- @m0_47867638
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
将定位和分类结合在目标检测中的复杂性促进了各种方法的蓬勃发展。先前的工作试图改进各种目标检测头(head)的性能,但未能给出一个统一的视角。在本文中,我们提出了一种新颖的动态头框架,通过注意力机制统一目标检测头。通过连贯地在特征层级之间结合多个自注意力机制以实现尺度感知(scale-awareness),在空间位置之间结合以实现空间感知(spatial-awareness),在输出通道内结合以实现

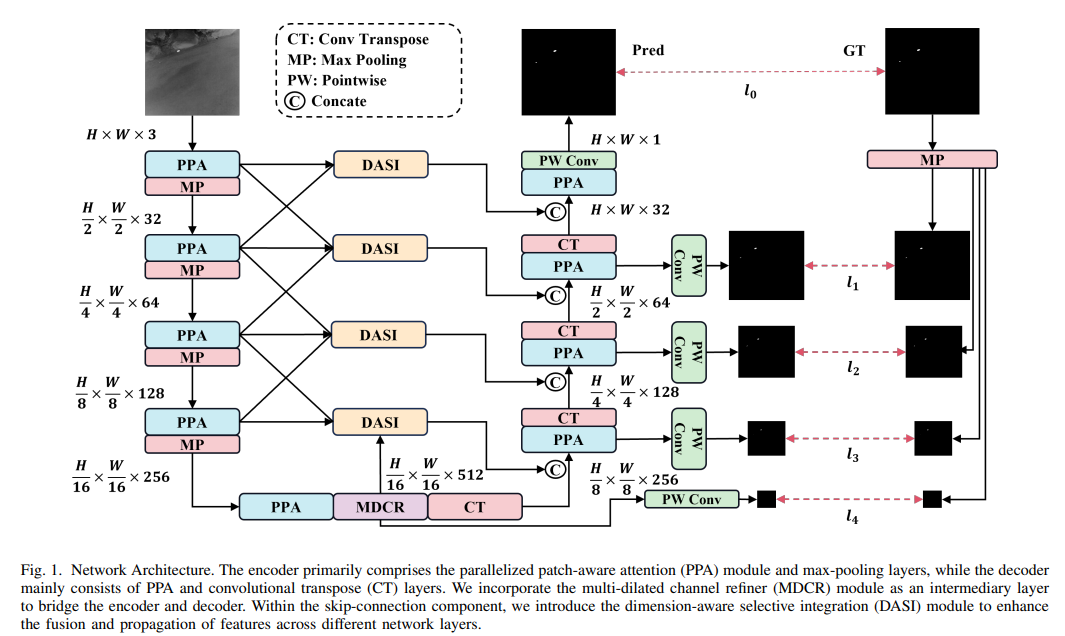
红外小目标检测是一项重要的计算机视觉任务,涉及在红外图像中识别和定位微小物体,这些物体通常仅包含几个像素。然而,由于物体尺寸极小以及红外图像中通常复杂的背景,这项任务面临困难。在本文中,我们提出了一种深度学习方法 HCF-Net,通过多个实用模块显著提高了红外小目标检测的性能。具体来说,它包括并行补丁感知注意力(PPA)模块、维度感知选择性集成(DASI)模块和多空洞通道细化器(MDCR)模块。P
https://arxiv.org/pdf/2407.04620自注意力机制在长文本语境中表现良好,但其复杂度为二次方。现有的循环神经网络(RNN)层具有线性复杂度,但其在长文本语境中的性能受到隐藏状态表达能力的限制。我们提出了一种新的序列建模层类,该类具有线性复杂度和高表达能力的隐藏状态。核心思想是将隐藏状态本身视为一个机器学习模型,而其更新规则则是自监督学习的一个步骤。由于隐藏状态甚至在测试序

