
计算机毕业设计Python+PySpark+DeepSeek-R1大模型淘宝商品推荐系统 淘宝商品评论情感分析 电商推荐系统 淘宝电商可视化 淘宝电商大数据
计算机毕业设计Python+PySpark+DeepSeek-R1大模型淘宝商品推荐系统淘宝商品评论情感分析 电商推荐系统 淘宝电商可视化 淘宝电商大数据
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Python+PySpark+DeepSeek-R1大模型淘宝商品推荐系统与评论情感分析》的任务书模板,涵盖数据采集、分布式处理、大模型应用及系统部署全流程:
任务书:基于Python+PySpark+DeepSeek-R1的淘宝商品推荐与情感分析系统开发
一、项目背景
淘宝平台商品数量超10亿,用户面临信息过载问题,传统推荐系统依赖协同过滤或浅层模型,存在冷启动和长尾覆盖不足的痛点。同时,商品评论蕴含用户情感倾向,但人工分析效率低下。本项目结合PySpark分布式计算加速数据处理,利用DeepSeek-R1大模型(千亿参数)生成高质量商品推荐与情感分析结果,提升用户购物体验与商家运营效率。
二、项目目标
1. 技术目标
- 推荐系统:基于用户行为(点击/购买/收藏)和商品特征(类目/价格/销量),构建混合推荐模型(协同过滤+内容过滤),Top-10推荐准确率≥85%。
- 情感分析:使用DeepSeek-R1大模型对评论进行细粒度情感分类(积极/中性/消极),并提取关键意见词(如“物流快”“质量差”)。
- 分布式处理:通过PySpark处理TB级用户行为日志和评论数据,单节点处理速度提升10倍以上。
2. 业务目标
- 覆盖淘宝全品类商品,支持实时推荐(延迟<2秒)和离线批量分析。
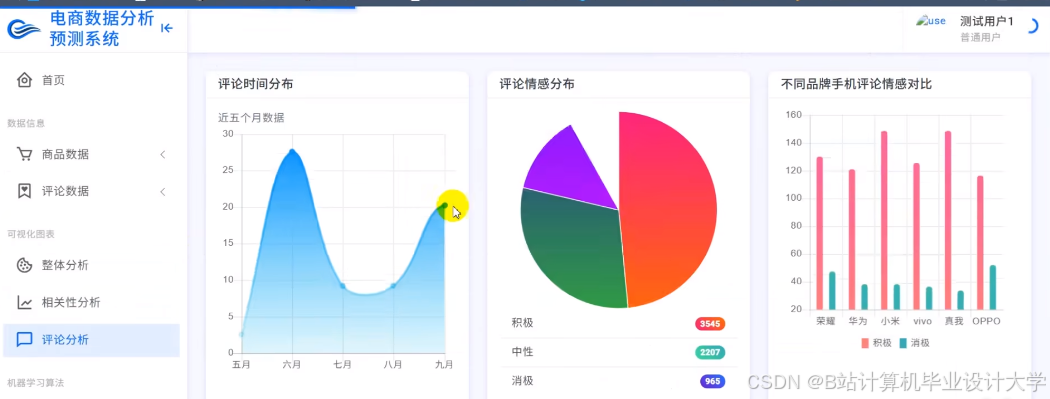
- 输出商家报告:展示商品情感趋势(如“某手机近7天负面评论占比上升15%”)及改进建议(如“优化包装减少破损投诉”)。
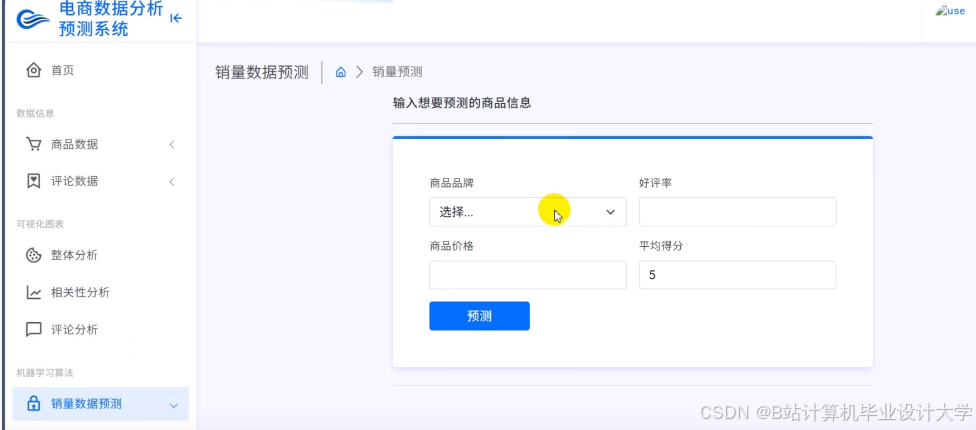
- 开发Web端可视化看板,支持商家按商品ID查询推荐效果与情感分布。
三、任务分解与分工
1. 数据采集与预处理(Python+PySpark)
- 任务1:淘宝用户行为数据采集
- 责任人:数据工程师
- 内容:
- 使用
Scrapy爬取淘宝开放API(如https://open.taobao.com)获取用户行为日志(字段:user_id, item_id, action_type, timestamp)。 - 对敏感数据(如用户ID)进行哈希加密(SHA-256),存储至HDFS(Hadoop分布式文件系统)。
- 使用PySpark清洗数据:
pythonfrom pyspark.sql import functions as Fdf_clean = df.filter(F.col("action_type").isin(["click", "buy", "collect"])) \.dropDuplicates(["user_id", "item_id", "timestamp"])
