登录社区云,与社区用户共同成长
邀请您加入社区
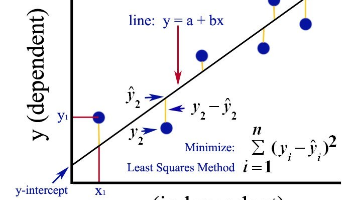
很多同学在学习机器学习、深度学习算法的过程中,没有获得感和成就感,因为仅仅学习了理论,没有落地的出口,感受不到这个算法有什么作用或者能解决什么问题这一期给大家推荐一个爆火项目practicalAI, 项目本身就是让大家在实战当中学习AI技术,代码可以在Jupyter中运行下面具体来介绍一下这个实战项目:实战一:线性回归项目。
二进制跳转法(倍增法)预处理时间。
这条路径的逻辑链很清晰——把 AGI 作为单一的、最高优先级的攀登目标,为了支撑这个目标,匹配一个利润最大化的闭源商业模式,用极致的资本密度去堆出极致的算力,最终实现一种甩开全世界的能力跃迁。OpenAI 的态度最耐人寻味,总裁 Brockman 承认了 K3 的实力,但把话题转向了 OpenAI 的基础设施投入优势,认为开放权重模型并非真正「免费」,因为大规模部署仍然需要昂贵的硬件。而 K3 引
华为完成鸿蒙系统内部战略重组,统一整合操作系统及相关知识产权与品牌域名资产。此举强化品牌独立性,优化生态协同效率,为全球市场拓展奠定基础。鸿蒙系统设备数量已突破X亿台,成为全球第三大移动操作系统。华为表示将持续加大研发投入,开放合作共建生态。分析认为这是鸿蒙迈向市场化独立运营的关键步骤,展现华为的战略韧性,未来将探索更广阔的商业化路径。
为了判断一个有向图是否是半连通的,我们可以使用深度优先搜索(DFS)或广度优先搜索(BFS)。核心思路是检查从任意顶点出发是否能访问到所有其他顶点,并且对于任意顶点,都存在一条路径到达另一个顶点或另一个顶点存在一条路径到达它。以下是一个使用DFS的Go语言实现:算法分析:正确性:时间复杂度:此算法适用于相对较小的图,对于大规模图可能效率不高。对于大型图,可以考虑使用更高效的图遍历和连通性检查算法。
WebAssembly与Python的结合正在重塑前端开发的边界:科学计算工具(Pandas/NumPy)在浏览器中无缝运行复杂算法(图像处理/信号处理)实现客户端处理AI模型推理不再依赖服务器资源技术演进趋势WebGPU加速提供接近原生性能WASI(WebAssembly系统接口)扩展操作系统能力线程支持实现真正的并行计算随着WebAssembly多线程和SIMD支持的全面落地,Python在浏
只向右/下合并:避免重复操作(比如 (0,0) 和 (0,1) 合并后,(0,1) 就不需要再和 (0,0) 合并了)。4. 最终岛屿数 = 所有 '1' 的数量 - 合并次数,或者更简单:统计并查集中根节点的数量(仅限 '1' 的位置)。- 统计根节点:只有 '1' 的位置才可能是岛屿的一部分,所以只在这些位置检查 find(idx) == idx。给定一个由 '1'(陆地)和 '0'(水)组成
欧拉路径(Eulerian Path):一条路径,经过图中每条边恰好一次欧拉回路(Eulerian Circuit):一条起点 = 终点的欧拉路径注意:欧拉路径关心的是边,不是点。每个点可以经过多次,但每条边只能走一次。与之对应的是哈密顿路径——经过每个点恰好一次。
Problem:后序遍历整棵树,哈希表记录需要删除的node数字,参数需要包括父节点,以及属于左子树还是右子树的标记lr,若left非空则放入left,right非空放入right,若lr-1则根节点被删除最后若根节点不需要被删除,还需要加入根节点。
这是一道典型的图论(Graph Theory)应用题,主要考察有向图的入度统计和环路检测。
本文系统介绍了Elasticsearch中两种聚合遍历模式:深度优先(DFS)和广度优先(BFS)。DFS采用分支递归策略,内存占用低,适合低基数全量统计;BFS采用分层剪枝策略,支持size过滤无效桶,专为高基数TopN聚合优化。文档详细对比了两者的核心原理、执行流程、适用场景及生产规范,指出DFS是默认策略适合常规报表,BFS则是高基数场景的性能优化方案。关键选型原则:低基数用DFS,高基数T
编码Agent 工具会在当前项目下生成AGENTS.md文件用于记录相关上下文和规范信息;每个md文件都有一个唯一ID,其中根文件ID为0,其他文件除自身ID外,还有一个父文件ID;Agent在加载某个md文件时需同时加载该md文件的所有子文件,当前给定3个输入值:
协定明确,世界人工智能合作组织是独立的政府间国际组织,遵循《联合国宪章》宗旨,秉持共商共建共享理念,坚持以人为本原则,旨在促进人工智能国际合作和全球治理,确保人工智能朝着有益、安全、公平方向健康有序发展,造福全人类。某些西方国家,一边虹吸全球人才,一边限制高科技人才向发展中国家反哺,更试图将人工智能治理变成少数人主导的俱乐部规则,甚至将AI工具使用权当作要挟的筹码。差距,不只是算力和数据,更关键的
