登录社区云,与社区用户共同成长
邀请您加入社区
本文记录了Hive安装过程中遇到的主要问题及解决方法。首先需要确保MySQL服务正常运行并创建Hive数据库,同时启动HDFS、YARN等核心组件。安装过程中遇到的主要问题包括:Slider工具缺失、MySQL驱动未安装、YARN资源配置警告、Yum源配置错误等。通过查找驱动路径、禁用错误仓库、修改配置文件等步骤逐一解决。最后通过调整WebHCat权限配置并重启服务,成功完成Hive安装。整个流程
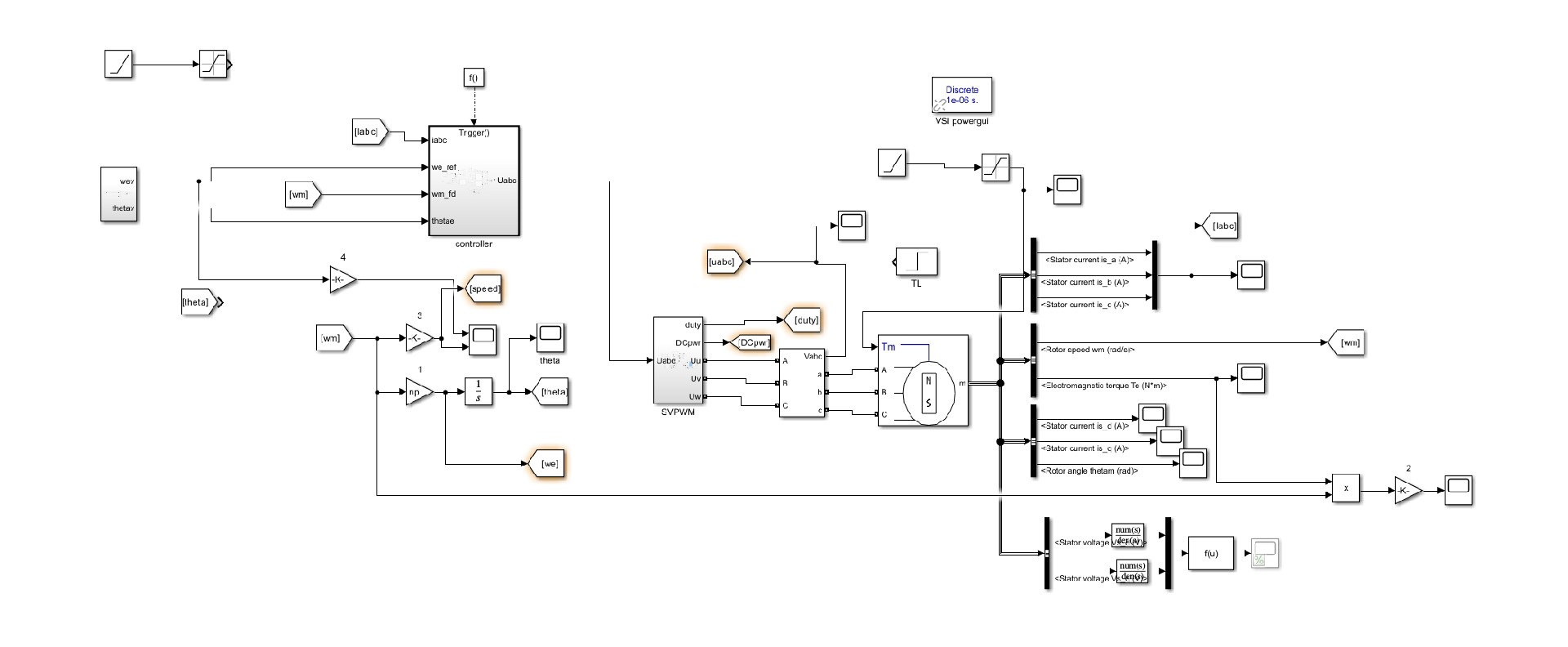
玩过的人都知道,这招最大的好处就是不需要转子位置传感器,启动时先给个固定频率的电流,等电机转起来再切换观测器。最近在搞永磁同步电机控制的朋友应该都听说过IF启动这招,特别是在无传感器场景下,这玩意儿简直像开了物理外挂。今天咱们就扒一扒这个IF控制在Simulink里怎么玩,手把手教你搭模型,顺便聊聊那些参数调起来要命的坑。启动阶段的斜坡函数生成器是灵魂所在,这个模块的斜率决定你的电机是优雅起跑还是
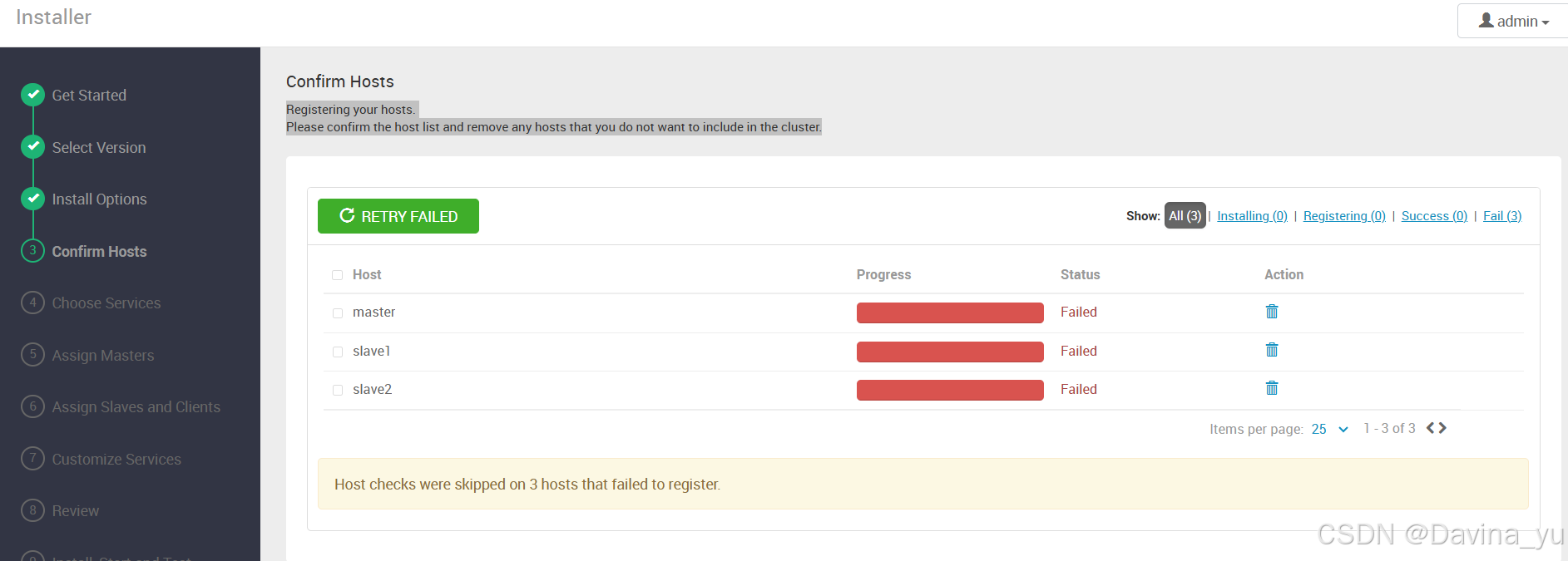
如果返回的是HTTP响应头信息,比如HTTP/1.1 200 OK,则说明Ambari Web界面是可以访问的。中文和英文操作系统版本问题,中文操作系统出错,英文则成功;输入hostname即可知道自己主机的hostname。修改vim /etc/sysconfig/i18n。修改vim /etc/locale.conf。查看hostname是否改成本机的主机名;
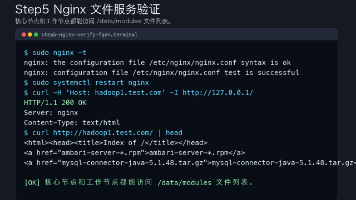
本文介绍了如何配置Nginx作为本地YUM文件服务,为Ambari Plus安装包提供HTTP访问。主要内容包括:在核心节点hadoop1.test.com上安装Nginx;设置/data/modules目录权限;配置Nginx站点文件,限制访问IP范围并启用目录索引;测试并启动Nginx服务;放通防火墙端口;最后通过curl验证服务可用性。文章还提供了常见问题排查表,帮助解决403、404等访问
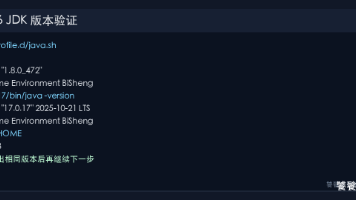
摘要: 本文详细介绍了Ambari Plus环境下JDK双环境的配置方法。建议同时安装JDK8(供Stack和大数据组件使用)和JDK17(供Ambari Server使用),避免版本冲突。针对不同架构(aarch64/x86_64)提供了对应的JDK版本建议及下载命令,包含校验步骤确保包完整性。配置内容包括:创建统一目录、设置软链接、配置默认JAVA_HOME指向JDK8、验证版本等操作步骤。同
