




- @absence521
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
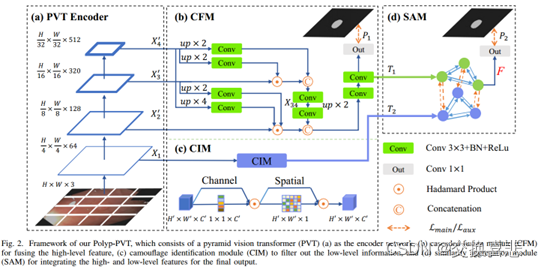
大多数息肉分割方法使用CNN作为主干,导致在解码器进行信息交换时需要考虑两个关键问题:1)考虑不同层次特征之间的贡献差异2)设计一种有效的融合机制与现有的基于CNN的方法不同,我们采用了变换编码器,它学习更加强大和健壮的表示。此外,考虑到息肉图像的影响和难以捉摸的特性,我们引入了三个标准模块,包括级联融合模块,伪装识别模块和相似性聚合模块,其中,CFM用于从高层特征中收集息肉的语义和位置信息;
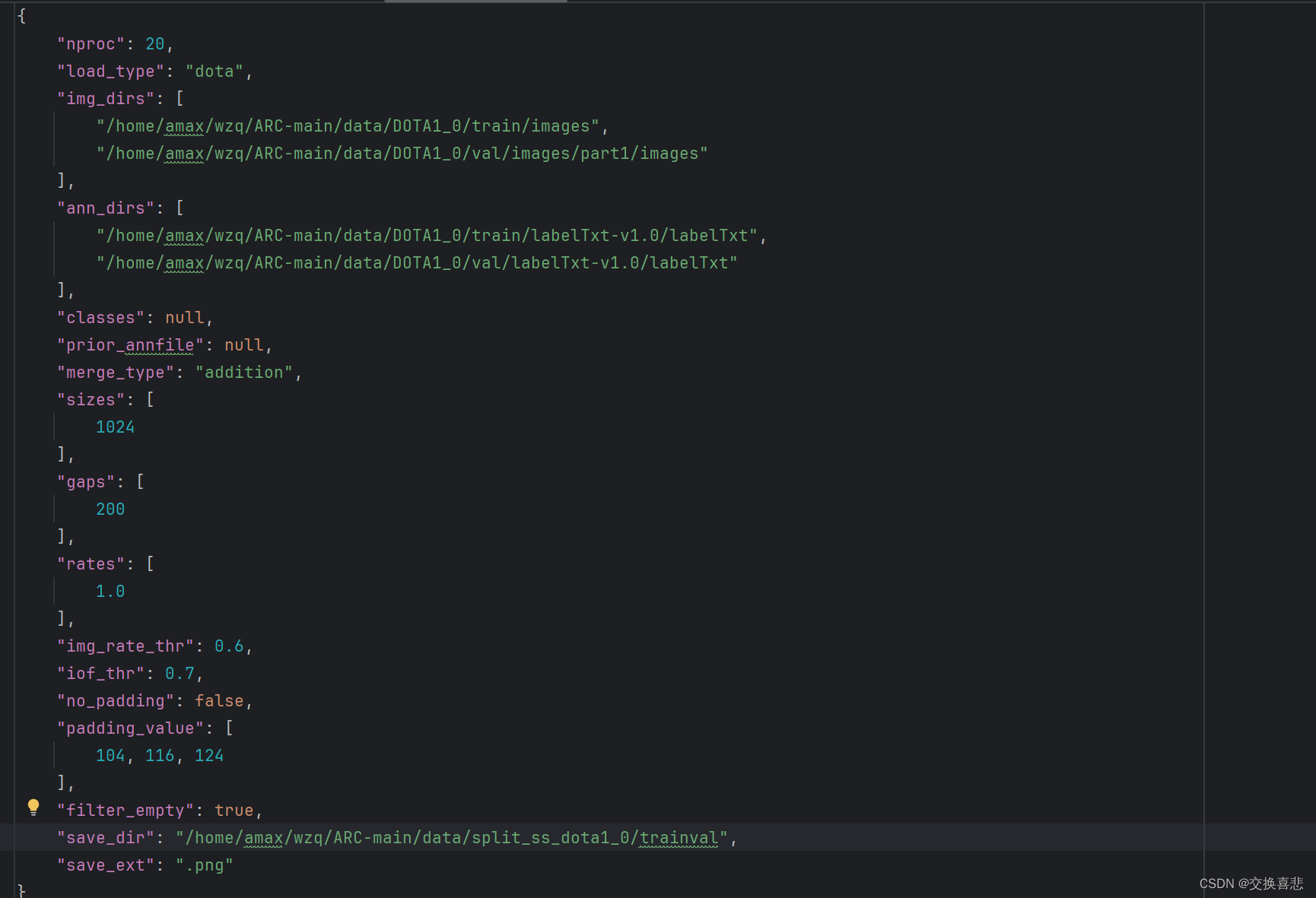
我是先导入ARC-main整个项目,后下载的BboxToolkit项目,解压后放进ARC-main,在splitn data的过程中,出现BboxToolkit包无法下载的问题,当时我忘记运行命令,cd到BboxToolkit后,即可成功下载BboxToolkit包,直接运行命令无法 成功下载,匹配不到合适的版本包。坑:DOTA数据集,官网上下载的train和test都分为part1,part2,
在cnn种,通道数就是用于提取特征的滤波器的数量(卷积核数量),在卷积过程中,每个滤波器会对输入特征图进行卷积操作,生成一个新的特征图,通道数就是指卷积后生成的特征图的数量,每个通道可以表示不同的特征信息,例如图像的颜色、边缘、纹理等。这里面352x352表示的是像素大小,即高和宽都为352个像素,而3表示的是通道数,指输入的是3通道的RGB图像,每个颜色通道的取值范围为0-255,可以表示256

