




- @A_art_xiang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
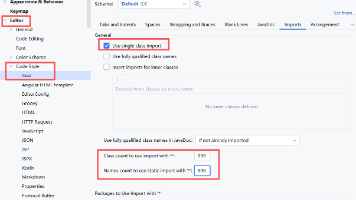
【代码】idea常用设置大全(持续更新)
StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRocks 来支持多种数据分析场景的极速分析。StarRocks兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。
RAGFlow 是一款基于深层文档理解的开源 RAG(检索增强生成)引擎。结合大语言模型 (LLM),它能够提供真诚的问答能力,并从各种复杂格式的数据中提供有据可查的引用。
上线前务必把核心索引写死。明确:字段类型、是否索引、所需 fields 及分析器。不让 ES 自己猜。当你不手动定义索引映射(Mapping)时,ES 会根据插入的第一条数据 “猜” 字段类型:数字可能被识别为text(文本),导致排序 / 聚合时需要额外转换,性能下降;手机号 / 身份证号被识别为long,但超出数值范围会报错;所有字段默认开启索引,即使是不需要检索的字段(如备注、日志详情),浪
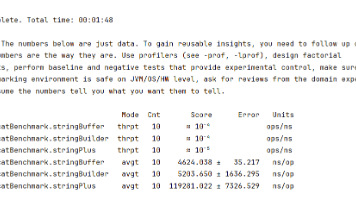
JMH(Java Microbenchmark Harness) 是 OpenJDK 官方出品的Java 微基准测试框架,专门测量纳秒~毫秒级短方法、代码片段性能,彻底解决手写计时(System.nanoTime)所有 JVM 陷阱。
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。Arthas 在生产环境应用时需要谨慎,某些命令比如:trace(深调用链)、heapdump、watch(复杂表达式 / 高频触发),持续字节码修改、大量数
APT(Annotation Processing Tool)即注解处理器,它是一种处理注解的工具,也是javac中的一个工具,用于在编译阶段未生成class之前对源码中的注解进行扫描和处理。APT可以用来在编译时扫描和处理注解, 它可以用来获取到注解和被注解对象的相关信息,在拿到这些信息后我们可以根据需求来自动的生成一些代码,省去了手动编写。APT获取注解及生成代码都是在代码编译时候完成的,相比
编辑jdk目录,保存之后【重启vscode】打开【设置】,搜索【java.home】
LangChain4j 是专为 JVM 生态(Java/Kotlin/Scala) 设计的开源大模型应用框架,核心目标是让 Java 开发者以类型安全、原生适配的方式快速集成 LLM 能力,无需跨语言桥接。它并非 LangChain 官方 Java 版,但设计思想对齐,且更贴合企业级 Java 开发习惯。
提示词工程,或称Prompt Engineering,是一种专门针对语言模型进行优化的方法。它的目标是通过设计和调整输入的提示词(prompt),来引导这些模型生成更准确、更有针对性的输出文本。在与大型预训练语言模型如GPT-3、BERT等交互时,给定的提示词会极大地影响模型的响应内容和质量。提示词工程关注于如何创建最有效的提示词,以便让模型能够理解和满足用户的需求。这可能涉及到对不同场景的理解、
