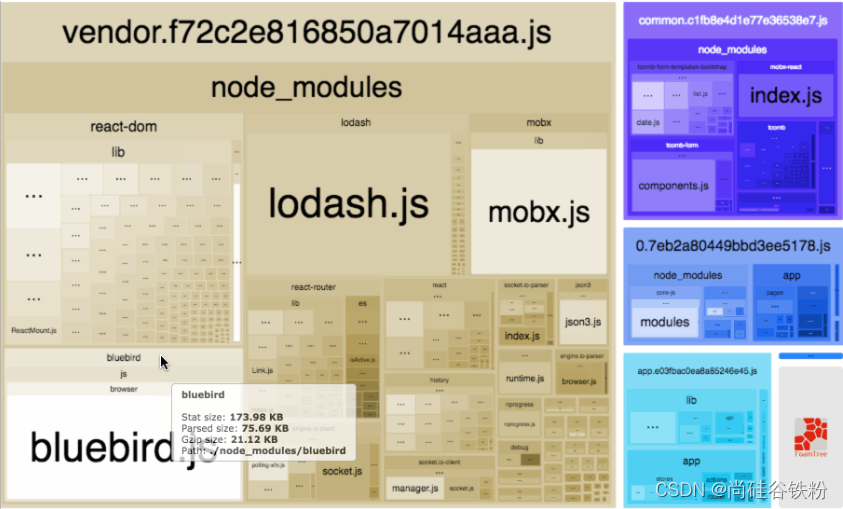
大家在开发前端项目的时候,随着项目的不断更新迭代以及产品经理的不断提需求,势必会用到各种各样的第三方库,那么我们用到的第三方库越来越多,整体项目的依赖也就会越来越多,整体项目打包的时候体积也就会越来越大,用webpack去build的时候时间也会越长。这些倒不是最主要的,我们做的一般都是单页面应用,如果随着第三方库越来越多,咱们项目首页的白屏时间也会加长,用户体验感会很差,这是我们不得不面对的一个
随着大数据时代的发展,越来越多的人开始投身于大数据分析行业。当我们进行大数据分析时,我们经常听到熟悉的行业词,如数据分析、数据挖掘、数据可视化等。然而,虽然一个行业词的知名度不如前几个词,但它的重要性相当于前几个词,即数据清洗。顾名思义,数据清洗是清洗脏数据,是指在数据文件中发现和纠正可识别错误的最后一个程序,包括检查数据一致性、处理无效值和缺失值。哪些数据被称为脏数据?例如,需要从数据仓库中提
ajax 跨域时session丢失了!!!解决方法:首先我 Google 了一下这个问题的原因,我找到了这个:(1)Access-Control-Allow-Origin该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求。(2)Access-Control-Allow-Credentials该字段可选。它的值是一个布尔值,表示是否允许发送Cookie。默认
首先作为前端开发人员,大家都应该使用过Ajax发送请求,目前市面上流行的发送Ajax请求的方式为以下三种:Jquery的$.ajax()尤雨溪推荐的axioses6新出的fetch方法这三种方法的区别详见文章ajax三种方式的区别,这里不再详细解释。本篇文章主要讲工作中是如何使用ajax请求,也就是让ajax结合promise使用。1.为什么要包装ajax?小明同学说:“直接发送ajax请求不就得
由于目前只有三台服务器,且有三个副本,数据读取就近原则,相当于都是读取的本地磁盘数据,没有走网络。注意nrFilesn为生成mapTask的数量,生产环境一般可通过hadoop1038088查看CPU核数,设置为(CPU核数–1)1byte=8bit,100Mbps/8=12.5M/s。--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true-->1)
Hadoop的数据分配主要有数据分片,数据分区和数据下载,其中分片是按照文件数量和文件大小来分片的,所以不会倾斜,而数据分区Hadoop默认是采用key.hashcode&Integer.MaxValue % numReduceTask来进行分区号分配,后面的分区下载数据也是根据分区号来的,所以如果key的hashcode值不均匀,其分区号分配就会倾斜,数据在进行按分区号归并时就会产生倾斜。比如我