这样生成的xml文件,没有之前COD10K标注的segmentation信息,还需要进一步考虑,在转换为xml的脚本中加上识别segmentation部分。1.OSFormer中提供的COD10K的json格式,是coco的格式,但由于伪装目标检测任务的特殊性,标注信息中还有一个segmentation段。

提高几乎所有机器学习算法性能的一个非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均[3]。不幸的是,使用整个模型集合进行预测非常麻烦,并且计算成本可能太高,无法部署到大量用户,尤其是在单个模型是大型神经网络的情况下。Caruana 和他的合作者 [1] 已经证明,可以将集成中的知识压缩到单个模型中,该模型更容易部署,并且我们使用不同的压缩技术进一步开发了这种方法。

在cnn种,通道数就是用于提取特征的滤波器的数量(卷积核数量),在卷积过程中,每个滤波器会对输入特征图进行卷积操作,生成一个新的特征图,通道数就是指卷积后生成的特征图的数量,每个通道可以表示不同的特征信息,例如图像的颜色、边缘、纹理等。这里面352x352表示的是像素大小,即高和宽都为352个像素,而3表示的是通道数,指输入的是3通道的RGB图像,每个颜色通道的取值范围为0-255,可以表示256
提高几乎所有机器学习算法性能的一个非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均[3]。不幸的是,使用整个模型集合进行预测非常麻烦,并且计算成本可能太高,无法部署到大量用户,尤其是在单个模型是大型神经网络的情况下。Caruana 和他的合作者 [1] 已经证明,可以将集成中的知识压缩到单个模型中,该模型更容易部署,并且我们使用不同的压缩技术进一步开发了这种方法。
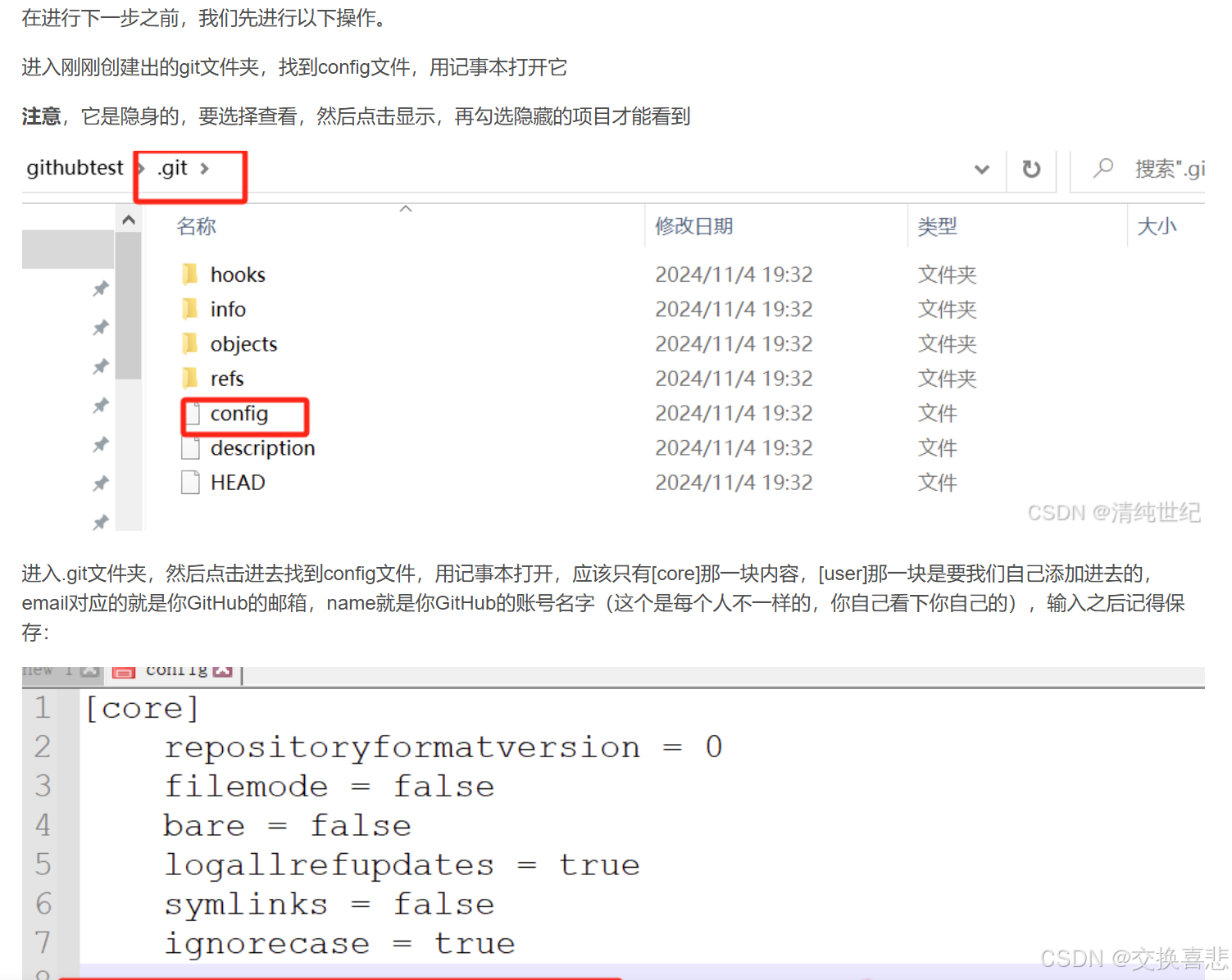
默认情况下,GitHub 仓库的主分支名称是 “master”,但为了更加包容和尊重的命名,GitHub 已经将默认分支更改为 “main”。在下面加入这两行代码,用户名和邮箱是自己的github账号的。
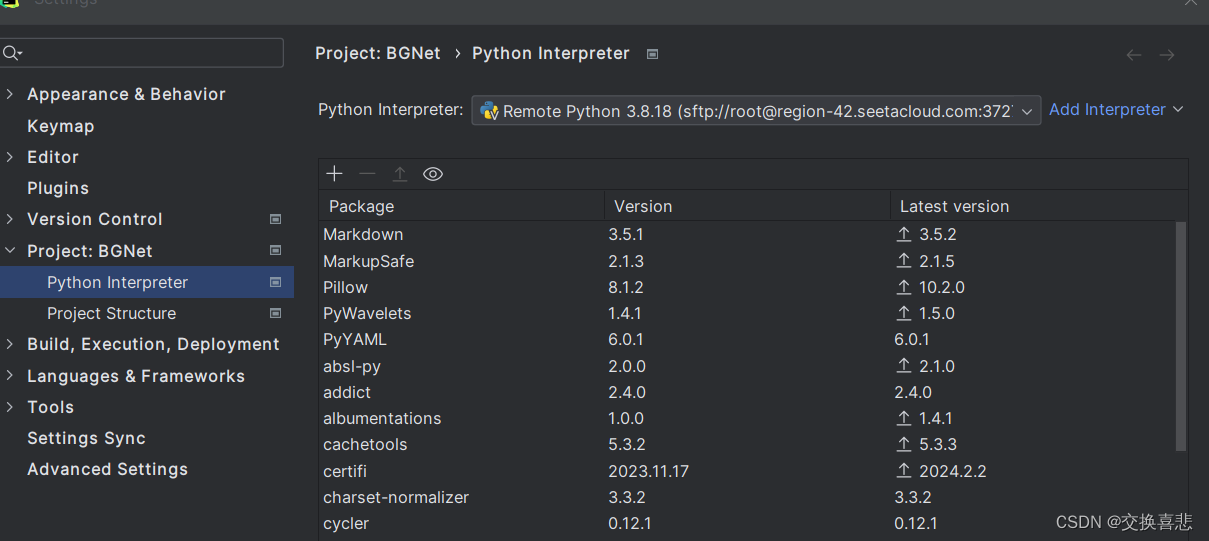
最后将工程目录下的.idea目录删除,然后重新创建工程。再将之前的解释器全部删除,重新创建即解决了这个问题。使用的是ssh方式,解释器使用的是conda里的自定义的python。后来,尝试了几种方法,都没法解决,比如删了解释器重新添加等。
我是先导入ARC-main整个项目,后下载的BboxToolkit项目,解压后放进ARC-main,在splitn data的过程中,出现BboxToolkit包无法下载的问题,当时我忘记运行命令,cd到BboxToolkit后,即可成功下载BboxToolkit包,直接运行命令无法 成功下载,匹配不到合适的版本包。坑:DOTA数据集,官网上下载的train和test都分为part1,part2,