本文介绍了Kafka单节点安装的完整流程,重点针对测试环境配置。内容包括:1)在已有ZooKeeper环境下选择Kafka服务;2)将Broker角色分配到hadoop1.test.com主机;3)检查推荐配置,特别提醒生产环境需调整副本数、日志目录等关键参数;4)提交Kerberos管理员凭据完成认证配置;5)验证安装结果和服务状态。教程强调单Broker仅适用于开发测试,生产环境需部署多节点并
本文介绍了在YARN环境下安装Flink的步骤,重点说明在Kerberos安全环境中的注意事项。安装过程包括:1)选择Flink服务并检查YARN依赖;2)分配HistoryServer和Client角色;3)配置关键参数如Kerberos认证、端口和归档目录;4)提交管理员凭据完成安装。特别强调Kerberos principal需与YARN本地用户匹配,否则会导致作业提交失败。安装完成后,可通
本文介绍了在已有HDFS、YARN、Hive等组件的环境中安装Spark的流程。主要内容包括:1)通过Ambari选择Spark服务并验证依赖;2)分配Spark History Server到hadoop1节点;3)在三台主机上部署Spark Client,并在hadoop1配置ThriftServer;4)检查关键配置项如日志目录等;5)提交Kerberos凭据完成安全认证;6)验证安装结果,
Java的强类型系统要求开发团队建立详细的接口文档规范,其静态编译特性天然形成一道类型安全屏障,迫使代码维护人员必须遵循接口约束:当Spring Boot团队维护JDBC驱动时,接口参数的任何微小类型调整都会触发全团队的编译警告。微软研究院提出的QuIC协议,在C#和Python的分布式系统间实现了量子保证的原子事务。C++的显式内存管理迫使协作团队必须建立严格的资源管理契约,采用智能指针和RAI
随手打开尘封的VS2015解决方案,带各位看看当年码农的生存现状(笑)。这个项目虽然现在看槽点满满,但完整实现了增删改查、搜索、导出等基础功能。源码里随处可见的//TODO注释,记录着当年熬夜调试的血泪史。当年没好好用using语句,现在看这个连接池设置成false简直作死。源码里最值钱的是那些被注释掉的错误写法,堪称初级程序员成长实录。想要完整代码的,老规矩——三连后私信(手动狗头)。C#与Sq
摘要: DeepSeek技术方案评审聚焦架构设计、性能优化、安全性等核心维度。当前分层微服务架构具备模块解耦和弹性伸缩优势,但存在同步调用阻塞、状态管理缺失等问题,建议引入异步队列和状态服务。性能方面,动态模型加载和批处理可降低延迟并提升GPU利用率。安全需强化数据加密与模型防投毒机制。成本优化建议弹性资源调度和存储分层,预计节省57%存储开支。改进优先级:短期实现异步化与加密,中期完善监控与契约
本文探讨了利用DeepSeek大型语言模型从电子病历(EMR)生成结构化诊疗建议模板的技术方案。针对传统自由文本EMR存在的结构化程度低、信息提取困难等问题,研究提出了基于DeepSeek的多步骤处理流程:包括数据预处理、关键信息提取、诊疗逻辑推理、结构化模板生成和医生审核确认。该方案能显著提升临床工作效率,促进诊疗规范化,同时面临医学知识准确性、临床推理个性化、数据隐私保护等挑战。应用场景涵盖门
