登录社区云,与社区用户共同成长
邀请您加入社区
后端的核心框架,它简化了Spring应用的搭建和开发过程。比如,通过简单的配置就能快速搭建一个Web服务器,并且可以轻松集成各种第三方库。像下面这样创建一个简单的Spring Boot项目入口类:这段代码使用注解,它包含了(自动配置)、(组件扫描)等重要功能,使得Spring Boot能自动根据项目的依赖进行配置,扫描并加载相关组件。Vue:前端框架,用于构建用户界面。它采用组件化的开发模式,易于
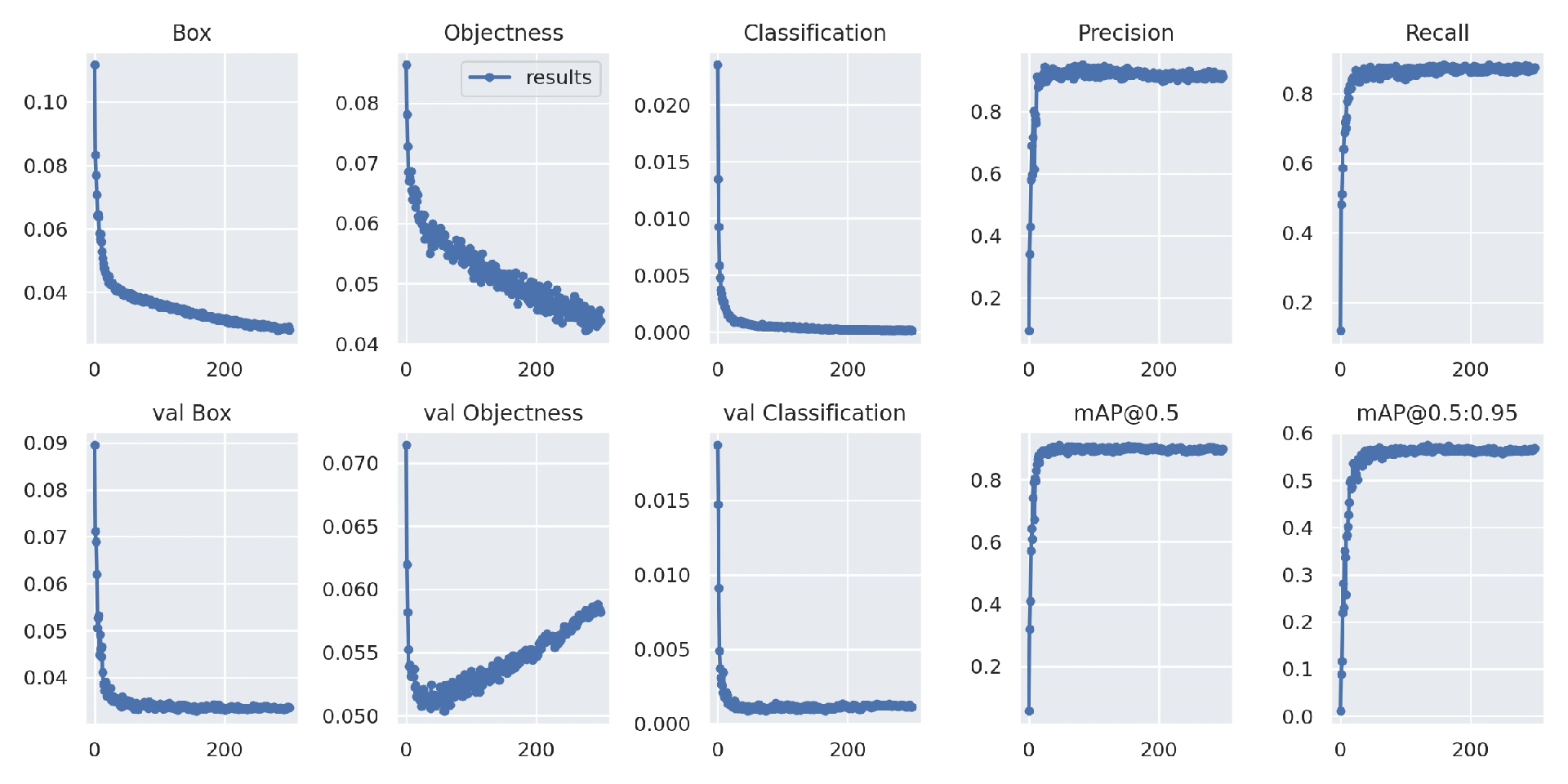
本系统基于YOLOv5目标检测算法,结合PyQt5图形用户界面(GUI)开发,专注于实现安全帽佩戴检测功能。系统支持图片、视频文件及实时摄像头三种检测输入方式,具备模型加载、检测结果可视化、检测过程控制及结果保存等核心能力,可广泛应用于建筑工地、工厂车间等需要强制佩戴安全帽的场景,帮助管理人员实时监控人员安全防护情况。
