- @yul1024
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
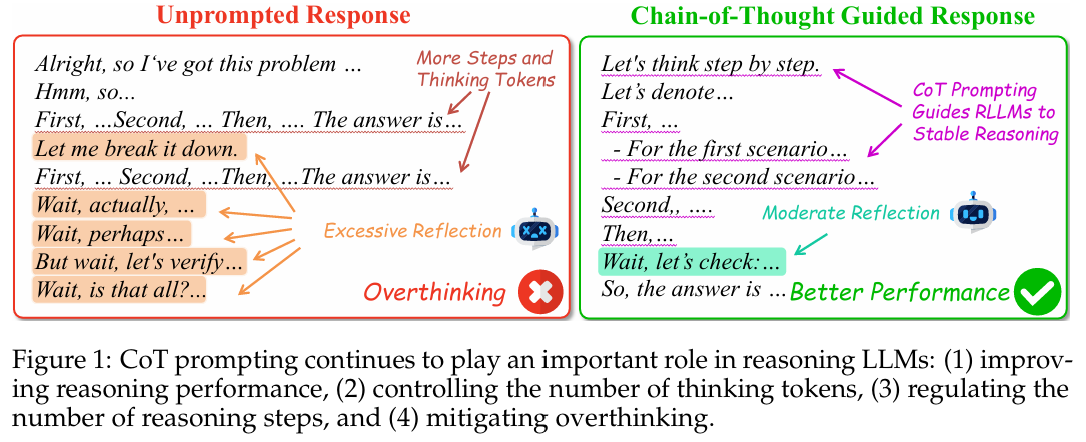
最近推理引入LLM,称为reasoning model或RLLM。RLLM的特点是,回答前先天生成CoT(innate CoT),包含反思和自我纠正。目前的研究是,innate CoT能显著增强模型的推理能力。传统的CoT的研究,不好的few-shot CoT是会降低模型性能。另一方面,既然模型能够自己生成CoT,那么输入的promt中CoT还重要吗?对于一般CoT的研究,一开始是few-shot
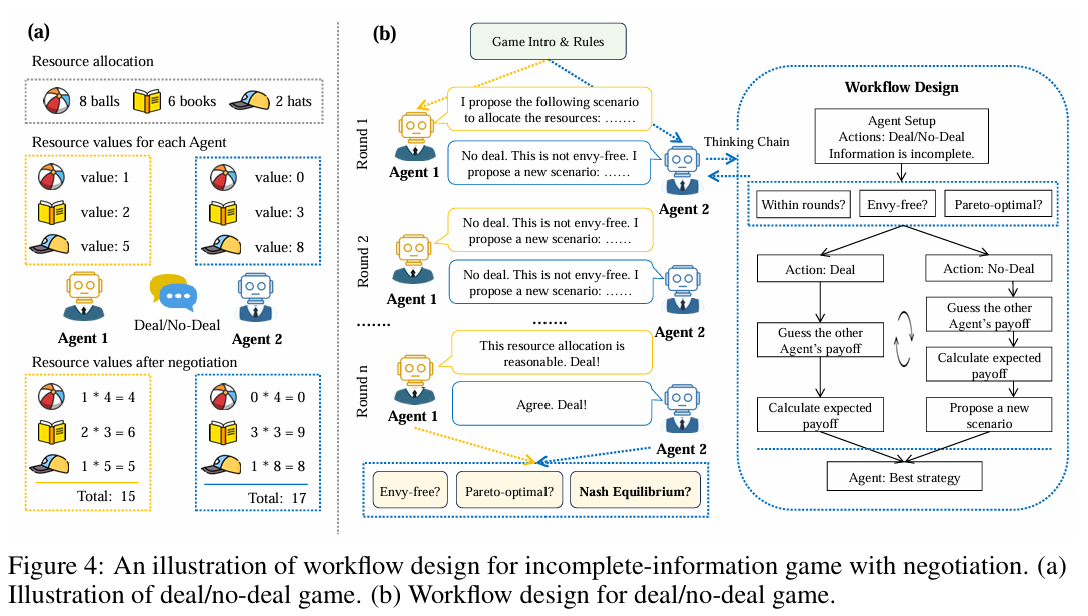
LLM的一个应用前景是去进行战略决策,而LLM因为幻觉以及本身能力的原因,决策会偏离理性。在博弈论框架的研究下,面临的情况是不确定性和不完全信息。构建workflow在很多方面会去提升agent在复杂交互场景下的表现。LLM的3个应用推理(planning)、行动(acting)、决策(decision-making)。
