




- @qq_53609042
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
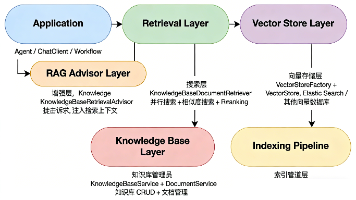
本文深入解析了阿里巴巴开源的SpringAIAlibaba RAG框架,从架构设计、核心原理到最佳实践全面剖析。重点介绍了RAG五大核心阶段(解析、分块、知识库管理、向量化存储、检索层)和三大检索策略(并行多知识库检索、混合搜索、重排序)。特别强调了Advisor模式的创新性,它能自动完成检索和上下文构建,实现业务与检索逻辑解耦。文章还分享了512token分块策略的优化考量,以及生产环境推荐配置
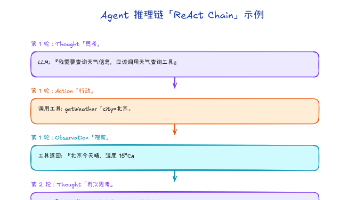
本文深入解析SpringAIAlibaba的AgentFramework智能体编排框架。文章从Agent与传统AI应用的区别入手,介绍了具备自主决策能力的Agent核心特征。重点讲解了ReAct模式(推理+行动)的工作原理,并通过代码示例演示了ReactAgent的创建和使用方法。详细剖析了Hook和Interceptor的生命周期管理机制,比较了二者的作用域和适用场景。系统阐述了五种多智能体编排
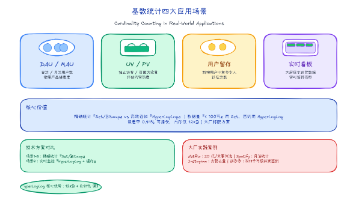
在超大规模数据去重统计(如DAU统计)场景下,传统方案常面临内存爆炸或查询超时的困境。Redis提供了三种核心解决方案:Set 能实现精确统计但内存消耗巨大;HyperLogLog 以极小的固定12KB内存实现亿级数据估算,标准误差仅0.81%,是大规模基数统计的理想选择;Bitmap 则适合用户ID连续的场景,能以较低内存实现精确统计与位运算。简而言之,若业务可接受微小误差,追求极致性能与内存效
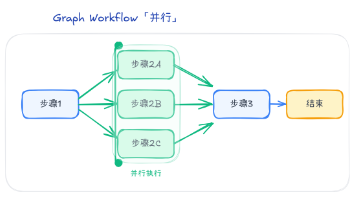
本文深入解析SpringAIAlibaba的GraphWorkflow图工作流机制。GraphWorkflow是基于有向图(DAG)的流程编排框架,通过代码定义节点(Node)、边(Edge)和状态(State)来实现复杂AI任务的多步骤编排。与可视化拖拽平台不同,它提供完全的编程控制能力,同时支持导出可视化图表。核心特性包括:状态管理(KeyStrategy机制)、条件路由、并行执行等。文章通过
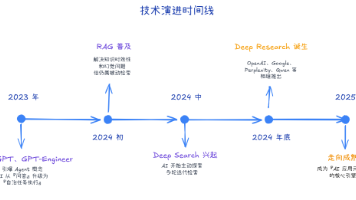
本文是SpringAIAlibaba系列第四篇,深入解析DeepResearch技术及其在GraphWorkflow中的实现。文章首先介绍了DeepResearch的概念演进,从RAG到DeepSearch再到具备复杂推理能力的DeepResearch,分析了其解决企业级AI痛点的优势。重点剖析了DeepResearch四大核心模块(规划、问题演化、网页探索、报告生成)的技术架构,并通过代码示例展
本文深入解析了SpringAIAlibaba框架中的工具调用机制,揭示了Agent如何实现从决策到执行的完整闭环。主要内容包括: 工具调用生命周期五大阶段:注册与发现(定义工具元数据)、选择(LLM决策)、请求构建(参数解析与验证)、执行(通过拦截器链实现扩展)、响应处理(结果回流与循环决策) 核心机制: Hook机制:在关键节点插入治理逻辑(如限流、日志) Interceptor机制:对请求/响
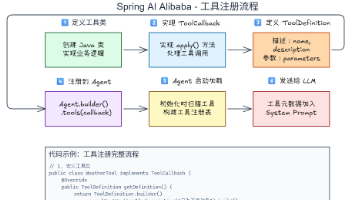
本文深入解析了SpringAIAlibaba框架中的工具调用机制,揭示了Agent如何实现从决策到执行的完整闭环。主要内容包括: 工具调用生命周期五大阶段:注册与发现(定义工具元数据)、选择(LLM决策)、请求构建(参数解析与验证)、执行(通过拦截器链实现扩展)、响应处理(结果回流与循环决策) 核心机制: Hook机制:在关键节点插入治理逻辑(如限流、日志) Interceptor机制:对请求/响
Kafka核心机制与架构演进摘要:本文深入解析Kafka的核心设计理念与架构演进。通过引入Partition机制解决热点IO问题,实现局部有序的消息处理;采用Leader-Follower副本架构保证高可用性,其中ISR机制动态维护同步副本集合。Broker内部各组件协同工作,通过SocketServer、ReplicaManager等模块高效处理消息。重点对比了新旧架构差异:传统ZooKeepe

本文介绍了Kubernetes(K8S)云原生技术的学习笔记,重点解析了K8S的核心架构和组件。文章首先概述K8S作为容器编排平台的核心功能,包括服务发现、存储编排、自动扩缩等特性。随后详细拆解Master-Worker架构:Master节点包含调度器、控制器、API服务等管理组件;Worker节点则运行kubelet、网络代理等执行组件。作者通过比喻方式形象说明各组件职责,强调K8S通过声明式A

本文深入解析了SpringAIAlibaba框架中的工具调用机制,揭示了Agent如何实现从决策到执行的完整闭环。主要内容包括: 工具调用生命周期五大阶段:注册与发现(定义工具元数据)、选择(LLM决策)、请求构建(参数解析与验证)、执行(通过拦截器链实现扩展)、响应处理(结果回流与循环决策) 核心机制: Hook机制:在关键节点插入治理逻辑(如限流、日志) Interceptor机制:对请求/响