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,它研究如何让计算机理解、解释和生成人类语言。NLP技术广泛应用于文本分类、情感分析、机器翻译、问答系统、语音识别等场景。随着深度学习的发展,NLP技术取得了显著的进步,能够处理更复杂、更抽象的语言任务。
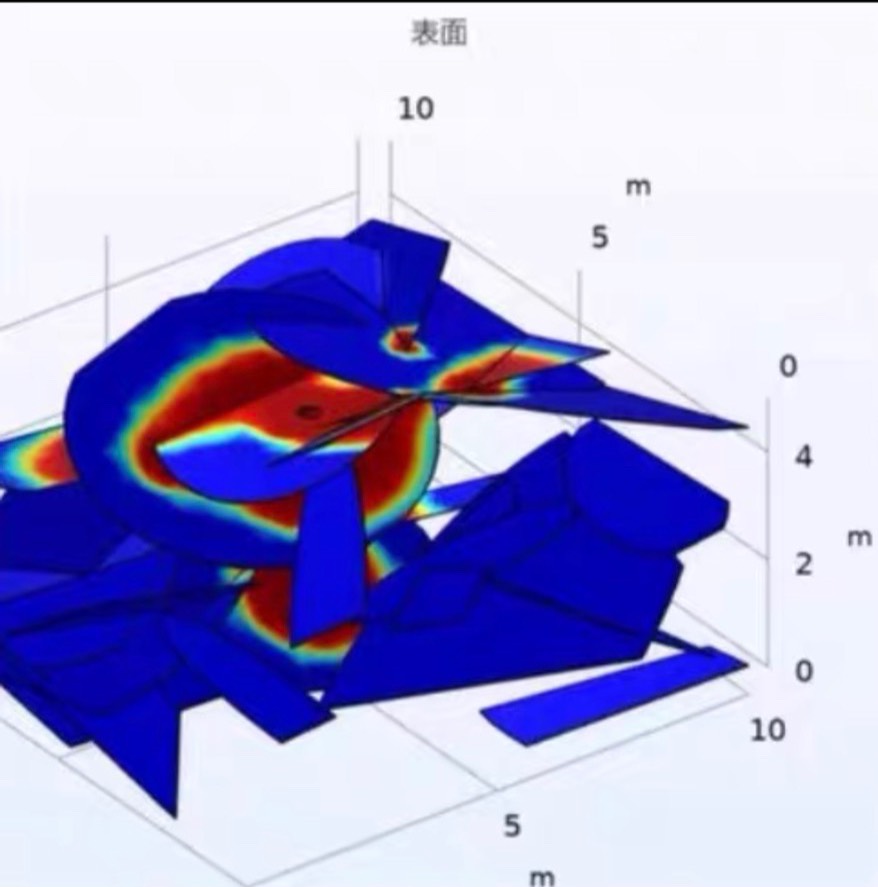
该项目是一个典型的高压输电线静电场仿真,通过参数化扫描模拟三相交流电的电场变化,输出地面电场分布云图、沿线场强曲线和最大场强数据,适用于工程设计和电磁环境评估。Maxwell电场仿真高压输电线地面电场仿真,下图分别为模型电场强度分布云图、各时刻沿地面电场强度分布,地面各点最大场强。
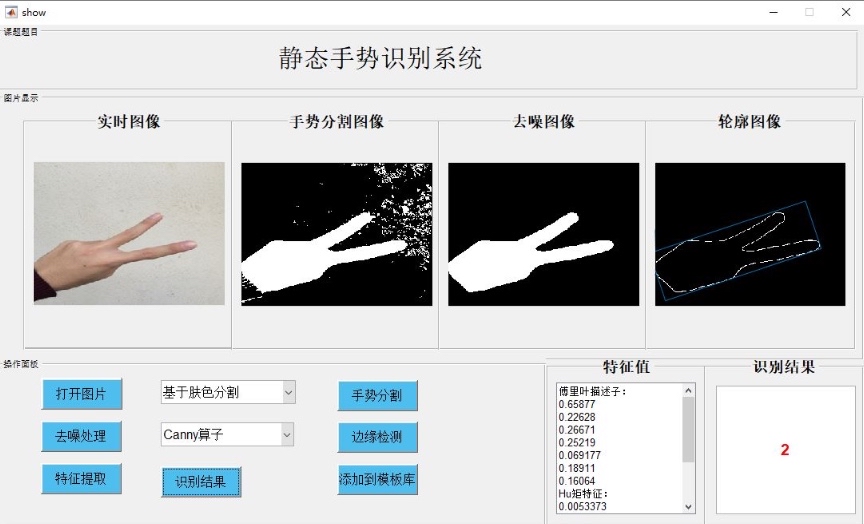
图像输入与预处理:从文件中读取手势图像,并进行预处理(如去噪、归一化等)。图像分割:采用自动阈值分割或肤色分割两种方法对图像进行处理,提取出手势区域。