




- @m0_74462339
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
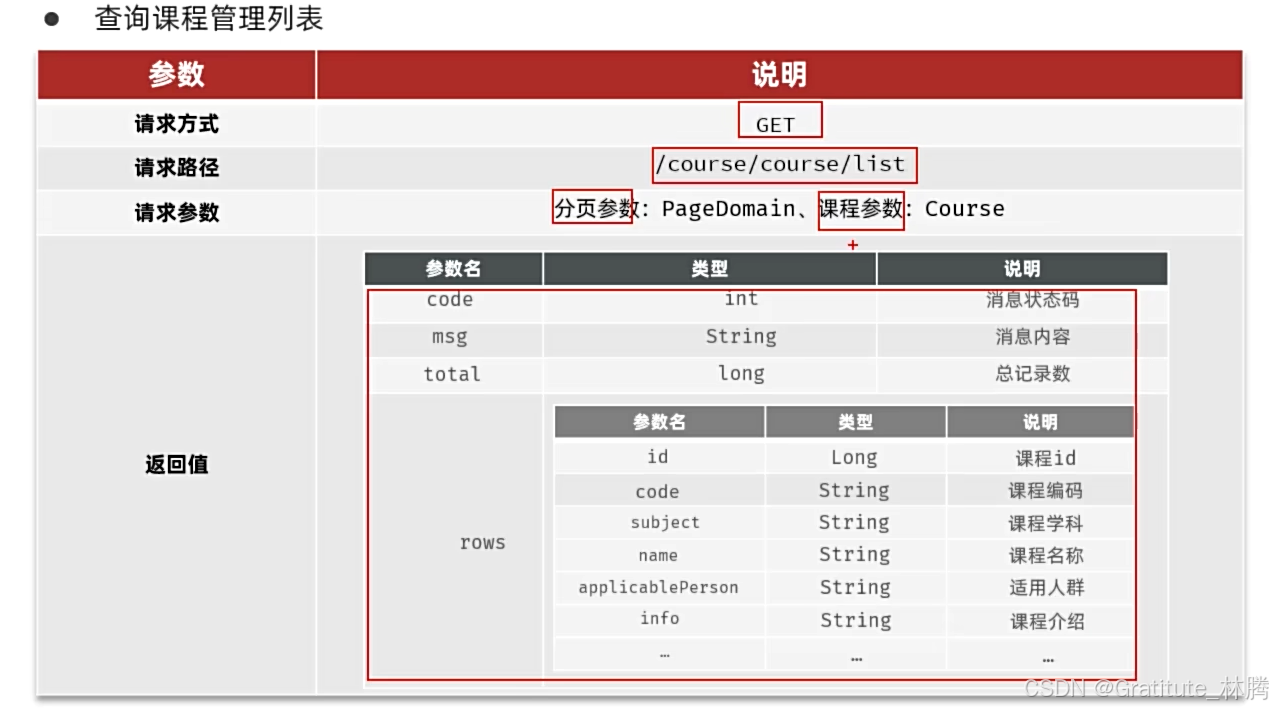
以查询课程管理列表为例。
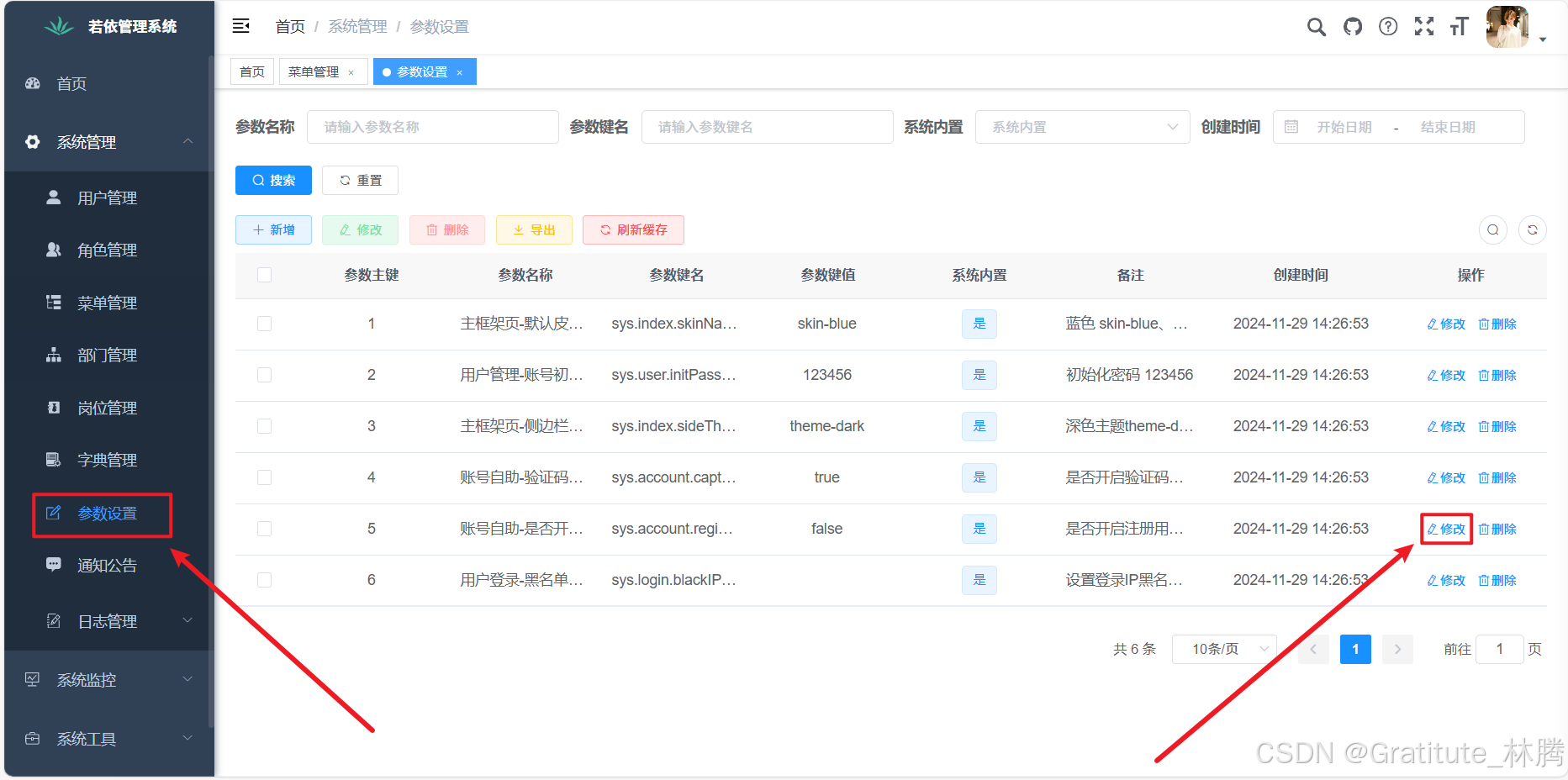
再找到login.vue,找到注册开关,将false改为true。这样一来,前端就可以切换到注册表单,并且能正常进行注册功能了。将false改为true。