本文介绍了Sqoop的安装过程。Sqoop是用于关系型数据库与Hadoop生态间数据导入导出的工具,属于客户端组件,无需常驻服务进程。安装时需注意:1)建议在Hive之后安装;2)只需分配Client角色到目标主机;3)确保Hadoop/Hive环境及JDBC驱动配置正确。安装完成后通过sqoop version验证,状态显示"已安装"即为成功。Sqoop安装是后续HBase等组件的基础准备步骤。
本文详细介绍了Hive的安装配置过程,重点内容包括:1) 使用外部MySQL/MariaDB作为Metastore数据库,并创建专用账号;2) 在三节点集群中合理分配Hive服务角色(Metastore、HiveServer2、WebHCat);3) 全节点部署客户端组件;4) 配置数据库连接参数并进行验证;5) 安装后的服务状态检查。文中强调了生产环境需使用强密码,并提供了安装顺序建议和常见问题
前言:在泰国,一个全新的应用程序允许查看MySQL、PostgreSQL、Oracle和Sqlite的数据。受Beeswax应用程序的启发,它允许您查询关系数据库并在表中查看它。在hue的hue.ini配置文件中添加mysql,定位到databases位置根据服务器上需要查看的数据库的信息更改响应配置。简单配置如下:#########################################
简单来说,Ambari 是一个用于管理 Hadoop 集群的工具。如果把 Hadoop 集群看成一栋拥有很多房间的大别墅,那么:Hadoop 集群 = 别墅各种服务(HDFS、YARN、HBase) = 房间里的设备Ambari = 装修队长以前如果要部署 Hadoop 集群,需要登录每一台服务器安装软件、修改配置文件、启动服务。服务器数量少还好,如果有几十台甚至上百台服务器,那么工作量会非常大。
CNN(卷积神经网络):擅长捕捉数据中的局部特征。就拿图像数据来说,CNN的卷积层能通过卷积核在图像上滑动,提取诸如边缘、纹理等局部信息。在咱们的数据回归预测里,它同样能挖掘多变量数据中的局部模式。% 构建简单的CNN层layers = [这段代码构建了一个简单的CNN层结构,定义了卷积核大小为3x3,输出16个特征图,Padding设为same保证卷积后尺寸不变,reluLayer添加激活函数,
智慧物业多端全开源,支持二开一、项目架构技术说明基于SpringCloud微服务、分布式架构,更易扩展;项目前后端分离,后端使用JAVA,前端VUE,Uni-app框架;MySQL、Redis多种数据存储方式,只为更快;ActiveMq订阅消息队列,让订单更快流转。二、项目应用多端管理系统后端,小区管理系统前端,小区管理系统业主手机版、小区管理系统物业手机版,适用小程序,对接公众号。三、项目系统构