边缘检测:使用Sobel、Prewitt、Roberts、log和Canny五种边缘检测算子,提取图像的边缘特征。特征提取与分类:对提取的特征进行分析,并结合分类算法完成对手势的识别。GUI界面设计:提供用户友好的界面,方便用户选择图像、算法,并实时
持续交付是在CI的基础上,确保软件在任何时候都能以可持续的方式快速、可靠地发布到生产环境。这些反馈数据不仅用于快速发现问题、触发自动回滚,更重要的是,它们被反馈给开发团队,成为下一轮迭代优化的输入,从而形成一个完整的、不断自我完善的闭环系统。在CI确保了代码库的健康状态后,持续交付(Continuous Delivery)和持续部署进一步将自动化流程延伸至发布阶段,二者共同构成了通向生产环境的快速
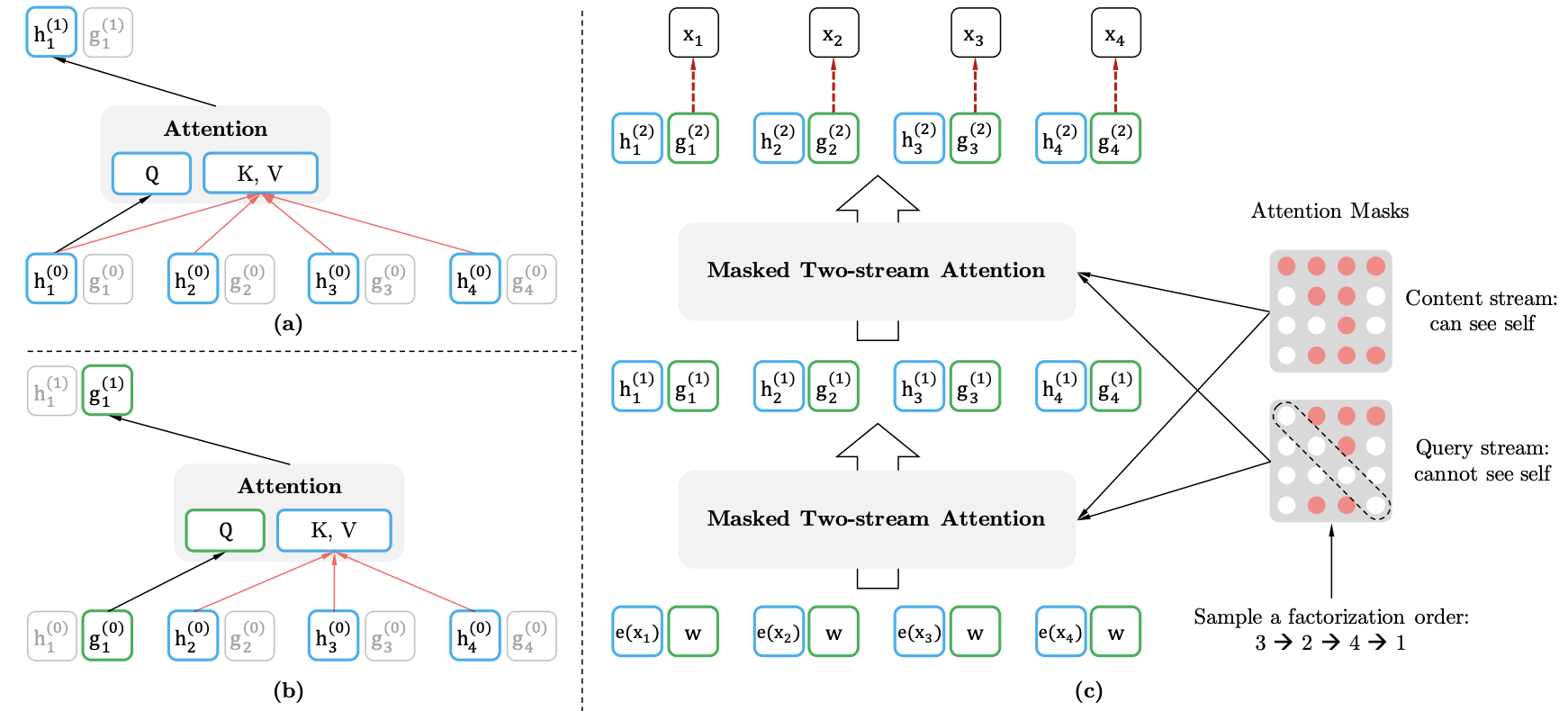
先看第 1 行,因为在新的排列方式中 1 在最后一个,根据从左到右 AR 方式,1 就能看到 234 全部,于是第一行的 234 位置是红色的(没有遮盖掉,会用到),以此类推。