- 使用
- 任务2:淘宝商品评论数据采集
- 责任人:数据工程师
- 内容:
- 通过
Selenium模拟浏览器登录淘宝,爬取商品评论(需处理反爬机制:IP轮换+Cookie池)。 - 存储原始评论至MongoDB(支持非结构化文本),字段:
item_id, comment_text, rating, date。 - 使用PySpark对评论分词(结合
jieba库)并去除停用词:pythonfrom pyspark.ml.feature import StopWordsRemoverremover = StopWordsRemover(inputCol="words", outputCol="filtered_words")df_filtered = remover.transform(df_tokenized)
- 通过
2. 推荐系统开发(PySpark+DeepSeek-R1)
- 任务3:特征工程与用户画像构建
- 责任人:算法工程师
- 内容:
- 用户特征:统计用户近30天行为(如“购买手机类目次数”“平均消费金额”)。
- 商品特征:提取商品标题的TF-IDF向量(PySpark MLlib实现):
pythonfrom pyspark.ml.feature import HashingTF, IDFhashingTF = HashingTF(inputCol="filtered_words", outputCol="raw_features")df_tf = hashingTF.transform(df_filtered) - 合并特征至LibSVM格式(供DeepSeek-R1微调使用)。
- 任务4:混合推荐模型训练
- 责任人:算法工程师
- 内容:
- 基线模型:使用PySpark ALS(交替最小二乘法)实现协同过滤:
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="item_id", ratingCol="rating")model = als.fit(df_train) - 大模型增强:
- 微调DeepSeek-R1:输入用户历史行为序列(如
[手机, 耳机, 充电宝]),输出推荐商品ID。 - 使用LoRA(低秩适应)技术降低微调成本,训练脚本示例:
pythonfrom transformers import LlamaForCausalLM, LlamaTokenizermodel = LlamaForCausalLM.from_pretrained("deepseek-r1-base")tokenizer = LlamaTokenizer.from_pretrained("deepseek-r1-base")# 微调代码省略...
