




- @weixin_43812776
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在VGG中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。那么,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题计算资源的消耗模型容易过拟合梯度消失/梯度爆炸问题的产生问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;问题3通过Batc
在VGG中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。那么,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题计算资源的消耗模型容易过拟合梯度消失/梯度爆炸问题的产生问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;问题3通过Batc
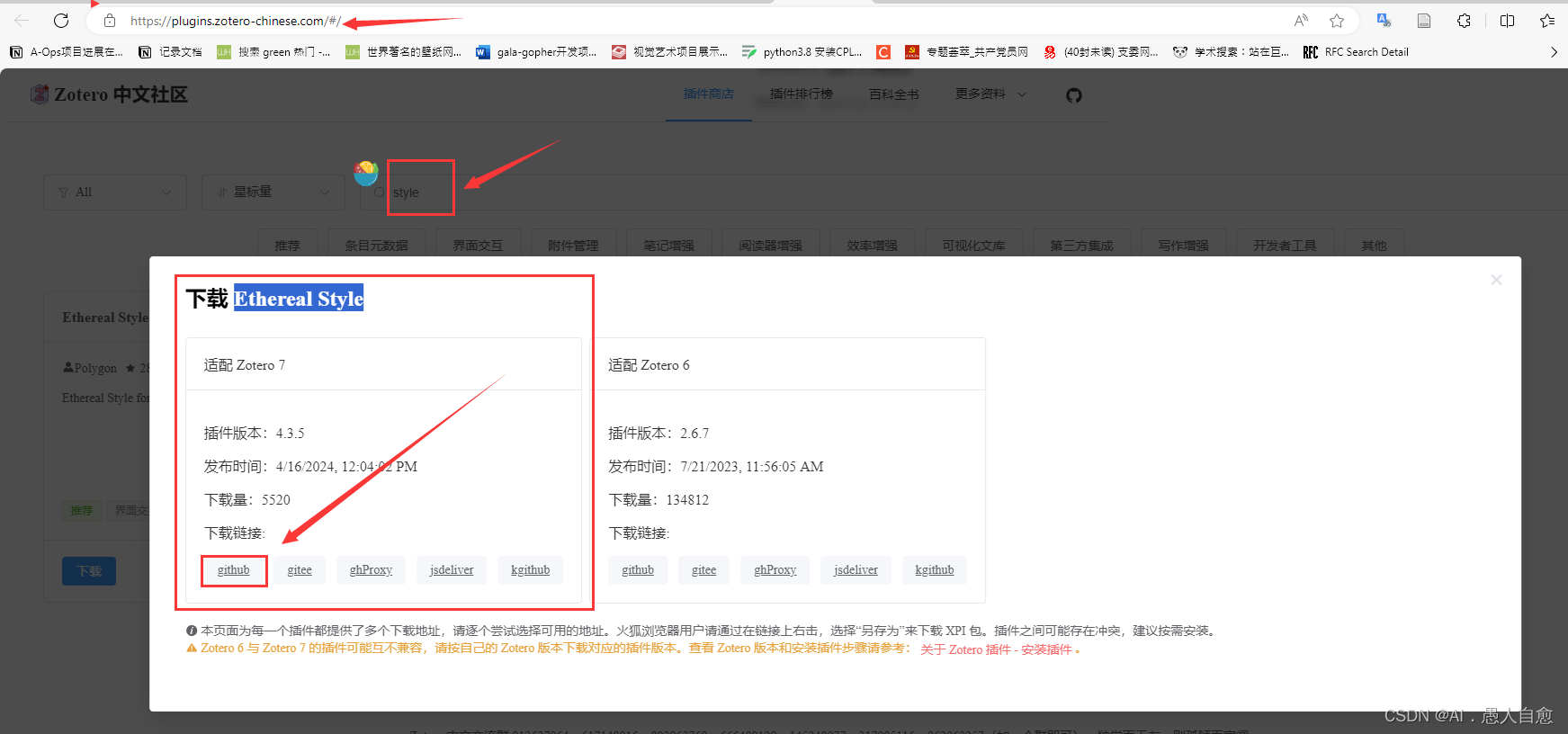
zetore 6 很多成熟的插件在 zetore 7都不能用了。版本回退看起来内置文章的注释会被消除,所以又不想退回去。前几个月在找beta 7 的pdf 护眼色的插件一直没有,今天终于发现了!!!!分享给有需要的小伙伴~
因我本地服务器可以翻墙,但远程服务器不能翻墙,然而内网的代码有需要执行load_dataset()从huggingface上拉数据。因此,想着吧HF上数据库下载传到内网上,然后再load——dataset()都本地内容。根据官网(https://hugging-face.cn/docs/datasets/loading)的描述很简单。

3T(n/2)+n 的递推式主要定理公式求解根据递推式 T(n)=3T(n/2)+n ;可知 a=3,b=2,f(n)=n;计算出来的结果是:log23>1\log_2{3}>1log23>1则有nlog23+c>f(n)n^{log_2{3}+c}>f(n)nlog23+c>f(n),当c=0时。所以符合主定理公式的条件一,所以,T(n)=nlo...
这个栗子解释的是 怎么引用特征值越大包含信息量越多这一特性来 进行降维。问题的引入机器学习中的分类问题,给出178个葡萄酒样本,每个样本含有13个参数,比如酒精度、酸度、镁含量等,这些样本属于3个不同种类的葡萄酒。任务是提取3种葡萄酒的特征,以便下一次给出一个新的葡萄酒样本的时候,能根据已有数据判断出新样本是哪—种葡萄酒。问题详细描述:UCI Machine Learning Repository