具体实现方式是,通过随机取一句话的一种排列,然后将末尾一定量的词给“遮掩”(和 BERT 里的直接替换 “[MASK]” 有些不同)掉,最后用 AR 的方式来按照这种排列依次预测被“遮掩”掉的词。我们可以发现通过随机取排列(
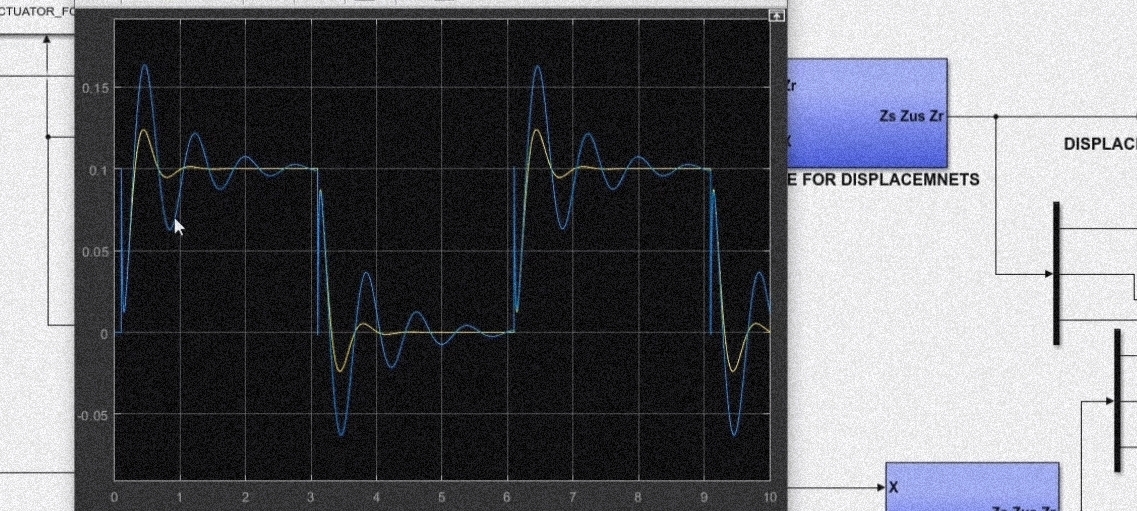
四分之一车辆模型把车辆简化成由车身质量 $ms$ 、非簧载质量 $m{us}$ 、弹簧刚度 $ks$ 、阻尼系数 $cs$ 组成。它忽略了车辆左右和前后方向的运动,只考虑垂直方向的振动,虽然简单但能有效反映悬架主要特性。
最近自然语言处理方面的突破性进展非常之多,以至于笔者做为做为业内人士也必须时刻抬头,紧跟行业最新的发展潮流,才能不被时代抛弃。前一段时间谷歌发布的XLNET在各方面都已经超过了之前的行业标杆BERT,而百度最近发布了ERNIE2.0又是成绩斐然。考虑到ERNIE2.0用到的算力只是XLNET的五分之一左右,可以说百度这次没有走之前优秀模型大算力出奇迹的老路,客观的讲这是百度在AI方面...