您提到的这些技术共同构成了一个健壮、安全、高效的企业网络架构。以下是这些核心技术的功能与作用解析。
生成树协议用于消除网络中的二层环路,防止广播风暴。其核心是选举根桥、阻塞冗余链路,并在主链路故障时激活备份链路。Super VLAN 通过一个三层 VLAN 接口(SVI)为多个二层隔离的 Sub VLAN 提供三层网关,实现 IP 地址的节省和广播域的隔离。不同 Sub VLAN 间的通信需要依赖 Super VLAN 的 ARP 代理功能。端口安全通过限制接口学习到的 MAC 地址数量或绑定特
做后端开发和数据运维这么多年,我见过太多团队踩过SQL性能的坑:业务量刚破十万,数据库CPU直接冲到99%,接口超时告警刷满整个运维群,排查半天最后发现只是一条没加索引的关联查询拖垮了整个服务。很多人总觉得“SQL慢了就加索引”,但实际线上场景里,盲目加索引不仅解决不了问题,还可能引发写入性能下降、索引冗余等新问题。今天我就结合自己在电商订单系统里踩过的真实案例,把从定位问题到落地优化的完整流程拆
题目要求统计每个节点到根节点路径上的素数点权最大值。通过欧拉筛预处理素数判断,再用一次DFS遍历树结构,每个节点继承父节点的最大值并与当前素数点权比较更新。时间复杂度为O(n),适用于大规模数据。最终输出每个节点的结果,若没有素数则输出-1。代码实现了高效预处理和树遍历,解决了暴力方法的时间复杂度过高问题。
做后端开发的人,几乎都有过这样的经历:刚上线的系统跑起来飞快,用户量涨了几十万之后,数据库查询突然就慢得像蜗牛,随便一个列表页都要加载五六秒,DBA翻出慢日志一看,全是全表扫描的记录。很多人第一反应就是给表加索引,结果东一个西一个建了十几个索引,查询速度没提上来,订单提交的接口反而开始超时。我在电商平台做了7年数据库架构,见过太多团队把索引当成“万能解药”,最后把数据库的写入性能拖垮一半。
dfs 序:1 → 2 → 回溯 → 3 → 回溯 \(in[1]=1,\ out[1]=3\) \(in[2]=2,\ out[2]=2\) \(in[3]=3,\ out[3]=3\) 子树 1 对应区间 \([1,3]\),子树 2 对应 \([2,2]\)。
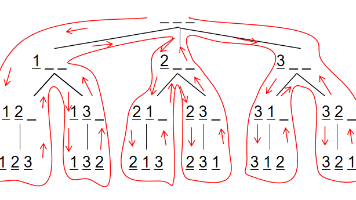
本文介绍了深度优先搜索(DFS)的基础知识及其在排列数字和N皇后问题中的应用。DFS通过递归和回溯实现,适用于解决全排列等组合问题。排列数字问题展示了如何用path数组保存排列状态,通过标记数组避免重复使用数字。N皇后问题则利用三个标记数组(列、主/副对角线)来确保皇后位置的合法性,通过逐行放置皇后并回溯寻找所有解。文章提供了C++和Python两种语言的代码实现,详细解释了递归终止条件、状态标记
这篇文章介绍了LeetCode 695题「岛屿的最大面积」的解题思路。该题需要在给定的二维网格中,找到由相邻1(陆地)组成的最大岛屿面积。文章通过与「岛屿数量」问题的对比,强调了本题的关键差异在于从计数变为面积计算,并详细解析了DFS算法中如何累加面积和跟踪最大值。核心代码展示了如何通过递归遍历网格、标记已访问节点、统计当前岛屿面积并更新全局最大值。这道题可以帮助读者巩固洪水灌溉算法框架,理解搜索
文章摘要: LeetCode题目“被围绕的区域”要求将矩阵中被X包围的O替换为X,而与边界相连的O保留。解题关键在于逆向思维:先标记所有与边界相连的O区域(安全区),再处理剩余O。核心步骤包括:1) 遍历矩阵四边,用DFS标记连通O为临时符号;2) 二次遍历将未标记O改为X,恢复标记区域为O。该解法通过两次遍历实现原地修改,时间复杂度O(mn)。相比直接检测被包围区域,这种"标记安全区+
摘要 本文深入解析了LeetCode 417题“太平洋大西洋水流问题”的解题思路。题目要求找出能同时流向太平洋和大西洋的网格坐标,关键在于逆向思维的运用。常规DFS逐个检查会超时,因此采用反向策略:分别从太平洋和大西洋边界出发,标记能逆流到达的陆地格子,最终取两者的交集。文章详细拆解了DFS实现步骤,包括方向数组、标记数组初始化及边界处理,并提供了代码示例。通过这道题,读者可掌握逆向思维和洪水灌溉
在NVIDIA的CUDA和Google的XLA两大技术基石上,CuPy与JAX分别开辟了不同路径。CuPy是"更好的C",提供确定性的硬件控制JAX是"科学的Lisp",用函数式抽象释放生产力当你在粒子物理模拟中选择CuPy的确定性内存管理,或在微分方程求解中运用JAX的三连击时,记住:两种工具都在推动人类认知的边界——毕竟,谁能拒绝在1分钟内完成原本需要1天的计算呢?
