- @ChailangCompany
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
C、C++、C#、Java、Python、Rust 和 JavaScript 编写一个简单的入门程序。

本文介绍了使用Rust重写SQLite数据库的简化实现方案"MiniSQL"。主要内容包括:1)项目规划支持基本SQL语法、行级存储和文件持久化;2)环境准备使用serde、thiserror等关键依赖;3)核心数据结构设计如表结构(Table)和数据库实例(Database)的定义;4)SQL解析功能实现,展示了CREATE TABLE语句的解析示例。该方案采用JSON临时存
用Rust实现类似SQLite的嵌入式数据库具有显著技术价值:Rust的内存安全特性能提升数据库可靠性,高性能与现代化工具链适合长期维护。市场需求方面,嵌入式数据库在移动应用、物联网等领域持续增长,Rust实现可满足定制化需求。对开发者而言,这是掌握数据库核心原理和参与开源社区的优质方向。但完全替代SQLite面临技术复杂度、生态兼容性等挑战,建议根据目标分场景评估,从简化版存储引擎或垂直领域定制

Rust 与 C/C++ 特性对比及数组排序算法示例 摘要: 本文对比了 Rust 和 C/C++ 在系统编程中的核心特性,包括内存管理、安全性、并发、性能等九个维度。Rust 通过所有权系统和借用检查实现了编译时内存安全,而 C/C++ 依赖开发者经验。性能方面两者接近,但 Rust 的工具链更现代化。在数组排序示例中,展示了 C 语言的 qsort 和快速排序实现,Rust 则通过标准库的 s

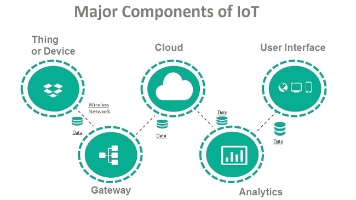
本文系统阐述了IoT平台的核心架构设计,围绕设备连接、数据流转、自动化决策和安全可信四大支柱展开。平台采用分层架构,包括设备接入层(支持MQTT/CoAP协议)、设备管理服务(生命周期管理)、数据管道(时序存储)、规则引擎(事件驱动)和安全体系(认证加密)。基于Rust实现高性能异步处理,支持百万级设备接入,并通过时序数据库优化、内存管理和网络压缩等技术保障系统性能。设计方案完整覆盖IoT场景需求
IoT平台功能与选型指南 物联网(IoT)平台的核心功能包括:设备接入与管理、数据采集处理、存储分析、应用集成、安全保障等。在选型时需考虑业务目标、设备规模、数据处理需求、系统集成要求及安全合规性。评估平台应重点关注其连接管理能力、数据处理分析功能、应用开发支持、安全运维方案及扩展灵活性。同时需权衡成本与商业模式,选择最适合自身业务需求的平台方案。
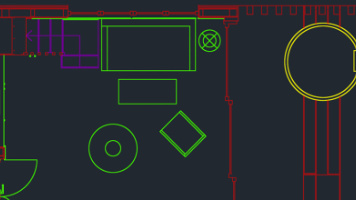
该框架实现了 CAD 的核心基础功能(几何建模、坐标系转换、文件交互),并通过模块化设计支持后续扩展。,聚焦几何建模、坐标系管理和 DXF 文件交互(CAD 最常用的交换格式)。代码设计强调模块化、可扩展性和 Rust 语言特性(如所有权、错误处理、泛型)。定义基础几何对象(点、线、圆)及其操作(平移、旋转、相交检测等)。抽象绘图操作接口,支持不同渲染目标(如屏幕、SVG、DXF)。实现 DXF
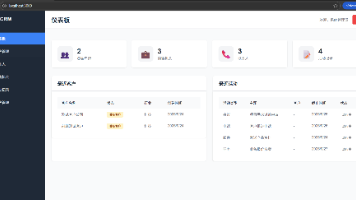
轻量化CRM系统7天开发规划摘要 本文提供一套7天高效开发轻量化CRM系统的完整计划,重点整合AI工具链(GitHub Copilot、DBDiagram.io等)并采用独立权限模块设计。系统定位小型团队,核心功能包括客户管理、销售跟踪及RBAC权限控制。技术栈选用Python+Flask+Vue3+SQLite,权限模块设计为独立服务(auth-service),支持JWT认证和细粒度权限校验。

本文档详细分析了轻量化CRM系统的需求,主要面向中小企业销售团队。系统包含四大核心功能模块:客户管理(信息录入/查询/状态管理)、销售机会跟踪(阶段管理/价值评估/跟进记录)、联系人管理(信息维护/角色分类)和用户权限控制(角色管理/数据范围)。非功能需求方面,系统需满足性能(响应时间<3秒,支持100并发)、安全(数据加密/访问控制)和可用性(99%正常运行)要求。文档还提供了数据模型设计

AI编程新体验:全程无需手写代码 本文展示了AI编程工具自动生成完整代码的能力,包含前后端全栈开发解决方案。通过多张功能截图和代码示例,展示了AI生成的: 基于FastAPI的后端服务(包含认证、路由、CORS配置等) Vue.js前端界面(客户管理页面含筛选、表格、模态框等组件) 清晰的接口定义和完整的业务逻辑 示例代码展示了CRM系统的核心功能模块,包括用户认证、客户管理、联系人管理等标准企业