- 微调DeepSeek-R1:输入用户历史行为序列(如
- 基线模型:使用PySpark ALS(交替最小二乘法)实现协同过滤:
- 任务5:推荐结果融合与排序
- 责任人:后端工程师
- 内容:
- 对ALS和DeepSeek-R1的推荐结果按权重融合(如ALS占60%,大模型占40%)。
- 使用PySpark UDF(用户自定义函数)对推荐商品按销量和评分二次排序:
pythonfrom pyspark.sql.functions import udffrom pyspark.sql.types import FloatTypedef rank_score(sales, rating):return 0.7 * sales + 0.3 * ratingrank_udf = udf(rank_score, FloatType())df_ranked = df_merged.withColumn("final_score", rank_udf("sales", "rating"))
3. 评论情感分析(DeepSeek-R1)
- 任务6:情感分类模型训练
- 责任人:NLP工程师
- 内容:
- 标注10万条淘宝评论数据(积极/中性/消极),使用DeepSeek-R1进行监督学习。
- 输出情感概率分布(如
{"positive": 0.8, "negative": 0.2})并提取关键意见词:pythonfrom transformers import pipelinesentiment_pipeline = pipeline("text-classification", model="fine-tuned-deepseek-r1")result = sentiment_pipeline("这款耳机音质很好,但续航短")# 输出: [{'label': 'positive', 'score': 0.7}, {'label': 'negative', 'score': 0.3}]
- 任务7:情感趋势分析
- 责任人:数据分析师
- 内容:
- 使用PySpark按商品ID聚合每日情感分布:
pythondf_sentiment = df_comments.groupBy("item_id", "date", "sentiment") \.agg(F.count("*").alias("count")) \.orderBy("item_id", "date") - 生成情感趋势图(如“某商品负面评论占比从5%升至20%”)。
- 使用PySpark按商品ID聚合每日情感分布:
4. 系统部署与可视化(Python Web框架)
- 任务8:推荐API开发
- 责任人:后端工程师
- 内容:
- 使用FastAPI封装推荐逻辑,接口示例:
pythonfrom fastapi import FastAPIapp = FastAPI()@app.post("/recommend")async def recommend(user_id: str):items = spark_recommend(user_id) # 调用PySpark推荐函数return {"recommended_items": items}