本文围绕力扣529.扫雷游戏问题展开,详细讲解了如何用DFS(深度优先搜索)模拟扫雷点击后的棋盘更新逻辑。首先,文章通过示例直观演示了扫雷棋盘的更新过程,帮助理解规则:点击地雷('M')会将其标记为'X';点击未翻开的空方块('E')时,需计算周围地雷数,若数量大于0则更新为对应数字并终止扩散,若为0则标记为'B'并向8个方向的'E'递归扩散。接着,阐述了具体思路,包括处理点击事件、计算周围地雷数
本文介绍了LCR 130/剑指Offer 13题"衣橱整理"的解题思路,这是一道经典的网格搜索问题。题目要求统计从(0,0)出发,只能向右或向下移动,且数位和不超过给定阈值的可访问格子总数。文章详细解析了问题要素,提出基于DFS的解决方案,包括方向数组设计、数位和计算、有效性判断等核心逻辑。代码实现中通过标记访问状态避免重复计数,并处理了边界条件。时间复杂度为O(m×n),空间
本文以斐波那契数问题为例,系统讲解了从暴力递归到优化算法的实现过程。首先通过递归解法直观展示问题,分析其O(2ⁿ)时间复杂度的缺陷,重点引入记忆化搜索优化方案。详细解析了备忘录设计、初始化操作和递归函数的核心逻辑,通过斐波那契数5的计算过程,演示了如何利用备忘录避免重复计算。相比暴力递归,记忆化搜索将时间复杂度优化至O(n),实现了空间换时间的平衡,为理解动态规划奠定了基础。文章强调通过简单问题掌
Java:实现kosarju的SCC算法(附带源码)
Java:递归方法实现DFS算法(附带源码)
Java:实现查找无向图的所有连通分图算法(附带源码)
Java:实现基于迭代的具有邻接表DFS算法(附带源码)
摘要: LeetCode题目“不同路径”是一个经典的动态规划问题,要求在m×n网格中,机器人从左上角到右下角(每次只能向右或向下移动)的路径总数。本文深入解析了从暴力递归到动态规划的优化过程: 暴力递归:直接拆解问题,但存在指数级重复计算; 记忆化搜索:通过备忘录存储子问题结果,将时间复杂度优化至O(mn); 动态规划:自底向上递推,用二维数组系统化存储状态,彻底消除递归开销。 核心递推公式为dp
本文深度解析力扣 375. 猜数字大小 II 问题,聚焦记忆化搜索算法的应用。从题目本质出发,通过决策树直观展示“确保猜到数字的最小初始金额”的求解逻辑,详细拆解从暴力递归到记忆化搜索的优化过程,逐行解析代码实现细节,并结合 n=3 实例推演记忆化过程。同时分析算法复杂度,总结实现坑点,为理解区间类记忆化搜索问题提供清晰思路,也为后续学习矩阵中最长递增路径等问题打下基础。
java-NC226 被围绕的区域。
java-NC316 体育课测验(二)
java-NC314 体育课测验(一)
java-NC327 取数游戏。
可上练习华子OD、大厂真题绿色聊天软件戳od1441了解算法冲刺训练(备注【CSDN】否则不通过)
算法描述,第一步,初始化数据结构,全排列在计算过程中,需要利用一个哈希表visited和一个栈stack来记录当前访问过的节点。第二步,顶点访问,依次访问所有顶点,如果发现这个顶点没有在哈希表中,则把它插入哈希表,并且把这个顶点入栈。这样一来,哈希表和栈中,存储的就是本次遍历中存储的点。第四步,当本次访问的顶点数等于总顶点数的时候,栈中的元素就代表一个排列,把排列进行输出或者做其他相应的处理。第五
用 Python+Qt 打造“波场哈希分分彩”:实时多模型预测结果
给一棵含有 $n$ 个结点的有根树,根结点为 $1$,编号为 $i$ 的点有点权 $a_i$ $(i \in [1, n])$。现在有两种操作,格式如下:- $1\ x\ y$ 该操作表示将点 $x$ 的点权改为 $y$。- $2\ x$ 该操作表示查询以结点 $x$ 为根的子树内的所有点的点权的异或和。现有长度为 $m$ 的操作序列,请对于每个第二类操作给出正确的结果。
深度优先
——深度优先
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 openEuler 社区
openEuler 社区
 AI编程社区
AI编程社区

 HarmonyOS开发者社区
HarmonyOS开发者社区














 DAMO开发者矩阵
DAMO开发者矩阵
 快递鸟社区
快递鸟社区




 AI Agent技术社区
AI Agent技术社区