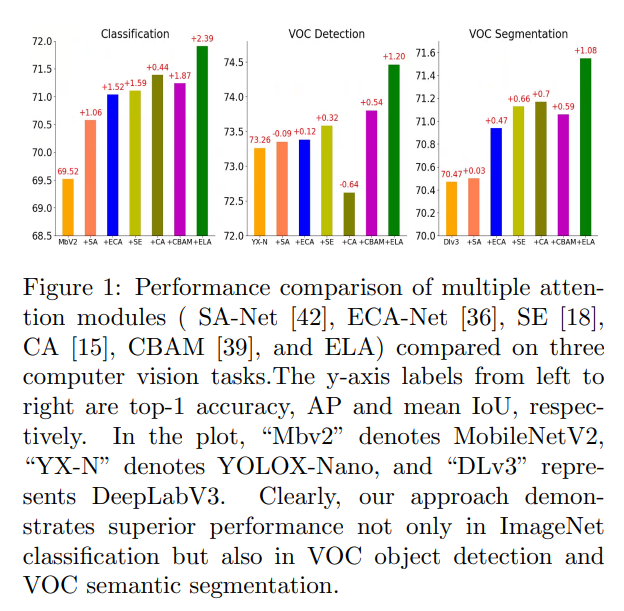
注意力机制由于其能够有效提升深度神经网络性能的能力,在计算机视觉领域获得了广泛认可。然而,现有方法往往难以有效利用空间信息,或者在利用空间信息的同时会牺牲通道维度或增加神经网络的复杂性。为了解决这些局限性,本文提出了一种高效的局部注意力(ELA)方法,该方法以简单的结构实现了显著的性能提升。通过分析坐标注意力方法的局限性,我们发现了批量归一化缺乏泛化能力、维度减少对通道注意力的不利影响以及注意力生
Python 的extend()方法是一个非常有用的工具,它允许你将一个可迭代对象的所有元素添加到列表的末尾。通过上面的示例,你可以看到extend()是如何工作的,以及在使用它时需要注意的一些事项。记住,extend()是直接修改原始列表的,而不是创建一个新的列表。如果你想要将一个可迭代对象的所有元素添加到列表末尾,并且不介意直接修改原始列表,那么extend()或+=是很好的选择。其中,ext

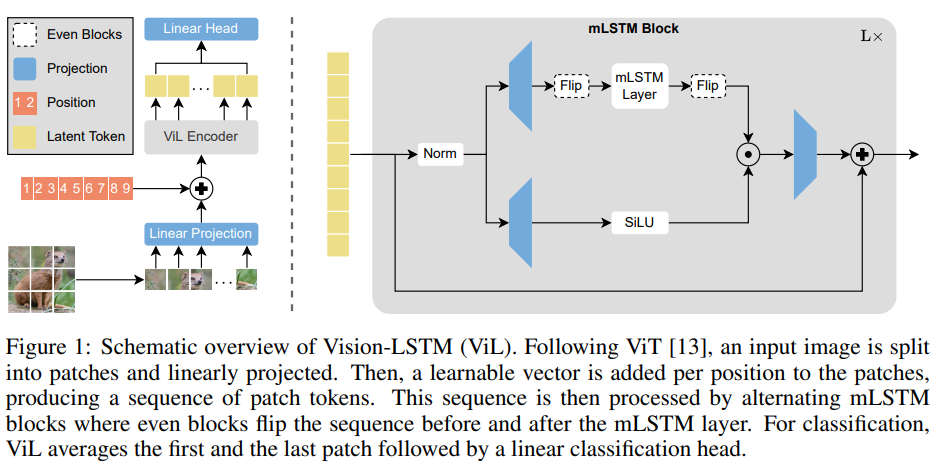
尽管Transformer最初是为自然语言处理引入的,但它现在已经被广泛用作计算机视觉中的通用主干结构。最近,长短期记忆(LSTM)已被扩展为一种可扩展且性能优越的架构——xLSTM,它通过指数门控和可并行化的矩阵内存结构克服了LSTM长期以来存在的限制。在本报告中,我们介绍了Vision-LSTM(ViL),它是将xLSTM构建块应用于计算机视觉的一种适配。ViL由一系列xLSTM块组成,其中奇
