登录社区云,与社区用户共同成长
邀请您加入社区
赛博周刊,每周发布。
生成式AI应用的规模化(Scale)不是简单扩容,而是应对计算、内存与网络三重压力叠加的系统工程。其核心原理在于解耦推理、编排、接入与数据四层职责,通过动态批处理、PagedAttention内存管理、模型量化等关键技术提升单位算力吞吐,并依托全链路追踪与混沌工程实现高可用治理。典型应用场景包括客服问答、智能文档助手、实时内容生成等需支撑日活数十万至百万级用户的在线服务。本文聚焦GenAI在真实生
生成式人工智能(GenAI)正从概念验证走向大规模生产部署,其核心在于解决动态、非确定性的AI应用与传统IT运维追求的静态、确定性之间的根本矛盾。从技术原理上看,这涉及到模型推理的资源不可预测性、数据安全与隐私的穿透性风险,以及复杂异构环境的统一管理。其技术价值在于构建一个能够支撑核心业务流程、处理海量敏感数据、服务高并发用户的可靠AI平台。在应用场景上,这要求贯穿设计、开发、部署、运维的全生命周
Cohesity获得美国专利商标局授予的第12,619,501号专利,涵盖其企业数据生成式AI平台Cohesity Gaia™的核心技术。该专利名为"使用嵌入技术检索备份系统中的数据",通过将辅助数据系统与检索增强生成(RAG)语义层结合,使企业能在不移动敏感数据的情况下安全应用生成式AI。这一创新解决了数据孤岛问题,同时保持治理控制和安全性,让企业能够利用历史备份数据进行AI
生成式人工智能(GenAI)作为当前AI技术发展的重要方向,正在全球范围内引发生产力变革。其核心原理基于深度学习模型,通过大规模数据训练实现文本、图像等内容生成。在数字化转型背景下,GenAI显著提升了工作效率,特别是在文本处理、数据分析等场景展现突出价值。沙特阿拉伯的实践表明,年轻群体对GenAI的接受度最高,形成了从日常应用到专业场景的三层使用结构。值得注意的是,技术认知与使用频率呈现强相关性
Agentic AI并非泛指大模型自主决策,而是面向企业级场景的可控智能体系统。其核心原理在于将智能行为解耦为感知、决策、执行与协调四类责任明确的Agent,通过标准化契约、置信度过滤、结构化推理和离线案例学习实现稳定交付。技术价值体现在任务完成率、人工干预率、错误自愈成功率等可测指标上,广泛应用于电商售后、金融合规、SaaS运维等需高可靠性与强可解释性的业务流程。本文聚焦Agentic AI在真
GenAI Agent 不是简单调用大模型API,而是具备工具调用、多步推理和短期记忆的智能体,其本质是重构用户交互链路。它通过分层架构实现安全可控的业务编排,解决传统API集成中密钥泄露、上下文失控与逻辑碎片化等核心问题。关键技术价值在于将模糊查询转化为结构化任务流,并依托Python网关层完成异构系统胶合与流式响应治理。典型应用场景包括智慧图书馆文献精准检索、政务材料一键生成及教育SaaS课程
生成式人工智能(GenAI)正在深刻改变汽车软件开发流程,特别是在需求分析和测试验证环节。传统开发中,需求工程和测试场景搭建往往占据大量时间和成本,而GenAI技术栈通过LLM核心层、RAG增强层和MDE验证层的结合,显著提升了效率。例如,采用Llama3-70B模型在需求解析任务中达到92.3%的准确率,而SmartChunking技术则使法规文档的关键参数提取完整度从68%提升至89%。这些技
简历筛选本质上是技术能力语义匹配问题,其核心在于将非结构化PDF文本映射到岗位JD定义的细粒度能力节点。传统端到端大模型方案因缺乏领域锚点易产生幻觉,而基于能力图谱驱动的‘小模型+大模型协同’架构,通过AutoML完成结构化能力识别、Claude 3执行证据级语义校验,显著提升技术术语判别精度与可解释性。该模式兼顾推理效率、成本可控与工程可维护性,适用于ATS智能升级、HR Tech产品集成及Ha