本文详细介绍了Ambari平台元数据库及server服务迁移的全过程,同时提供了完整的配置修改命令和注意事项,为Ambari平台数据库迁移提供了标准化操作指南。
想不想快速拥有大数据环境?如何才能一键安装?傻瓜式引导?这里就有你想要的,我们可以使用hortonworks出品的sandbox-hdp来搭建,它是建立在docker环境之上的集群,很轻易的主可以把环境搭建起来。使用方法这里我会使用HDP的最新版本3.0.1作为演示,包含的组件版本如下组件版本HDFS3.1.1YARN3.1.1MapReduce2...
本文以图文并茂的方式,旨在说明如何在自己的虚拟机上搭建hadoop集群环境,由于环境不同仅供大家参考!一、机器环境详细说明:虚拟机:VirtualBox5.1.28linux系统:centos6.9jdk:Java HotSpot(TM) 64-Bit 1.8.0_152数据库:MySQL5.1ambari:ambari2.5.0.3hdp:hdp2.5.3节点数:...
ambari离线安装以及hadoop集群搭建详细过程
简介:在两台服务器(一台为ubuntu14.04,另一台为redhat 6)上通过ambari搭建hadoop环境,并启用spark。 打算将ubuntu作为server,redhat 6作为client。1. 实现两台服务器的互相无密登陆ubuntu的ip为10.20.31.202,主机名(hostname)为server204,全限定域名FQDN为server204red
http://www.toxingwang.com/hadoop/hadoop-hadoop/2510.html
然后,点击【新增】,选择从管理端备份到客户端,还是从客户端备份到管理端,默认是从管理端备份到客户端,选择当前的备份路径、传输地址、线程、传输密码等等,以及设置备份时间。第三步,在另一个设备上打开客户端,同样地,点【新增】,把管理端的传输地址、传输密码,复制粘贴到客户端的传输地址、传输密码这里。第四步,设置储存路径,就是备份的放到那里,然后选择备份几次,可按需选择,注意要根据磁盘大小去设置,最后点击
Ambari集成Spark3教程引言作为一名经验丰富的开发者,我将为你提供关于如何在Ambari中集成Spark3的详细步骤。Ambari是一个用于管理、监控和配置Hadoop集群的工具,而Spark3是用于大数据处理和分析的强大工具。通过本教程,你将学会如何将Spark3集成到Ambari中,使其更加强大和灵活。整...
对于使用PySpark处理普通数据和做大数据分析的两种情景的两种不同的环境搭建的详细步骤,保姆级教学
文章目录Ambari-2.7.5.0 + HDP-3.1.5.0网盘地址Ambari-2.7.5.0 + HDP-3.1.5.0网盘地址如果过期,请留言,我会及时更新链接...
