




- @rensihui
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2023年,国内外的IT公司大都发布了自己的类ChatGPT语言大模型,有种“百模大战”的味道。至2024.01.01, 收录的有, ChatGPT/Gmini/PaLM/Clude/Ernie/ChatGLM/Qwen/Hunyuan/星火/Minimax/Baichuan
windows下pycharm配置连接远程gitlab,git clone后,可以用pycharm直接操作,而不需要每次都用命令行。最近连接远程gitlab项目这个问题弄得我欲仙欲死。。。总结一下下,以后忘记了也可以看看。1. 首先你要注册gitlab账号,然后下载git,pycharm配置好git(File --> Settings -->g...
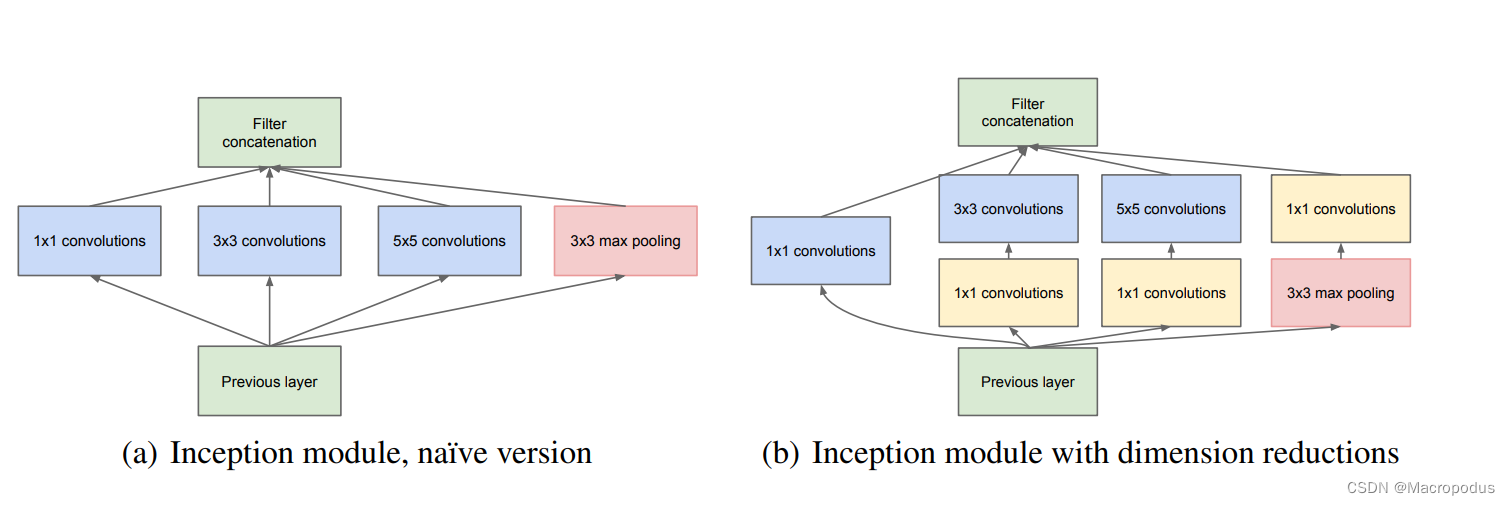
2012-2022是深度学习集中爆发的10年,在这10年间,涌现出许许多多的新技术新理论,尤其是在骨干网络上。ConvNet-1989接近现代卷积神经网络CNN了,它具有两个特征(专利),一个是跨步卷积(strided-convolution),另一个是独立池化层(Pool)。基于该网络架构的系统被用于用于手写邮政编码识别。LenNet-5是一个简单的浅层卷积神经网络,激活函数为sigmoid,其