生成式人工智能(GenAI)正从内容生成迈向专业决策支持,其核心价值在于对非结构化文本的理解与可验证推理。在招聘场景中,传统关键词匹配的ATS系统难以捕捉‘用脚本自动化日报生成’背后的Python工程能力,而端到端大模型又面临延迟高、幻觉强、不可审计等落地瓶颈。本文基于DataRobot与AWS Hackathon真实项目,提出‘结构化解析→特征锚定→综合决策’的混合推理链架构,融合轻量级小模型(
生成式AI(GenAI)标志着语言理解与生成能力的质变,使AI首次具备实用级文本输出能力;AI Agent则通过工具调用、规划与反思机制,实现从被动响应到主动执行的关键跨越;而Agentic AI进一步引入多智能体协同、分布式通信与动态协商,支撑复杂系统级任务闭环。这一演进路径本质是AI角色从‘内容助手’向‘数字同事’的升级,其技术价值在于降低人机协作门槛、提升跨系统任务自动化深度,并已在风控、客
为确保本文自成体系并阐明 GRPO 的理论基础,我们将首先介绍强化学习的基础概念,重点解析强化学习(RL)及基于人类反馈的强化学习(RLHF)在 LLM 训练中的核心作用。接着我们将探讨不同的强化学习范式,包括基于价值的强化学习、基于策略的强化学习和 Actor-Critic 强化学习,回顾经典算法如置信域策略优化(TRPO)和近端策略优化(PPO),最后解析 GRPO 带来的优化创新。在 GRP
生成式AI(GenAI)正从云端服务转向终端设备,端侧大模型成为隐私保护、低延迟交互与离线可用性的关键技术路径。其核心原理在于将轻量化Transformer模型(如3B~7B参数量)深度适配终端NPU硬件,通过内存优化、稀疏注意力与安全隔离实现高效推理。技术价值体现在毫秒级响应、零数据上传与系统级资源协同,广泛应用于智能语音助手、实时文本生成、本地图像理解等场景。本文聚焦Apple GenAI在i
AI是需求引擎,芯片是算力底座,存储是最紧缺的"血液"。三者形成了"需求确定 → 供给刚性 → 涨价传导 → 业绩爆发"的正向循环——这是一次罕见的技术革命与产业周期的共振,而非单纯的概念炒作。
告别云端隐私泄露与高昂成本,GitNexus 让你将大模型装进口袋!🚀 本文深度解析如何利用量化与推理引擎,在本地设备零门槛运行 AI。无需复杂配置,即可体验数据完全私有、低延迟的智能快感,助你掌握端侧 AI 的核心技术。
软件工程因其开放、可执行、可验证、可累积的独特属性,是 AGI 的最佳"训练道场",而 Anthropic 凭借把 Coding Agent 作为公司主线(而非产品线)的战略定力,正在这条窄门上建立起 OpenAI 和 Google 短期内难以追赶的代差优势。
谷歌I/O 2026大会宣布全面进入"智能体Gemini时代",推出Gemini 3.5 Flash、Omni等多款AI产品,构建统一智能生态。AI制药公司Isomorphic Labs完成21亿美元B轮融资,创行业纪录。Anthropic估值或达9000亿美元,企业AI采购进入规模化阶段。美国政府启动AI安全预审查机制,五大前沿实验室参与。分析指出,AI正从模型竞赛转向生态系统建设,企业级应用迎
《工业级AI智能体生产部署实战指南》摘要:开源项目agents-towards-production针对企业级AI部署痛点,提出端到端解决方案。该项目采用四层架构设计(状态管理、可观测性、高可用闸门和质量评估),重点解决多会话隔离、全链路监控等核心问题。通过Redis/PostgreSQL实现状态持久化,结合OpenTelemetry实现精细化追踪,并引入反向压力机制保障系统稳定性。项目提供完整代
OpenTelemetry(后文简称 OTel)早在 2024 年初就开始推动 Gen AI 语义规范建设,希望为这些新对象建立统一的数据采集规范——Semantic Conventions(后文简称 SemConv),以解决相关领域可观测数据采集标准缺失、口径不统一等问题。