02月26日 使用ambari搭建spark连接外置hive.note目标使用amabri 搭建hive 和spark后,hive建立外部表,使用sparksql连接hive元数据(mysql)。步骤1、先将安装好的spark conf目录下生成的hive-site.xml重命名备份(其实用不到)[root@mycentos703 conf]# cd /usr/hdp/3.1.0.0-78/spa
现象:Ambari 安装了 Spark 和 hive ,但集成未成功。spark sql创建的表hive看不到,hive创建的表 spark看不到解决:登录 Ambari 界面,到 Spark 组件修改配置。1)Advanced spark2-defaults 的 spark.sql.warehouse.dir 值/apps/spark/warehouse 改为 /warehouse/tables
一、前言很多小伙伴也都知道,最近一直在做 Ambari 集成自定义服务的教学笔记和视频。之前在准备 Ambari 环境的时候,考虑到有朋友会在 Ambari 安装部署时遇到问题,所以贴心的我呢,就在搭建 Ambari 环境的时候,把这个视频录制好了,总共时长共 87 分钟,将近1个半小时,附带移除 SmartSense 服务及 FAQ 。也提前介绍一下搭建好的 Ambari 相关版本信息:...
Ansys maxwell 变压器学习资料1.全部基础功能的操作教学以及模型文件包含静态场,涡流场,瞬态场,静电场等。2. 以正激变压器及平面pcb变压器为例,对变压器进行参数设计,结构设计,电性仿真,并带模型文件。3.Maxwell和Simplorer联合仿真——移相全桥变换器中开关变压器的仿真。
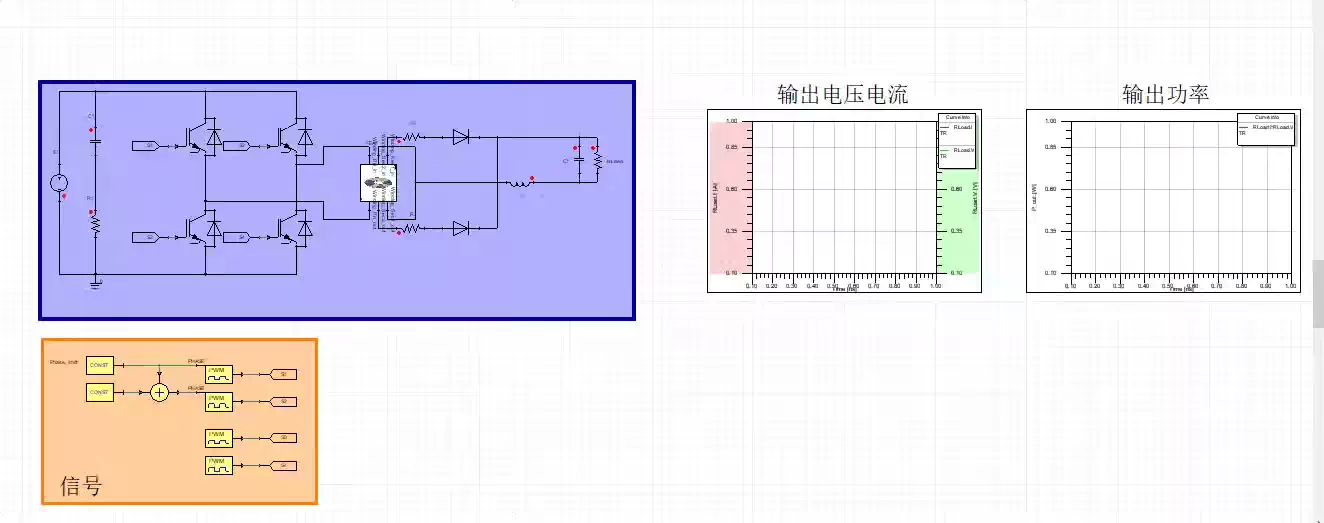
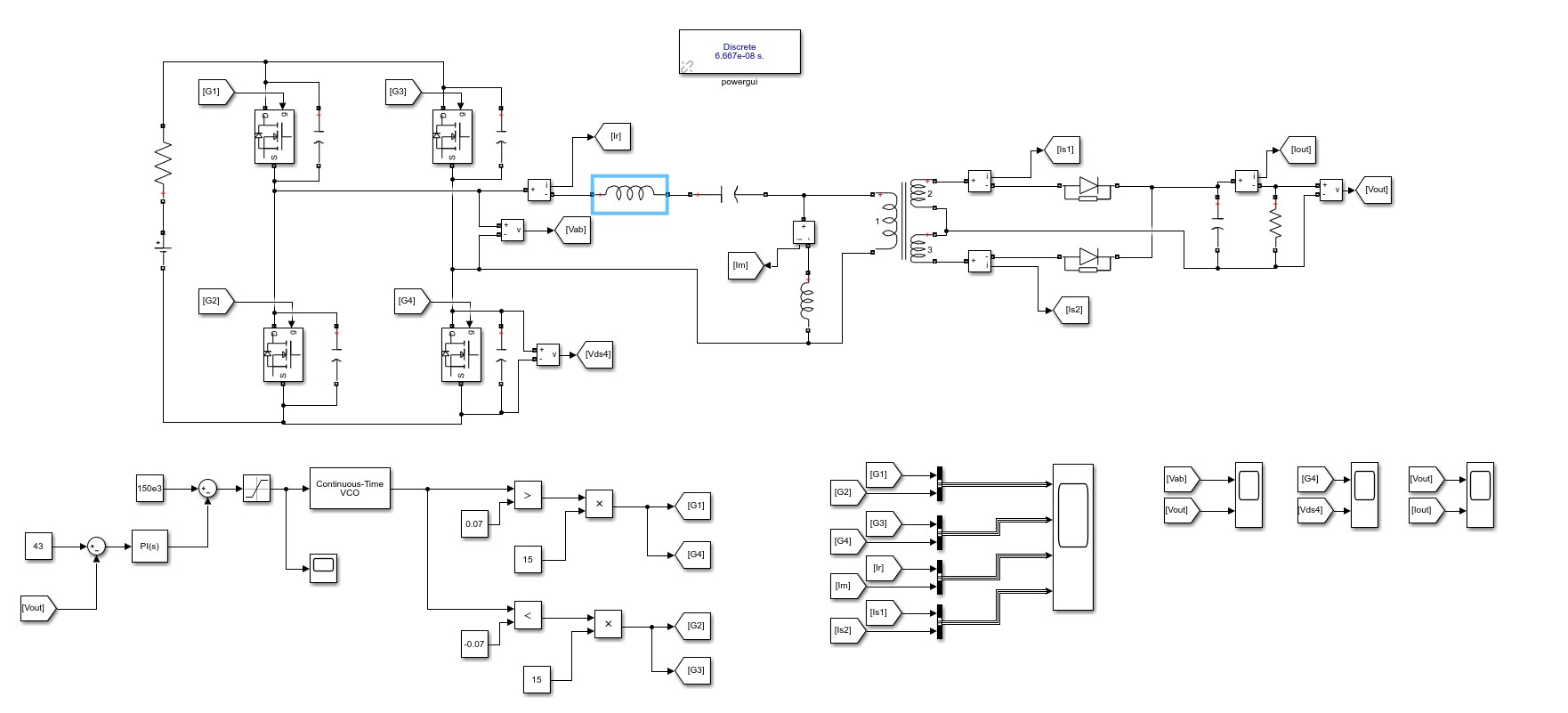
PFC-LLC谐振开关电源设计方案整套学习资料程序+仿真+硬件软件说明报告+原理图+计算书等等注:该方案性价比很高,一套资料下来可以自己做个实物验证,要想看细节可以咨询我,我给你看资料的详细展示视频01.电路原理图:使用AD绘制,附带BOM表02.基于DSP28034编写的程序:PFC和LLC闭环程序,注释非常详细03.仿真模型:从开环到闭环的仿真都有,参数都是设计出来的,仿真验证04.硬件计算书
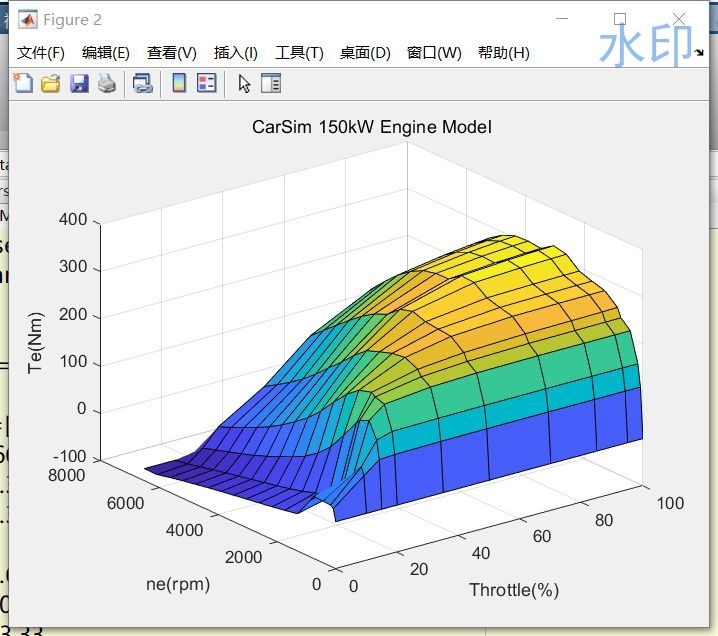
发动机逆模型 逆发动机模型根据发动机模型MAP图数据,得到发动机逆模型以carsim 150kw的发动机为例逆纵向动力学模型 逆发动机模型 自适应巡航 ACC红色*是原始数据点线性插值在汽车工程的奇妙世界里,发动机逆模型是一个极具魅力且实用的领域。今天咱们就以 carsim 中 150kw 的发动机为例,唠唠这发动机逆模型是咋回事儿,以及它和逆纵向动力学模型、自适应巡航(ACC)之间千丝万缕的联系
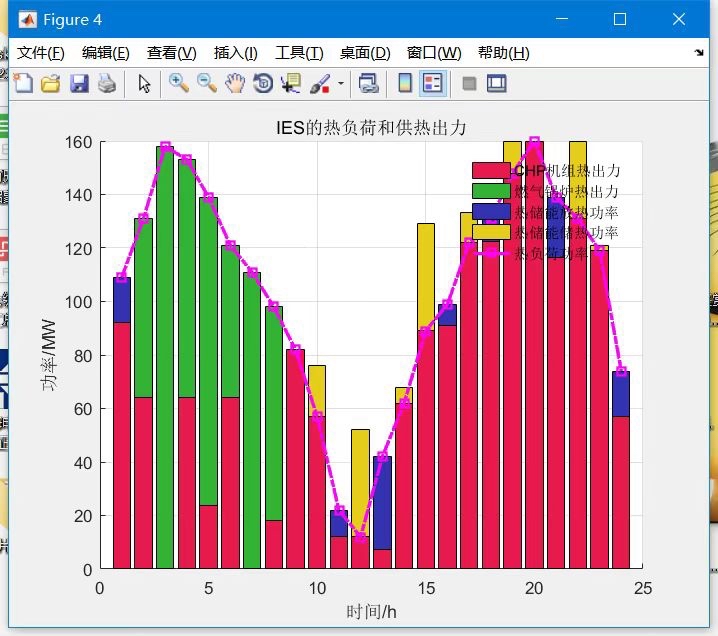