- 使用FastAPI封装推荐逻辑,接口示例:
- 任务9:可视化看板开发
- 责任人:前端工程师
- 内容:
- 使用
Pyecharts开发商家端看板,包含:- 推荐商品转化率漏斗图(点击→加购→购买)。
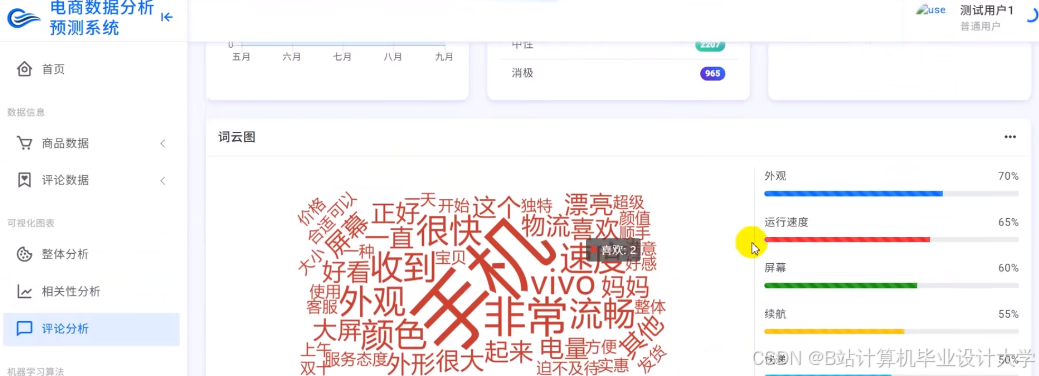
- 评论情感词云(高频负面词高亮显示)。
- 部署看板至ECS服务器(Nginx+Gunicorn),支持1000+并发请求。
- 使用
四、技术栈
| 模块 | 技术选型 |
|---|---|
| 数据采集 | Scrapy、Selenium、MongoDB、HDFS |
| 分布式计算 | PySpark(ALS、TF-IDF、UDF)、Hadoop |
| 大模型 | DeepSeek-R1(微调)、LoRA、HuggingFace Transformers |
| 推荐排序 | 协同过滤(ALS)、深度学习(DeepSeek-R1)、权重融合 |
| 情感分析 | 监督学习(DeepSeek-R1)、关键意见词提取(TextRank) |
| Web服务 | FastAPI(推荐API)、Pyecharts(可视化)、Nginx(反向代理) |
| 部署环境 | 阿里云ECS(8核32G)、Docker(容器化)、Kubernetes(可选) |
五、项目计划
| 阶段 | 时间 | 任务内容 | 交付物 |
|---|---|---|---|