COMSOL 三维离散裂隙注浆模型。基于粘度空间衰减的宾汉姆流体注浆。裂隙采用随机分布的圆盘模型,恒压注浆。comsol模拟随机生成裂隙注浆,考虑浆液粘度时变性浆液在多孔介质和裂隙中扩散形态,扩散速度,扩散距离,针对注浆过程中浆液粘度时空分布不均匀的问题,使用基于欧拉框架的流动水中注浆数值计算方法:双流体跟踪法(TFT),模拟速凝浆液(最常见的为C-S浆液)的扩散过程。在COMSOL中通过pde模
每个节点被分配了一个本地的开环最优控制问题,只依赖于邻近节点的信息,在这个问题中,成本函数通过惩罚预测轨迹与假设轨迹之间的误差而设计。每个节点被分配了一个本地的开环最优控制问题,只依赖于邻近节点的信息,在这个问题中,成本函数通过惩罚预测轨迹与假设轨迹之间的误差而设计。除了这种惩罚外,还提出了一种基于等式的终端约束,以确保稳定性,这使得预测时域内每个节点的终端状态等于其邻近状态的平均值。除了这种惩罚
通过基于Simulink的仿真获取数据,再利用Python进行特征提取和机器学习故障诊断,我们在光伏故障诊断领域迈出了坚实的一步。基于SSA - LSTM - DCNN的方法展现出了比传统单一或组合模型更出色的性能。当然,这只是一个阶段性成果,未来我们还可以进一步探索更多优化策略,比如进一步改进特征提取方式,或者尝试结合更多新兴的优化算法和神经网络结构。希望感兴趣的朋友可以一同探讨,共同推进光伏故
通过对电-气-热耦合环节(即燃气发电机和热电联产机组)的分析,建立了以综合能源系统总运行成本和碳排放成本最小为目标函数的电-气-热综合能源系统优化调度模型,并求解该模型得到优化后的多能流。通过对电-气-热耦合环节(即燃气发电机和热电联产机组)的分析,建立了以综合能源系统总运行成本和碳排放成本最小为目标函数的电-气-热综合能源系统优化调度模型,并求解该模型得到优化后的多能流。这个策略基于我们构建的电
XLNet是基于Transformer架构的预训练语言模型,由Google和CMU的研究团队在2019年提出。与BERT等模型相比,XLNet采用了Permutation Language Modeling(PLM)策略,能够更好地处理序列依赖性,从而在多项NLP任务上展现出更优的性能。XLNet的预训练过程不仅考虑了双向上下文,还通过自回归的方式,实现了对序列的灵活建模。
XLNet是一种基于Transformer架构的预训练语言模型,由Google和CMU的研究人员提出。与BERT等模型相比,XLNet在预训练阶段采用了自然语言的顺序性,通过双向Transformer和Permutation Language Modeling(PLM)策略,能够更好地捕捉文本的长期依赖关系和语境信息。情感强度(Sentiment Intensity)是指文本中表达的情感的强烈程度
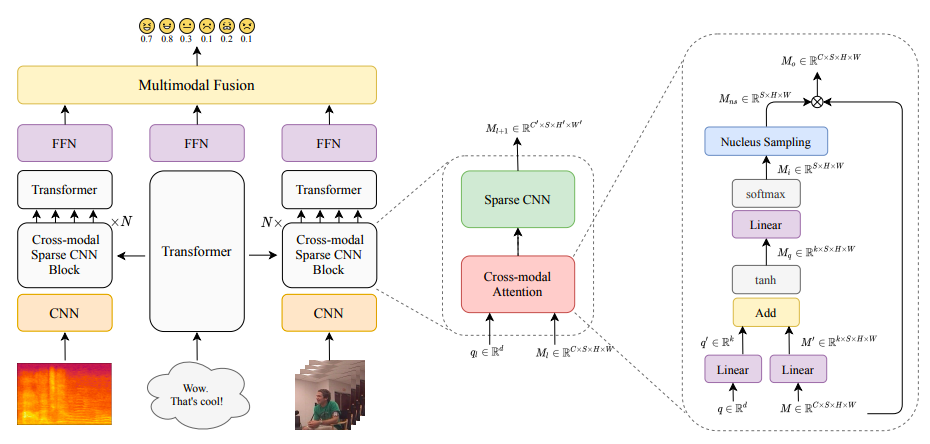
多模态数据指的是包含多种类型信息的数据集,例如文本、图像、音频或视频等。在情感分析领域,多模态数据能够提供更全面的上下文信息,帮助模型更准确地理解情感表达。例如,一段视频中的情感不仅可以通过人物的言语内容(文本模态)来判断,还可以通过人物的表情(视觉模态)和语气(音频模态)来辅助理解。XLNet是一种基于Transformer的预训练语言模型,它通过双向训练和掩码语言建模,能够更好地理解文本的上下