自从2022年底,发布以来,诸如(Artificial General Intelligence,人工通用智能)、
作为对本章知识的总结,本节将实现一个综合演示:让Gemini扮演艺术评论家,对用户通过FastRTC上传的艺术作品进行点评。
然而,由于余弦函数和正弦函数是周期性的,(pos_i, pos_j) 之间的内积可能看起来与 (pos_i, pos_k) 之间的内积相似,因此在固定 θ 的情况下,仅使用 1K tokens(即位置索引 1~1000) 进行预训练的模型在测试时可能会混淆,因为测试时遇到的位置索引(如 5K 或 10K)可能远远超出了预训练时的上下文窗口。由于我们已在前文中讨论过相关内容,此处不再赘述。需特别说明
UB-PMC 包含真实的科学图表,而 Synth 则是生成的模拟图表。ChartDETR 等先进方法结合了 CNN 和 Transformer,实现了端到端的数据提取,而 FR-DETR 等模型则优化了流程图和树状图的结构提取,但处理复杂连接线的挑战依然存在。最初,这一领域依赖于基于规则的方法,但现在,深度学习技术的应用,如使用边界框和图像分割,极大地提升了检测的精确度和速度。但当遇到科学和专利文
鉴于 CUDA kernels 的工作空间为 device 的内存(device memory),故需向 kernel 提供 device 指针(device pointers)(d_A、d_B 和 d_C),以确保其能在 device 的内存上运行。对于深度学习模型而言,其实质就是一系列涉及矩阵(matrix)与张量(tensor)的运算操作,包括但不限于求和(sum)、乘法(multiplic
一文了解苹果大模型部署方案,包括设备端LLM、云端LLM和第三方LLM(如ChatGPT)。
ONNX Runtime GenAI C++ GPU 推理问题与解决方案 问题概述: 使用 ONNX Runtime GenAI v0.12.0 进行 C++ GPU 推理时遇到三个主要问题:C++ API 兼容性问题、库版本不匹配以及模型 Opset 兼容性问题。 解决方案: 从 C++ API 改为 C API 调用,解决符号缺失问题 通过 CMake 自动下载兼容版本的 onnxruntim
在更精细的级别上,你可以将 AI 代理视为支持它们的模型的 UI“包装器”。也就是说,人工智能代理通常是用户友好的“前端”,通常通过关注和限制用户与模型的交互方式,使使用驱动它们的模型变得更加容易。现在,有了人工智能代理,想要与人工智能互动的用户只需登录一个界面,就可以开展业务,从询问他们的文件问题到获得家庭作业的帮助。
赛博周刊2025上半年工具精选分享,欢迎收藏。
这一步会产生部分被掩码的 token 序列。该序列被输入模型的核心组件 —— mask predictor(这是一个基于 Transformer 的模型),该模型通过计算掩码 token 上的交叉熵损失,训练其还原被掩码的 token。与预训练类似,我们随机掩码样本中的部分 token,但此次仅掩码响应部分的 token,保留提示词完整。更令人惊喜的是,LLaDA 在逆向推理任务中表现出色,有效解
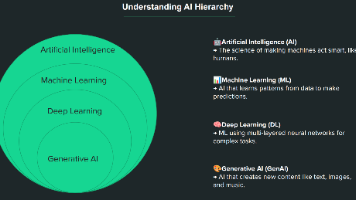
GenAI
——GenAI
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 智能体开发者社区
智能体开发者社区


 AI Agent技术社区
AI Agent技术社区


 AtomGit AI 社区
AtomGit AI 社区


 MCP技术社区
MCP技术社区

 CSDN-OPC开发者社区
CSDN-OPC开发者社区


 脑启社区
脑启社区


 AtomGit开源社区
AtomGit开源社区










 魔乐社区
魔乐社区





 2048 AI社区
2048 AI社区