本文介绍一套面向“双碳”目标的综合能源系统(Integrated Energy System, IES)低碳经济调度模型,其核心创新在于将电转气(Power-to-Gas, P2G)与碳捕集与封存(Carbon Capture and Storage, CCS)技术深度耦合,并引入阶梯式碳交易成本机制,以实现系统在满足电、热负荷需求的同时,兼顾运行经济性与碳排放控制。该系统基于 MATLAB 平台
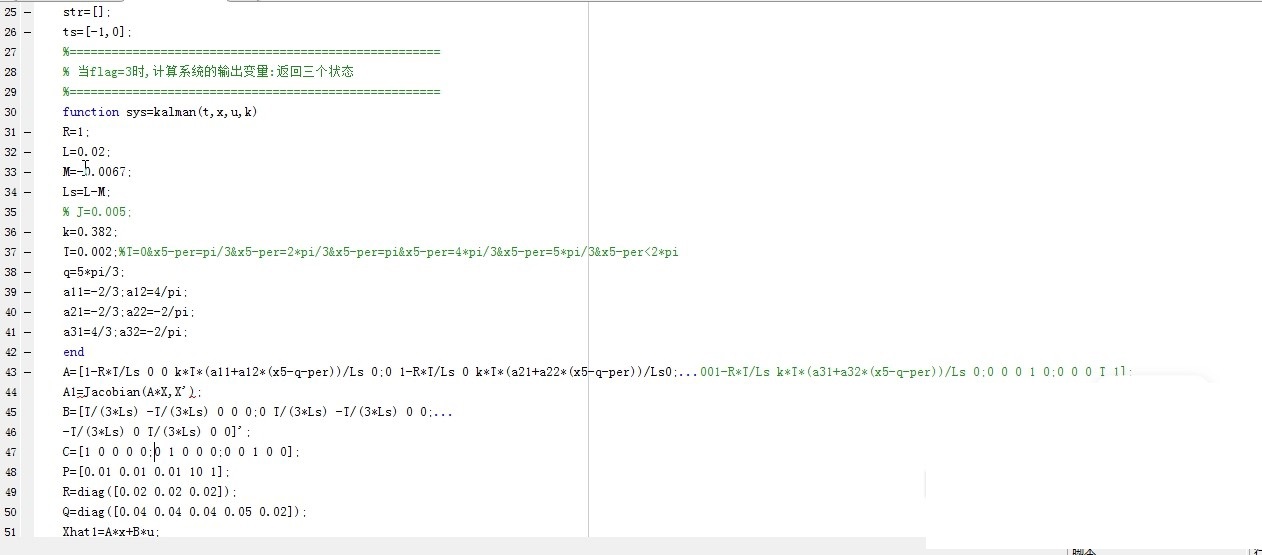
EKF扩展卡尔曼滤波算法做电池SOC估计,在Simulink环境下对电池进行建模,包括:1.电池模型2.电池容量校正与温度补偿3.电流效率采用m脚本编写EKF扩展卡尔曼滤波算法,在Simulink模型运行时调用m脚本计算SOC,通过仿真结果可以看出,估算的精度很高,最大误差小于0.4%在电池管理系统(BMS)中,准确估计电池的荷电状态(SOC)至关重要。本文将介绍如何利用EKF扩展卡尔曼滤波算法在
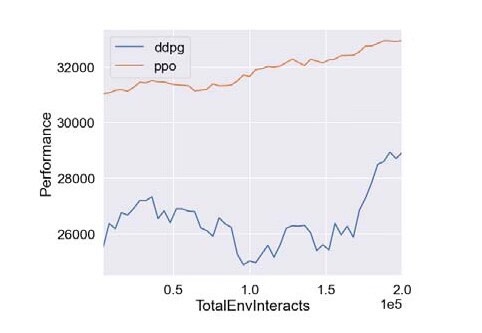
基于深度强化学习的微网P2P能源研究摘要:代码主要做的是基于深度强化学习的微网P2P能源研究,具体为采用PPO算法以及DDPG算法对P2P能源模型进行仿真验证,代码对应的是三篇文献,内容分别为基于深度强化学习微网控制研究,多种深度强化学习优化效果对比,以及微网实施P2P经济效益评估复现结果非常良好,结果图展示如下:基于深度强化学习的微网P2P能源交易研究一、项目定位----------