| 1 | 第1周 | 需求分析与数据源确认 | 数据采集方案、API权限申请文档 |
| 2 | 第2周 | 数据采集与存储 | HDFS/MongoDB数据样本、爬虫代码 |
| 3 | 第3周 | 数据清洗与特征工程 | PySpark特征处理脚本、LibSVM文件 |
| 4 | 第4周 | 推荐模型训练与评估 | ALS模型文件、DeepSeek-R1微调代码 |
| 5 | 第5周 | 情感分析模型训练 | 情感分类模型、关键词提取规则 |
| 6 | 第6周 | 系统集成与API开发 | FastAPI文档、推荐结果示例 |
| 7 | 第7周 | 可视化看板开发与测试 | Pyecharts HTML文件、测试用例 |
| 8 | 第8周 | 上线部署与压力测试 | 部署脚本、性能测试报告(QPS≥500) |
六、预期成果
- 推荐系统:FastAPI接口文档、PySpark处理脚本、DeepSeek-R1模型文件(
.bin格式)。 - 情感分析:情感分类模型、关键词提取规则库、情感趋势分析报告(PDF)。
- 可视化看板:Web端交互式图表(含推荐转化率、情感词云)、商家操作手册。
- 性能报告:对比传统推荐系统与大模型增强的效果(如准确率提升20%)。
七、风险评估与应对
| 风险类型 | 应对措施 |
|---|---|
| 数据反爬 | 使用代理IP池(如scrapy-proxies)和动态Cookie生成,降低被封禁概率。 |