本文介绍了如何使用Python3通过OpenAI API调用Doubao-Seed-1.6模型,并控制其思考模式(thinking参数)。摘要要点: 通过设置extra_body参数中的"thinking"类型为"disabled"、"enabled"或"auto"来控制模型的思考模式 提供三种调用示例: 纯文本问答
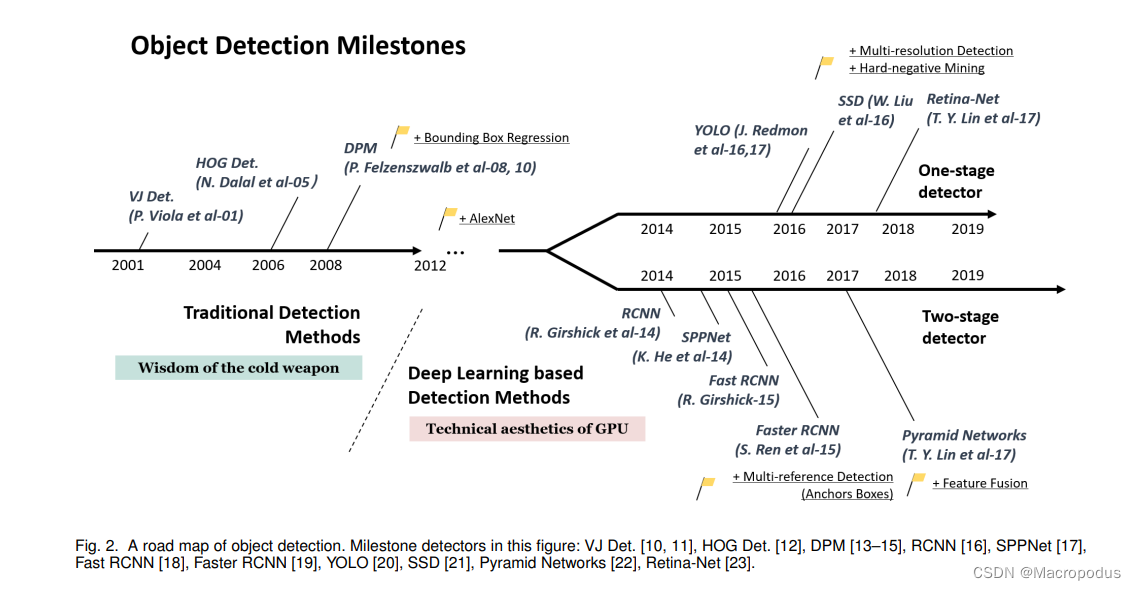
目标检测,也称目标提取,是计算机视觉四大基础任务之一(分类、定位、检测、分割),是一种基于目标几何和统计特征的图像分割。目的是对图像上的预定目标进行分割和识别,通俗来说就是检测图像中有什么,以及在哪里,通常用矩形框圈定目标。传统机器学习时代,目标检测经典算法大都基于滑动窗口、人工特征提取等技术手段,代表算法有VJ检测器、HOG行人检测器和DPM检测器等;深度学习时代大放异彩的卷积神经网络也被引入目
开放信息抽取(OIE)系统(五)-- 第四代开放信息抽取系统(基于深度学习, deeplearning-based, 抽取式&生成式)一.第四代开放信息抽取系统背景第四代开放信息抽取系统的诞生和发展离不开时代的浪潮,首先是深度学习迅猛发展,word-embedding、seq2seq-attention、attention、bert等技术层出不穷;然后就是前人开源出的各种OIE系统,也给数
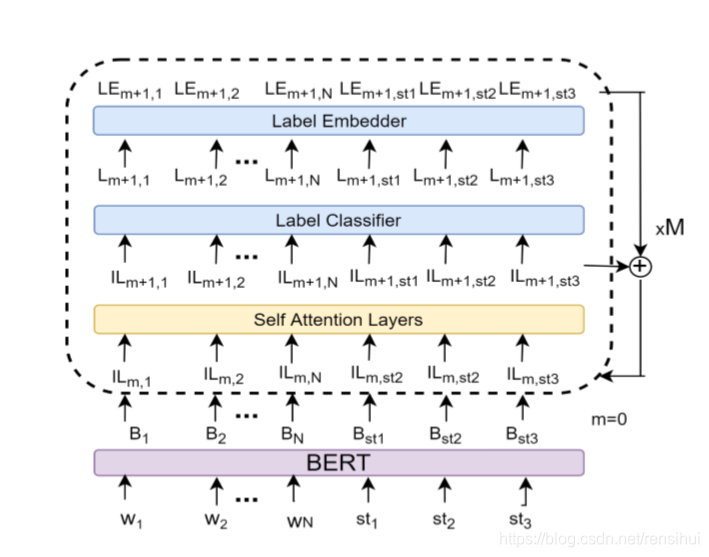