在自然语言处理(NLP)领域,语言模型的发展经历了从基于统计的方法到基于深度学习的模型的转变。2018年,Google的BERT模型通过双向Transformer架构实现了对自然语言的深度理解,极大地推动了NLP技术的进步。然而,BERT在预训练阶段采用的Masked Language Model(MLM)机制,虽然能够处理双向上下文,但其在预测时的条件独立性假设限制了模型的性能。为了解决这一问题
一.Xlnet概述Xlnet,自BERT预训练-微调模式开创以来,这个自然语言处理NLP中的又一重大进展。Xlnet融合了自回归(AR,单向语言模型)、自编码(AE,双向语言模型)等语言模型特征,采用最先进的transformer特征提取器(transformer-xl,利用分割循环机制和相对位置编码进行高并发-超长文本处理),开创性地提出了排列语言模型(Permutation...
1.背景介绍1. 背景介绍自然语言处理(NLP)是人工智能领域的一个重要分支,旨在让计算机理解和生成人类自然语言。在过去的几年里,自然语言处理技术取得了显著的进展,尤其是在语言模型、机器翻译、情感分析等方面。这些成果可以追溯到2017年Google Brain团队提出的Transformer架构,后来被BERT、GPT-2、GPT-3等模型所继承和改进。在2019年,一位来自Googl...
1.背景介绍自然语言处理(NLP)是计算机科学和人工智能的一个分支,旨在让计算机理解和生成人类语言。自然语言处理的一个重要任务是文本分类,即根据文本内容将其分为不同的类别。传统的文本分类方法通常使用手工设计的特征,但这种方法的效果受限于特征的选择和提取。近年来,深度学习技术的发展使得自然语言处理取得了巨大进展。特别是,自注意力机制的出现使得模型能够捕捉到长距离的上下文信息,从而提高了文本分...
从宏观来看,XLNet 实现了站在巨人 BERT 肩膀上的新的突破,将 AR 模型和双向训练有机地结合在一起。从微观来看,XLNet 引入的几个改进方法各有所长:Permutation LM 使得语言模型在训练时可以充分利用上下文的信息;Two-stream encoding 很好地区分了预测目标和非预测目标的 attention 的计算使结果更训练更加合理;
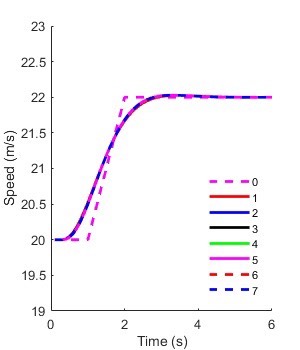
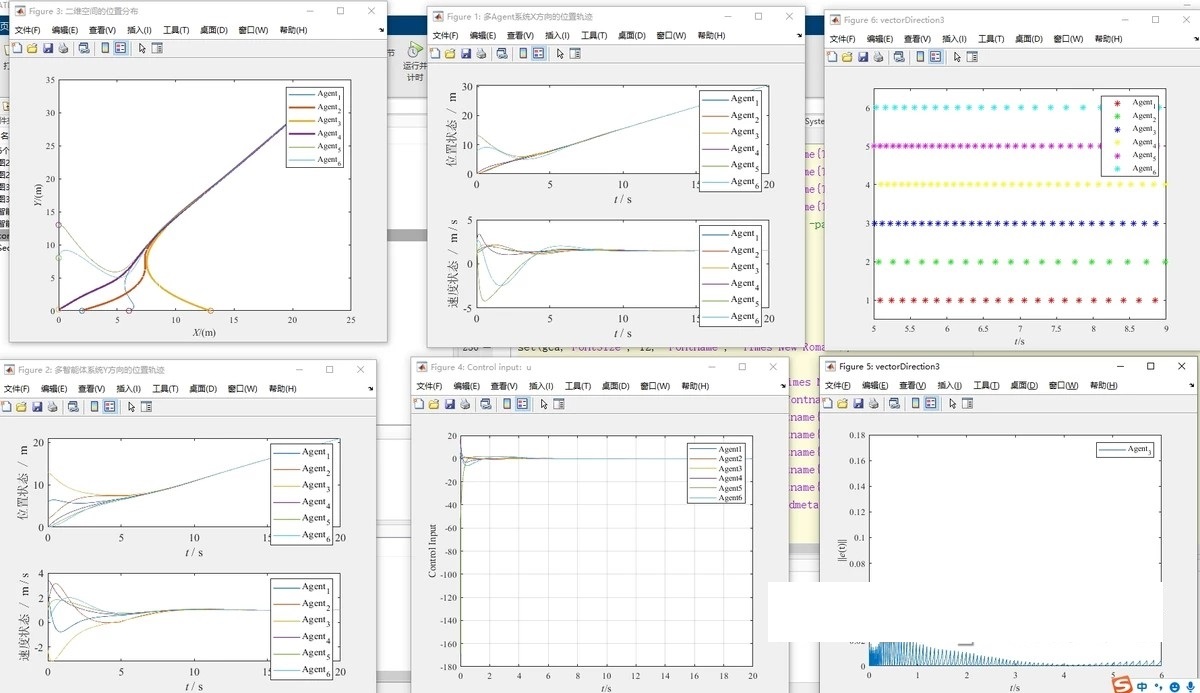
matlab仿真程序,二阶MASs,事件触发机制这段代码是一个带有领导者的二阶多智能体的领导跟随一致性仿真。以下是对代码的分析:1. 代码初始化了系统参数,包括邻接矩阵A、拉普拉斯矩阵L、系统的领导跟随矩阵H等。2. 代码定义了一个二阶系统的微分方程模型,并使用RK4方法解方程。3. 代码使用事件触发机制来控制智能体之间的通信和更新。每个智能体根据自身的位置和速度误差以及邻居智能体的误差信息来决定