新手不用找专业标注工具,直接用MATLAB自带的roipoly或者更简单的ginput,先选几个黄化点,几个健康绿点,几个背景点,然后用区域生长?今天搞点接地气的:拿基于MATLAB的这套“组合拳”处理点树叶黄化照片,新手友好但也能练全给定的模块——别小看这些看起来老套的算法,小场景下组合好了比瞎跑大模型省资源还快得多,比如我刚才随便调调,番茄树黄化叶的分割正确率(指黄化区域和真实标注的IOU或者
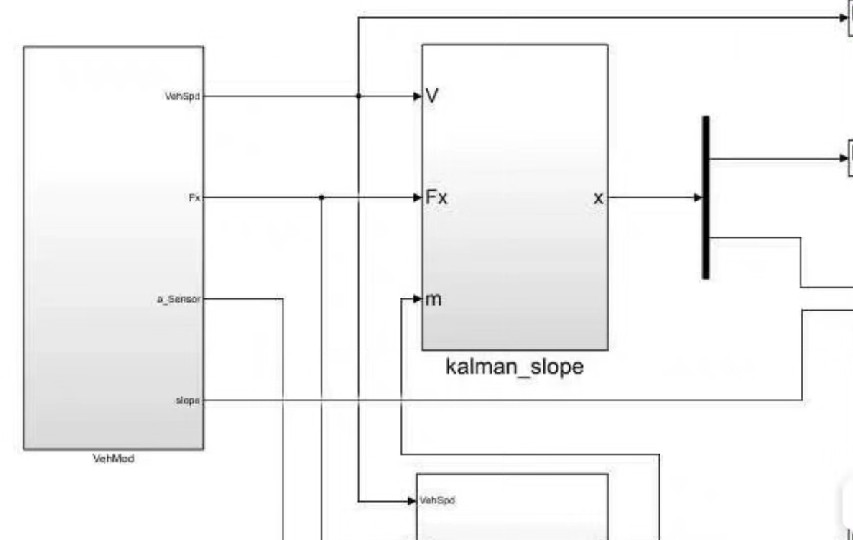
先说说最带劲的部分——那个动态加权的预处理,工程师们居然想到用角速度来修正加速度计的误差,这操作就像给喝醉的传感器醒酒。有意思的是模型里没按套路用常规平均,而是搞了个动态窗口——车速变化率越大,窗口缩得越小,这招对付急加速时的信号毛刺效果拔群。项目组在路试时发现,同样的坡度,不同车辆的加速度计输出能差3%。一、信号预处理,包括对惯性传感器获得的原始加速度信号的低通滤波和从CAN线获得的车速信号的差
ambari
——ambari
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 AI Agent技术社区
AI Agent技术社区




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵
 openEuler 社区
openEuler 社区
 脑启社区
脑启社区
 腾讯云开发者社区
腾讯云开发者社区











 AtomGit开源社区
AtomGit开源社区