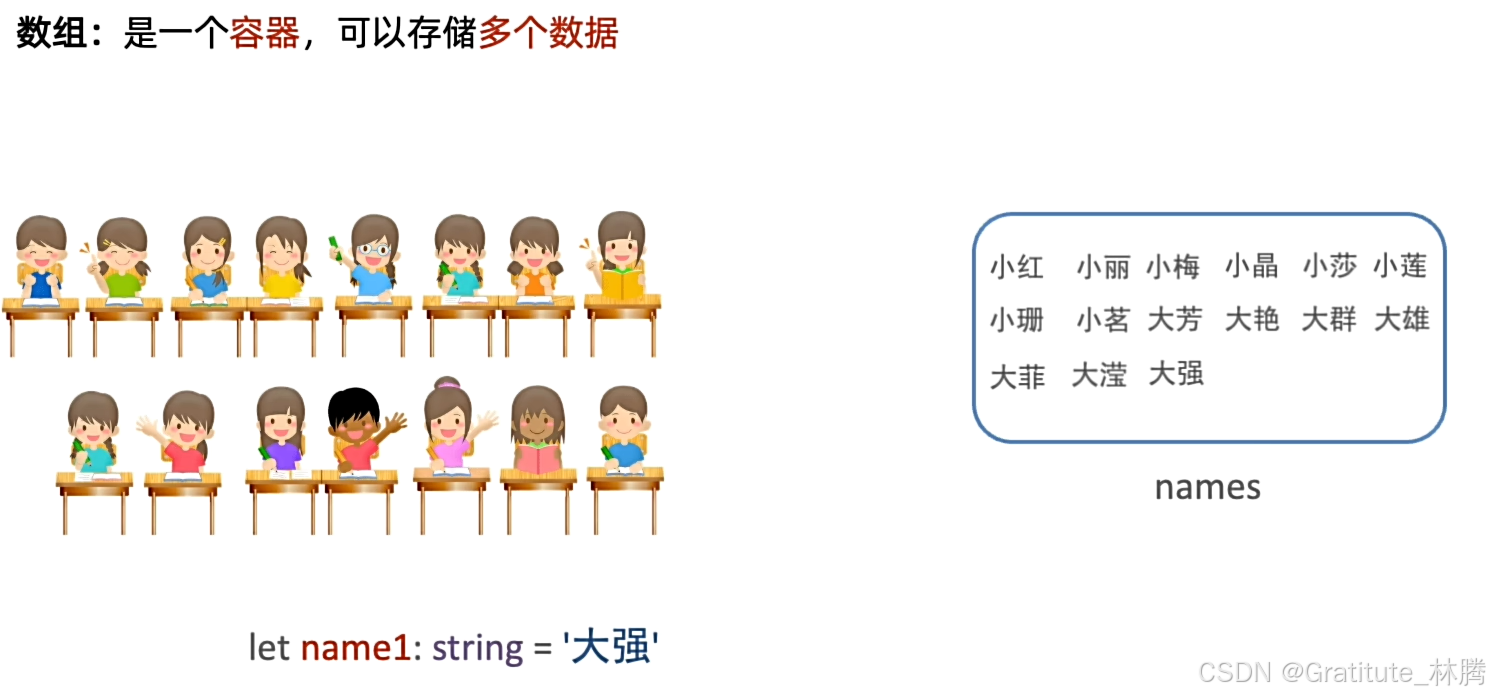
目录什么是数组语法总结
目录什么是函数函数的基本使用总结

目录认识数据存储数据总结

如图,index.etc里面的内容(图中框住的大长方形区域)会渲染到预览区中,而console.log('xx','xxx')用于内容的打印,需要在日志中查看打印的内容。

Colab(全称为Google Colaboratory)是由Google推出的一个基于云的Jupyter Notebook平台,允许用户在线编写和运行Python代码,尤其适合机器学习、数据分析等任务。