在技术选型方面,我们使用了C++17标准,充分利用其现代化的语言特性,如并行算法库、智能指针和标准文件系统库,既保证了代码的简洁性,又确保了程序的跨平台兼容性。通过本项目,不仅验证了C++在高性能计算领域的传统优势,也展示了其在现代数据处理应用中的巨大潜力,为从事系统开发和性能敏感型应用的程序员提供了宝贵的实践经验。面对GB级别的日志文件,传统的内存分配方式会导致频繁的内存分配与释放,成为性能瓶颈
斯坦福问答数据集(SQUAD)是一个阅读理解数据集,通过众包从维基百科中提问,其中每个问题的答案是来自相应阅读段落或问题的一段文本或跨度。 也可能无法回答。 SQUAD2.0在2021年发布,已经吸引了大批顶尖实验室的测试。SQUAD2.0有15万个问题(包括1.1的10万和新的5万)。在回答2.0的问题时候还要确定是不是有答案。 在SQUAD榜单中,目前排名第一的是哈工大和讯飞联合实
Fastai with HuggingFace Transformers 是一个结合了Fastai深度学习库和HuggingFace Transformers库的工具集,旨在简化使用自然语言处理(NLP)中的预训练模型,如BERT、RoBERTa、XLNet、XLM和DistilBERT等。从HuggingFace Transformers中选择适合您任务的预训练模型,并使用Fastai来处理数据
在自然语言处理领域中,序列模型是至关重要的一类模型,但是它们受到了序列长度的限制。在传统的循环神经网络(RNN)模型中,由于梯度消失或梯度爆炸的问题,只能处理较短的序列。为了克服这个问题,Attention机制被引入到了序列模型中,其中Transformer是最著名的例子。但是,即使是Transformer,它也有一个长度限制。由于输入和输出是一次性给出的,因此Transformer不能处理超过固
家庭实验室其实就是一个技术趋势。最近几个月它越来越流行,甚至比 AI 还酷。本质上,它是一个可以在受控环境中做任何事情的平台。举个例子:你有一个看起来很可疑的文件,你很想看看它到底是什么,但它可能是病毒,甚至更糟。但你真的很想知道里面有什么——这时候,家庭实验室就派上用场了。家庭实验室就像是一个虚拟实验室,不过它是在电脑里运行的。你可以在受控平台中几乎做任何事。最棒的是,只要你不惹太大麻烦,就没有
bert/roberta/xlnet/macbert/electra等等tiny、base、small、large、xlarge等等版本,tensorflow和torch版本
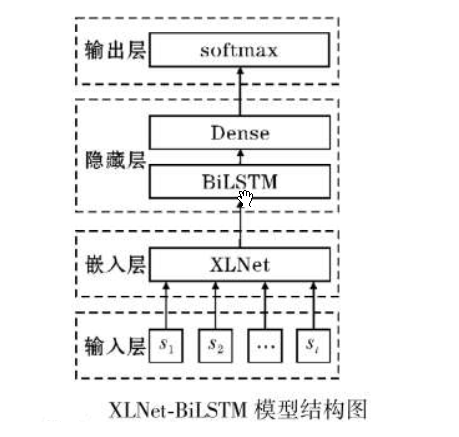
CMU和google brain联手推出了bert的改进版xlnet。在这之前也有很多公司对bert进行了优化,包括百度、清华的知识图谱融合,微软在预训练阶段的多任务学习等等,但是这些优化并没有把bert致命缺点进行改进。xlnet作为bert的升级模型,主要在以下三个方面进行了优化今天我们使用xlnet+BiLSTM实现一个二分类模型。
问题:在Linux中安装NetLogo 我一直在尝试在我的 Ubuntu 设置下安装 NetLogo。我已经下载了最新的 NetLogo 5.3 文件并解压了它们。 我把文件放在/opt/netlogo-5.3.0/目录下。然后我继续从 /usr/bin 目录创建指向 NetLogo 可执行文件的符号链接。 sudo ln -s /opt/netlogo-5.3.0/NetLogo netlogo
