




- @hhhhhhhhhhwwwwwwwwww
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
黄建超,张凤鸣,朱海波,严涛*江南大学人工智能与计算机科学学院,中国无锡。
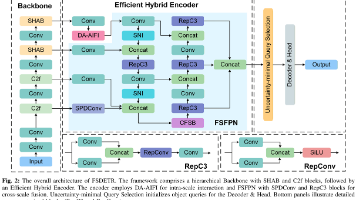
从地空(G2A)视角检测小型无人机(UAV)面临显著挑战,包括极低的像素占用率、杂乱的空中背景以及严格的实时性约束。现有的基于YOLO的检测器主要针对通用目标检测进行优化,往往缺乏对亚像素目标的充分特征分辨率,同时在部署时引入复杂性。本文提出了SDD-YOLO,一种专为G2A反无人机监控定制的小目标检测框架。为捕获微目标至关重要的细粒度空间细节,SDD-YOLO引入了在4×4 \times4×下采
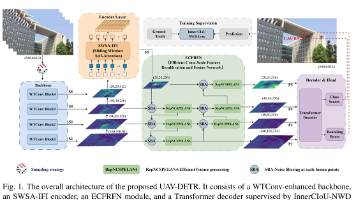
无人机检测在众多安全防护与反无人机应用中具有关键作用。然而,现有基于深度学习的方法通常难以在鲁棒特征表示与计算效率之间取得平衡。当在严重环境干扰下的复杂背景中检测微型无人机时,这一挑战尤为突出。为解决上述问题,我们提出 UAV-DETR,一种将小目标友好型架构与实时检测能力相融合的新型框架。具体而言,UAV-DETR 采用 WTConv 增强的骨干网络与滑动窗口自注意力(SWSA-IFI)编码器,
新泽西理工学院, 美国。

数值格式-> 校准/训练方法-> 量化粒度-> 敏感层策略-> 推理引擎-> 硬件 kernel-> 真实任务评估你的模型瓶颈是权重、激活、KV cache 还是算力?你的目标硬件支持什么低精度 kernel?你的任务能容忍多少质量回退?你的评估集是否覆盖真实长尾输入?量化后是否真的降低 p95 延迟和单位请求成本?一句话收束:好的量化不是把模型压到最低比特,而是在目标硬件上用最小质量代价换到可验

模型剪枝与稀疏推理的关键不是追求一个漂亮的稀疏率,而是把剪枝结果变成目标硬件上真的更小、更快、更省、质量仍然可控的模型。先定部署目标-> 再选剪枝粒度-> 再确认后端支持-> 最后用真实任务和真实硬件验收结构化剪枝适合追求通用部署收益;非结构化剪枝适合高压缩率和有稀疏后端的场景;2:4 半结构化稀疏是硬件友好的折中;LLM 剪枝则必须与量化、蒸馏、KV cache 和推理引擎一起看。真正成熟的剪枝
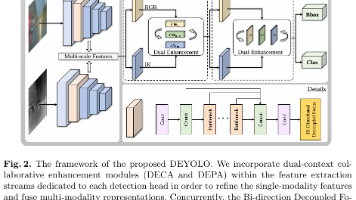
弱光环境下的目标检测是一项具有挑战性的任务,因为物体在 RGB 图像中通常无法清晰可见。由于红外图像提供了补充 RGB 图像的清晰边缘信息,融合 RGB 和红外图像有望增强在弱光环境下的检测能力。然而,现有涉及可见光和红外图像的工作仅关注图像融合,而非目标检测。此外,它们直接融合这两种图像模态,忽略了它们之间的相互干扰。
目标检测是众多无人机(UAV)应用中的基本组成部分,但长期以来一直受到遮挡或目标像素稀缺等障碍的困扰。主动目标检测(AOD)通过主动视觉提供了一种解决这些挑战的新范式,而由于缺乏用于算法开发和评估的高质量数据集和基准,基于无人机的AOD研究仍然很少。为了填补这一空白,本文提出了ATRNet-LUDO,这是第一个用于无人机-地面主动目标检测(UGAOD)的大规模真实世界数据集。它包含121,000张
我们推出了PaddleOCR-VL-1.5,该升级模型在OmniDocBench v1.5上达到了94.5%的最新最高水平(SOTA)准确率。为了严格评估模型对真实世界物理畸变(包括扫描、倾斜、弯曲、屏幕翻拍和光照变化)的鲁棒性,我们提出了Real5-OmniDocBench基准测试。实验结果表明,该增强模型在新构建的基准测试上获得了SOTA性能。此外,我们通过融入印章识别和文本定位任务扩展了模型
命令或 Redis 监控工具(如 RedisInsight)实时观察连接数趋势。(约 21 亿),此时连接数仅受 Redis 服务端限制。:需根据服务器内存和资源情况合理设置,避免 OOM(内存溢出)。即使客户端允许更多连接,仍需确保 Redis 服务端的。:需要精准控制客户端连接数,防止服务端过载或资源浪费。参数,aioredis 默认会将最大连接数设置为。:高并发场景下需要动态扩展连接数,且服