LlaMA3-SFT, Meta-Llama-3-8B/Meta-Llama-3-8B-Instruct微调(transformers)/LORA(peft)/推理。
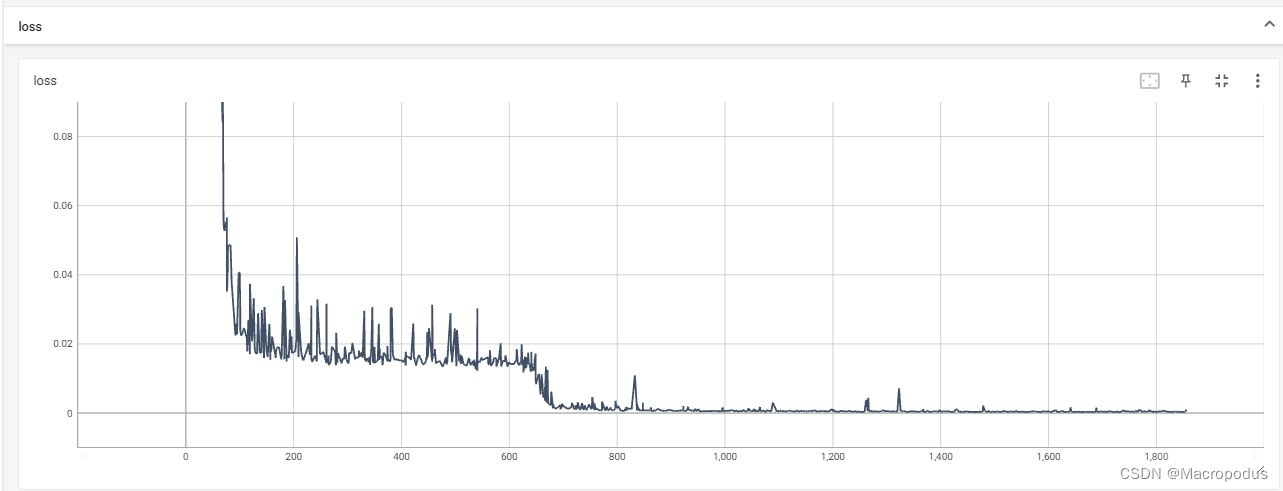
windows下pycharm配置连接远程gitlab,git clone后,可以用pycharm直接操作,而不需要每次都用命令行。最近连接远程gitlab项目这个问题弄得我欲仙欲死。。。总结一下下,以后忘记了也可以看看。1. 首先你要注册gitlab账号,然后下载git,pycharm配置好git(File --> Settings -->g...
NeuralNLP-NeuralClassifier-master1. 所有用超参数用json文件保存2. 训练结束后设置学习率lr=0, 这样就不用设置is_train这个参数了def update_lr(self, optimizer, epoch):if epoch > self.config.train.n...
本文介绍了如何使用Python3通过OpenAI API调用Doubao-Seed-1.6模型,并控制其思考模式(thinking参数)。摘要要点: 通过设置extra_body参数中的"thinking"类型为"disabled"、"enabled"或"auto"来控制模型的思考模式 提供三种调用示例: 纯文本问答