注意力机制由于其能够有效提升深度神经网络性能的能力,在计算机视觉领域获得了广泛认可。然而,现有方法往往难以有效利用空间信息,或者在利用空间信息的同时会牺牲通道维度或增加神经网络的复杂性。为了解决这些局限性,本文提出了一种高效的局部注意力(ELA)方法,该方法以简单的结构实现了显著的性能提升。通过分析坐标注意力方法的局限性,我们发现了批量归一化缺乏泛化能力、维度减少对通道注意力的不利影响以及注意力生
作为视觉Transformer的关键组件,自注意力机制可以有效地捕获不同位置之间的关系。给定一个输入x∈RN×dx∈RN×d,如图2(a)所示,其中包含NNN个标记,每个头内部有ddd维嵌入向量。自注意力可以通过相似度函数SimQKexpQK⊤dSimQKexpQK⊤dOSoftmaxQK⊤dVOSoftmaxdQK⊤V。

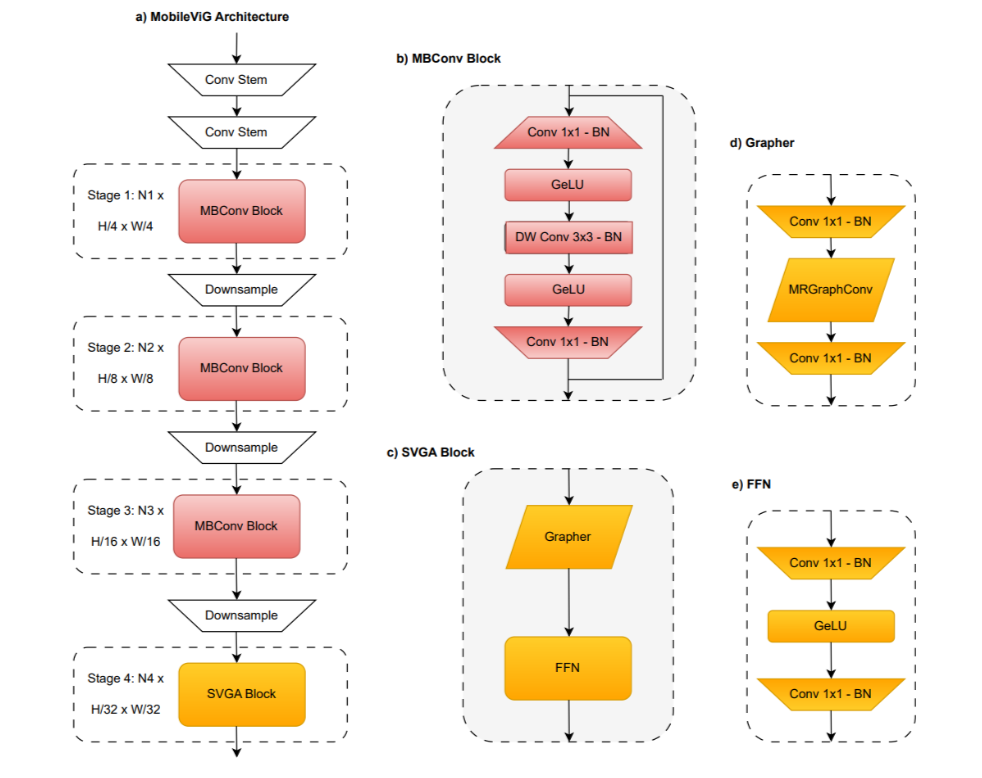
论文翻译:https://blog.csdn.net/m0_47867638/article/details/131860981?官方源码:https://github.com/SLDGroup/MobileViGMobileViG是第一个用于移动设备视觉任务的混合CNN-GNN架构,它使用SVGA。MobileViG在图像分类、目标检测和实例分割任务的准确性和/或速度方面优于现有的ViG模型和现