云端运行:用户无需在本地配置环境,所有代码都可以在Google的服务器上运行,并且提供免费的CPU和GPU资源,方便进行计算密集型任务。Python支持:Colab主要支持Python,并内置了许

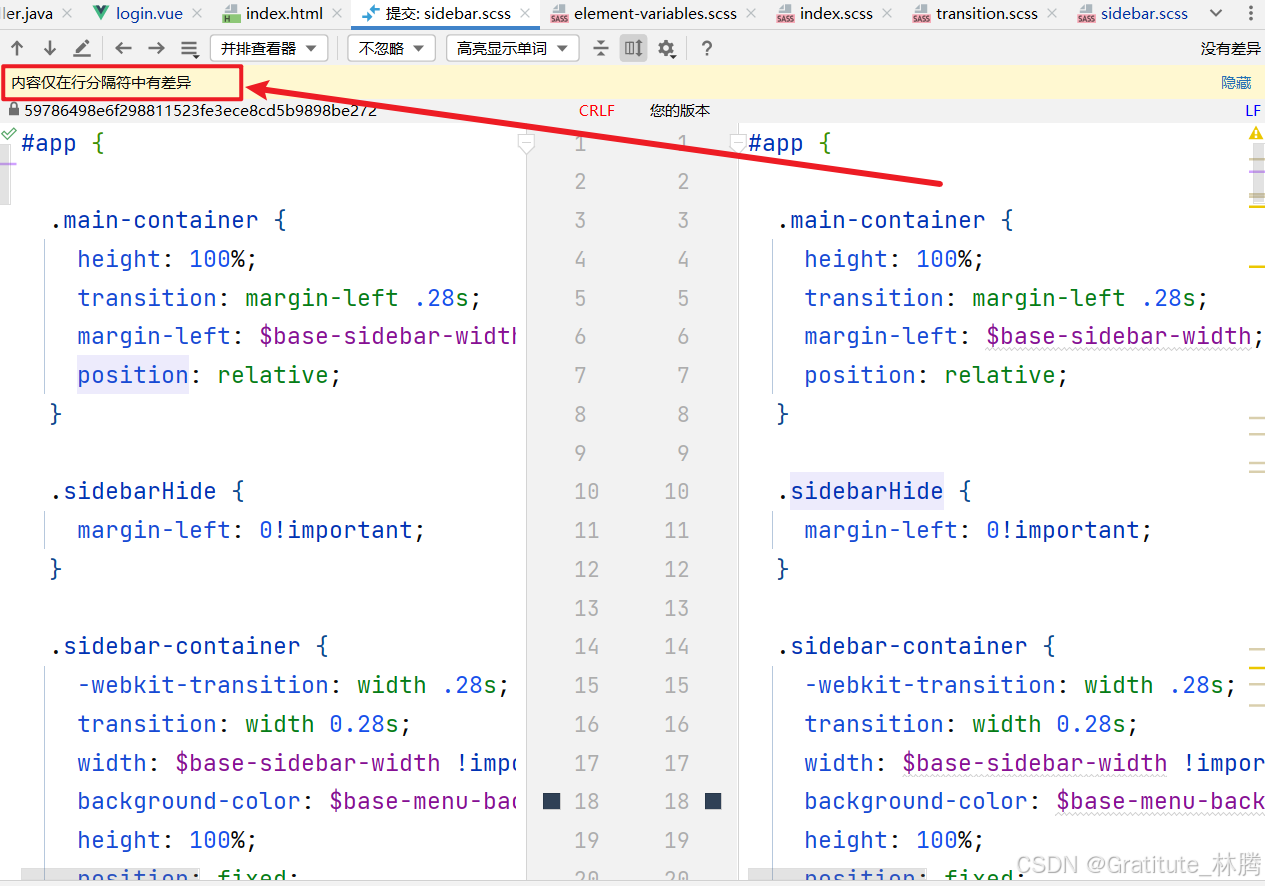
在开发过程中,git判断一些文件有修改,但点开该文件时,提示内容仅在行分隔符中有差异,这意味着两个文件的内容实际上是相同的,但它们的行分隔符不同。可是git还是认为这个文件有修改,开发者依然可以进行提交那这样就会产生误操作:既然文件本质上都没有修改,那你提交干什么?
比如现在我修改了两个文件:然后我高高兴兴地把它推送到了远程xianglinteng分支现在,我突然反悔了,想要回到修改之前的代码,即回到master分支的样子。
在开发过程中,一旦有一个人更新了代码,并发起了合并请求,管理员就会询问其他人有没有正在更新的代码,如果有,就先对自己正在更新的代码微调一下,使当前写的代码可以正常运行,即使功能没有写完也没关系,然后也发送合并请求。所有修改过项目的人都发起了合并请求后,管理员会将这些请求一起合并,这样,就避免了。