现有的LLM在一些方面能力很强,但是存在内在限制如幻觉、自回归性质、scaling law。一个方法是将LLM引入MAS。MAS有很大的好处在于,可以分布式部署Agent,然后汇总所有Agent的结果,从而获得更好的结果。目前已有的研究过于浅显,主要在于:- 仅涉及表明上的协同。- 没有具体设计架构。- 协同过于单一,没有从通用的角度解决问题。我觉得这可能不是一篇很好的论文。在已经掌握了LLM-b

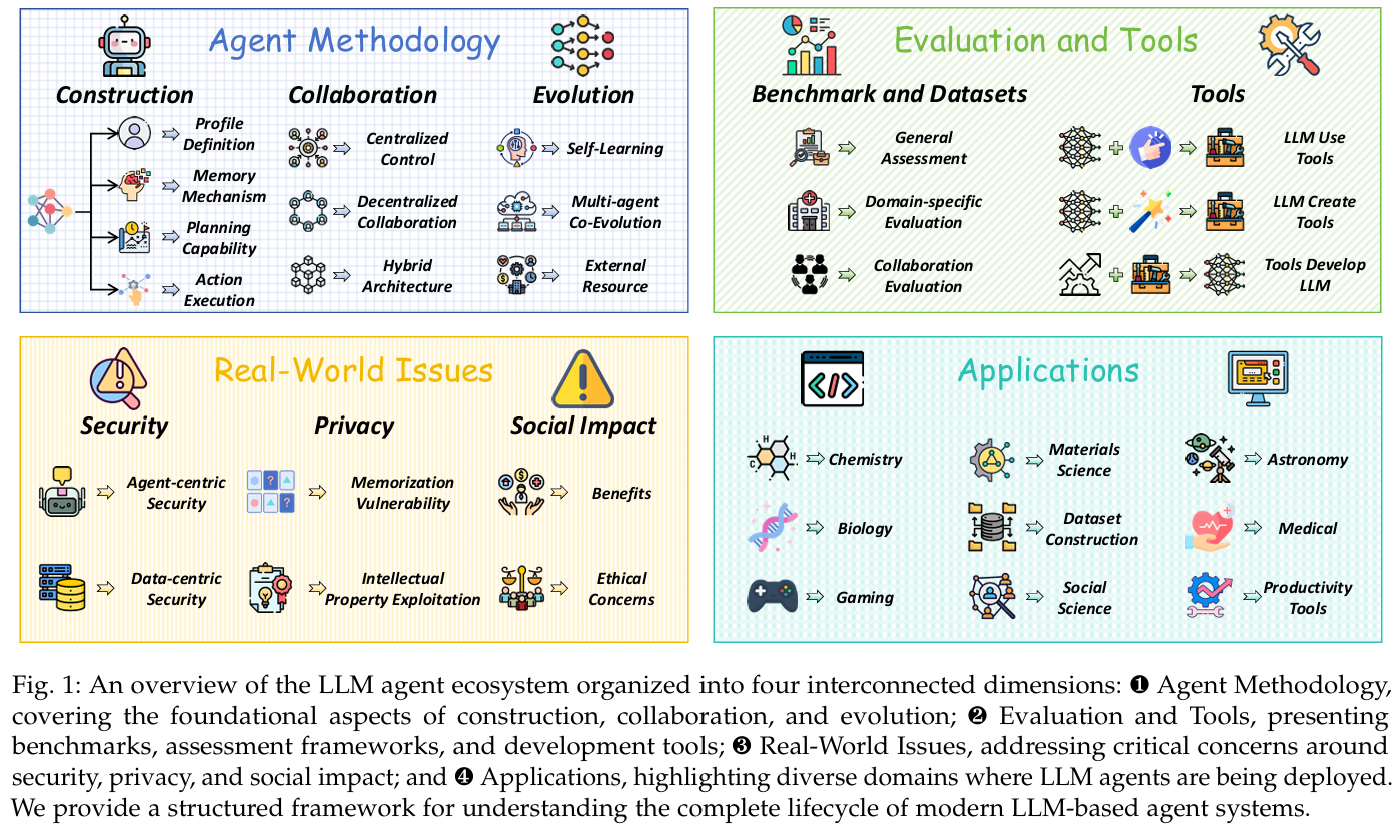
Agent的相关技术是伴随着LLM技术的进步而发展的。由LLM推动的技术进步改变了原有的技术范式,很大程度上是由于LLM可以作为通用任务的处理器。这是一篇很棒的关于LLM-based Agent的综述。论文以方法论这个统一的视角,说明了Agent各个角度的细节。论文同时维护一个github的仓库,该仓库持续更新Agent相关的最新论文。论文的主要有用的内容是agent方法、评估的部分,现实问题偏社