问题:符号链接没有扩展$HOME或“~”? 基本思想是我想链接到相对于 $HOME 的路径,而不是显式扩展 $HOME 变量,因为我想确保链接在多台机器上工作,例如, 当我做 ln -s ~/data datalnk 我希望将它定向到具有/home/user的用户$HOME的一台机器上的目录/home/user/data,并在另一台具有/home/machine/user/data的用户$HOME
问题:跟随 SVN 中的符号链接 我有一个 linux 目录(并且不需要任何 windows 结帐): /home/me/projects/project1 在这个项目中,我需要 SVN (1.8.8) 遵循符号链接“link1”: /home/me/projects/project1/link1/<some_directories_and_files> 但是 SVN 不会让我这样做,它只是添加l
Answer a question I have been trying to install NetLogo under my Ubuntu setup. I have downloaded the latest NetLogo 5.3 files and have extracted them. I placed the files in the /opt/netlogo-5.3.0/ dir
Answer a question I have a linux directory (and don't need any windows checkout): /home/me/projects/project1 In this project, I need SVN (1.8.8) to follow a symlink "link1": /home/me/projects/project1
Answer a question I'm new to docker and I'm having problem creating a symbolic link with the following RUN command: FROM php:7.3-apache RUN ["/bin/bash", "-c", "ln -s /app/frontend/web/* /var/www/html
xlnet
——xlnet
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区
 DAMO开发者矩阵
DAMO开发者矩阵

 脑启社区
脑启社区


 AtomGit开源社区
AtomGit开源社区

 腾讯云开发者社区
腾讯云开发者社区

 昇腾开源生态专区
昇腾开源生态专区

 九章云极普惠算力
九章云极普惠算力
 魔乐社区
魔乐社区



 2048 AI社区
2048 AI社区

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区



 AI大模型社区
AI大模型社区



 AI大模型技术社区
AI大模型技术社区
 Ubuntu
Ubuntu

 Linux
Linux
 云原生
云原生
