




- @m0_64365896
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
FLUX.1 文本到图像模型套件,它在图像细节、及时性、风格多样性和场景复杂性方面为文本到图像合成定义了新的先进技术。为了在易用性和模型功能之间取得平衡,FLUX.1 有三个版本:FLUX.1 [pro]、FLUX.1 [dev] 和 FLUX.1 [schnell]:FLUX.1 [pro]:FLUX.1 的精华,提供最先进的图像生成性能,具有顶级的提示跟踪、视觉质量、图像细节和输出多样性。请在

那么有哪些口碑比较高的文本转图片的AI绘图软件呢?本文将跟大家分享一波出图效果相当不错的人工智能绘画工具网站,让大家实现“绘画自由”。**简介:**这是一款最早流行起来的AI绘图工具,直接在谷歌云端运行的程序,对电脑配置没有要求,用浏览器就可以操作。仅仅通过文字输入,就能让AI产生相应的输出相应的图片。功能强大,图像生成前需要设置参数,更为灵活。虽然出图比较慢不过图片质量效果惊艳。Disco Di

一套精良的开源工具箱,是安全工程师对抗数字威胁的底气所在。

在当今数字化时代,人工智能(AI)正逐渐渗透到各个领域,为我们的生活和工作带来了革命性的变化。其中,绘画领域也不例外。借助强大的 AI 绘画工具,我们可以在电商设计中探索全新的可能性。无论是为产品添加独特的视觉效果,还是为品牌塑造独特的形象,AI 绘画工具都为电商设计带来了创新的元素。本教程将深入探讨如何将 AI 绘画工具融入电商设计中,为看官们呈现一个全新的创作体验。在以往的文章中,我都是使用

鸿蒙开发正当时,现在入手正是好时机。还在犹豫不决的朋友们,小编在这里建议大家早点入手!在这里分享一份鸿蒙学习路线图帮助那些不知道怎么入门的朋友,另外一些鸿蒙开发的资料文档也顺便分享给大家,扫下方二维码就能免费送呢!1、UI开发(ArkTS声明式开发范式)概述2、开发布局3、添加组件4、显示图片5、使用动画6、支持交互事件7、性能提升的推荐方法设置深色模式上传文件在新窗口中打开页面管理位置权限并发概

目前的就业前景正变得越来越广阔,人才需求也越来越大,甚至有很多转行鸿蒙工程师的,薪资那也是相当可观的。根据智联招聘的数据,鸿蒙开发岗位的需求数同比增长了,是前一年同期的倍。这一显著增长表明,随着鸿蒙操作系统的发展和成熟,市场对鸿蒙开发人才的需求正在迅速扩大。由于鸿蒙开发者供不应求,薪资水平也在逐步提升。2024年春招市场中,软件和互联网大厂成为招聘鸿蒙人才的主力,鸿蒙开发岗位的平均月薪超过万元人民

马上就要金三银四了,再不学习鸿蒙就晚了

去年九月,华为正式对外宣告鸿蒙原生应用生态建设全面加速,旗下基于开源鸿蒙技术研发的,与广大消费者见面。值得关注的是,该版本操作系统将摒弃传统安卓AOSP代码,实现底层技术的全自主研发。这一转变象征着鸿蒙星河版将不再直接兼容安卓应用。截至2024年初,鸿蒙生态已强势覆盖逾台设备,涵盖等日常生活中不可或缺的智能终端。众多知名企业与机构纷纷响应,其中包括等在内的超级应用均已启动鸿蒙原生应用的开发计划。鸿

感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,
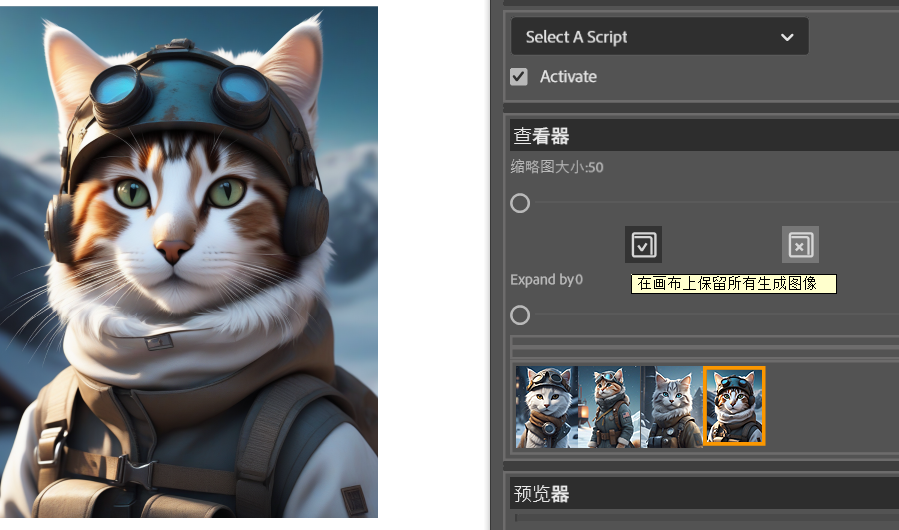
本教程专为初学者设计,详细介绍了 2025 年最新版的SD ComfyUI的使用方法。通过逐步指导,让你无需任何基础,快速学会并使用这一强大的AI绘图工具。ComfyUI就像拥有一支神奇魔杖,可以轻松创造出令人惊叹的AI生成艺术。从本质上讲,ComfyUI是构建在Stable Diffusion之上的基于节点的图形用户界面(GUI),而Stable Diffusion是一种最先进的深度学习模型,可