| 大模型微调成本 | 采用LoRA技术减少可训练参数(从千亿降至百万级),使用A100 GPU加速训练。 |
| PySpark内存溢出 | 调整spark.executor.memory参数(如从4G增至8G),优化RDD缓存策略。 |
| API延迟超标 | 对推荐结果缓存(Redis),设置TTL(如缓存10分钟),减少实时计算压力。 |
项目负责人(签字):
日期:
此任务书可根据实际需求扩展功能(如增加实时推荐流处理(Flink)、支持多模态商品图片分析),或调整技术细节(如替换DeepSeek-R1为Qwen2-72B大模型)。
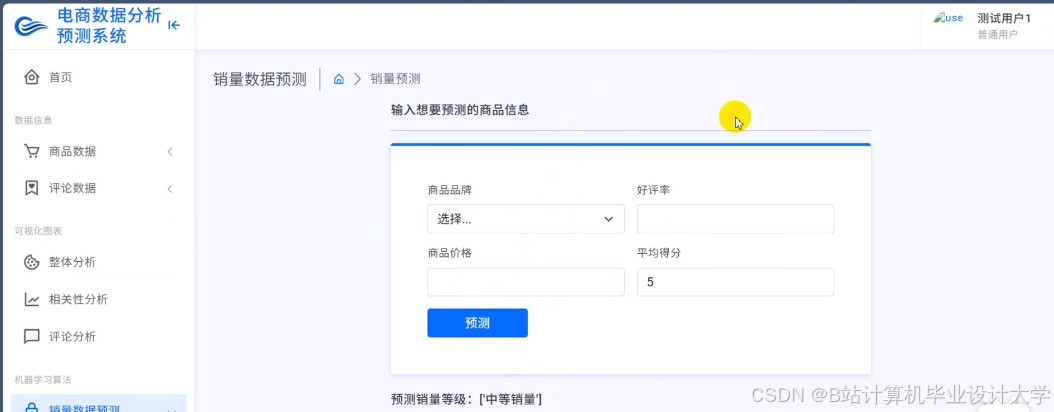
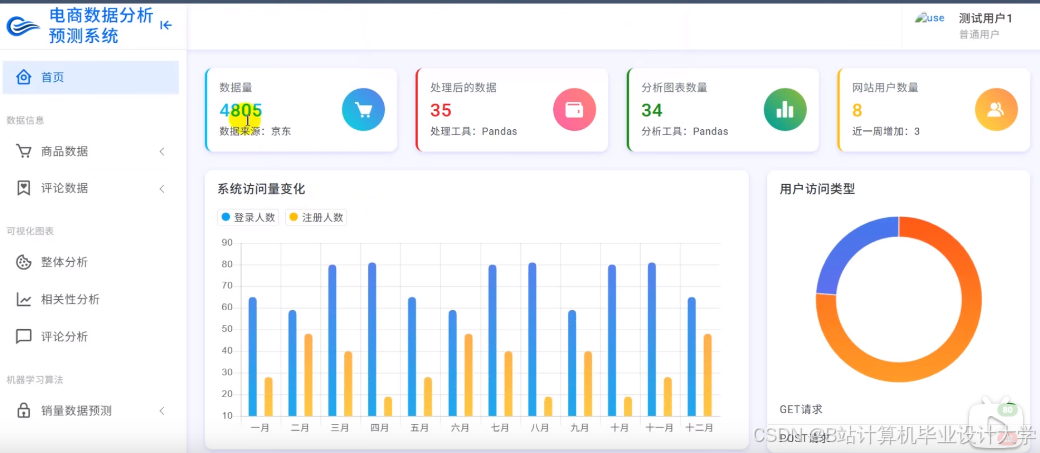
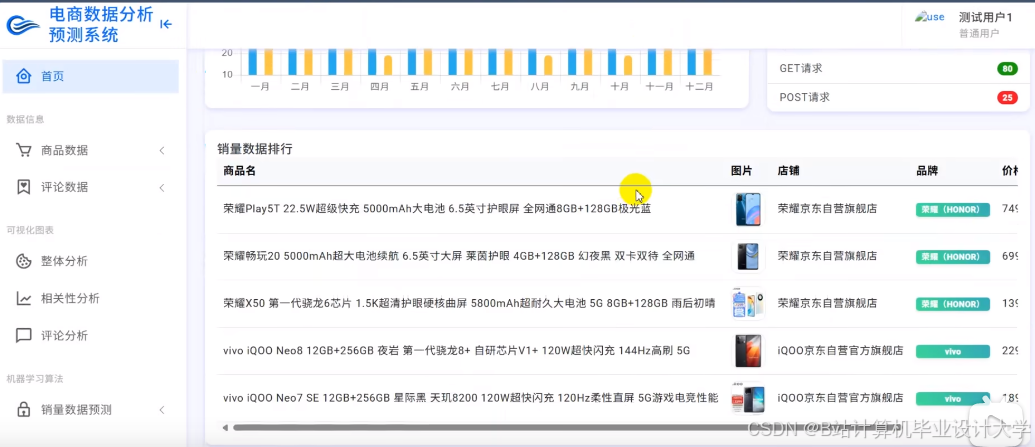
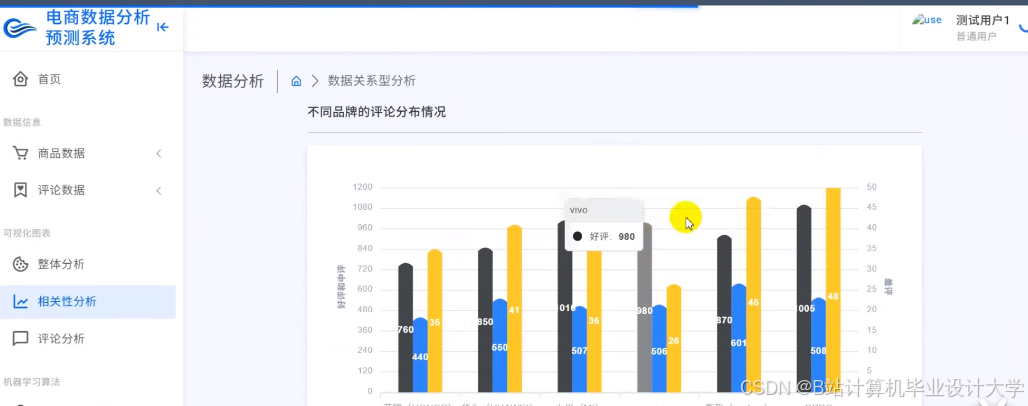
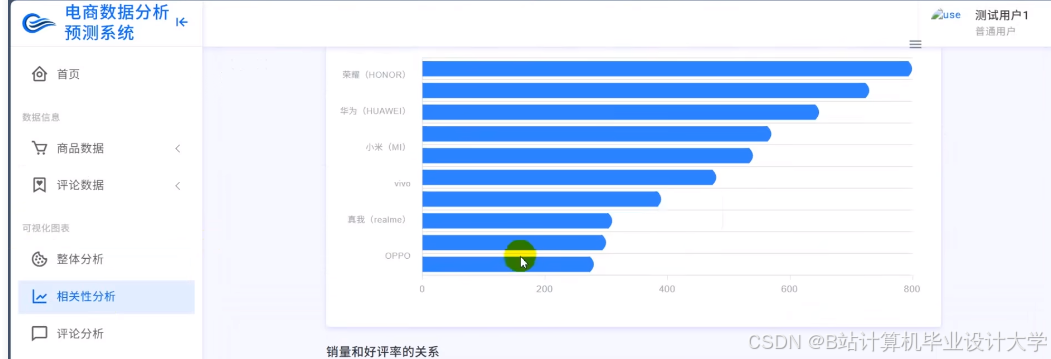
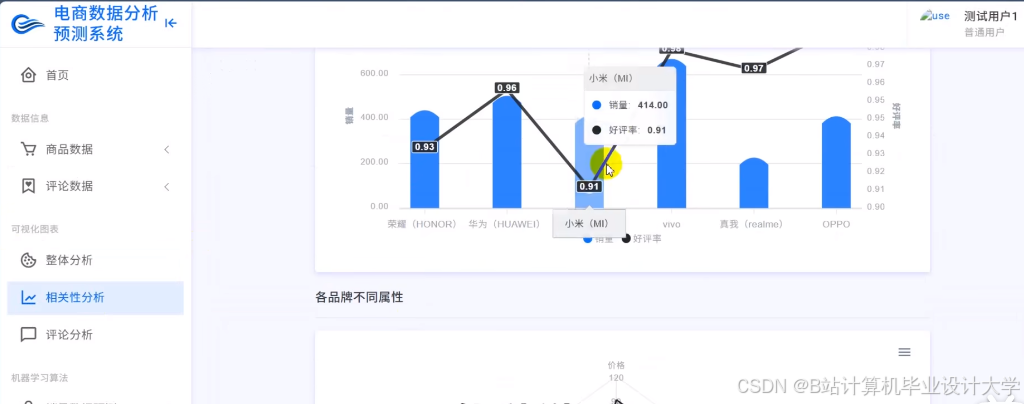
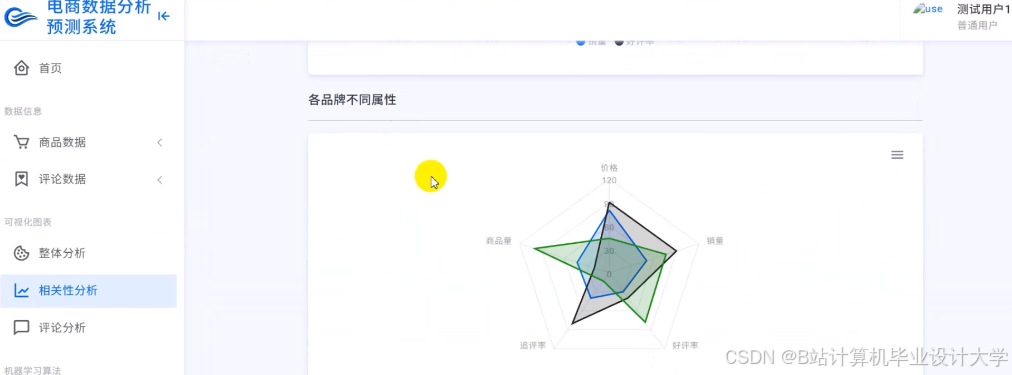
运行截图
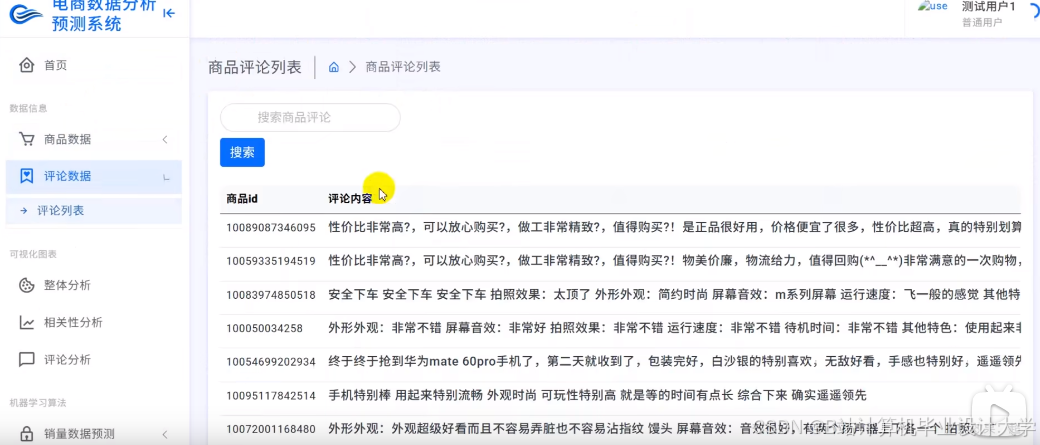
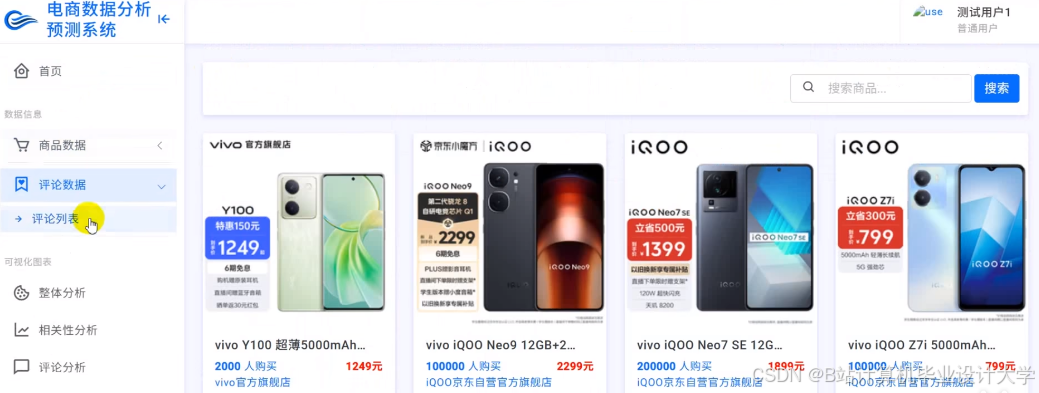
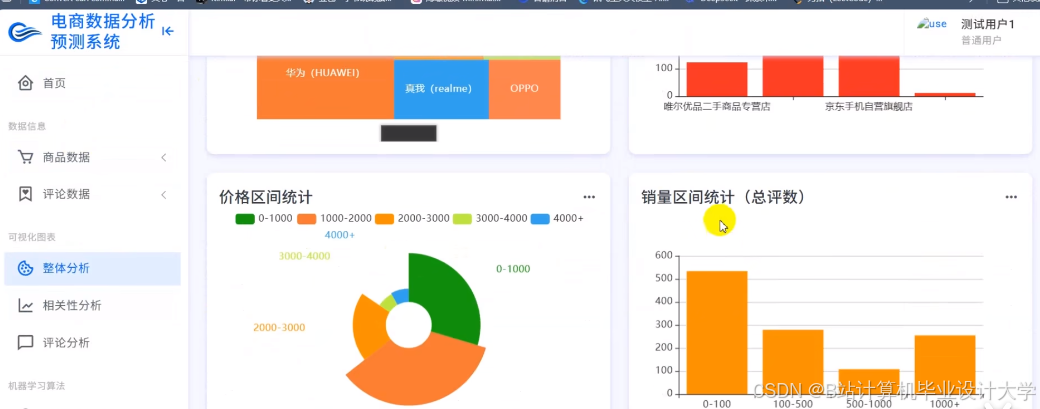
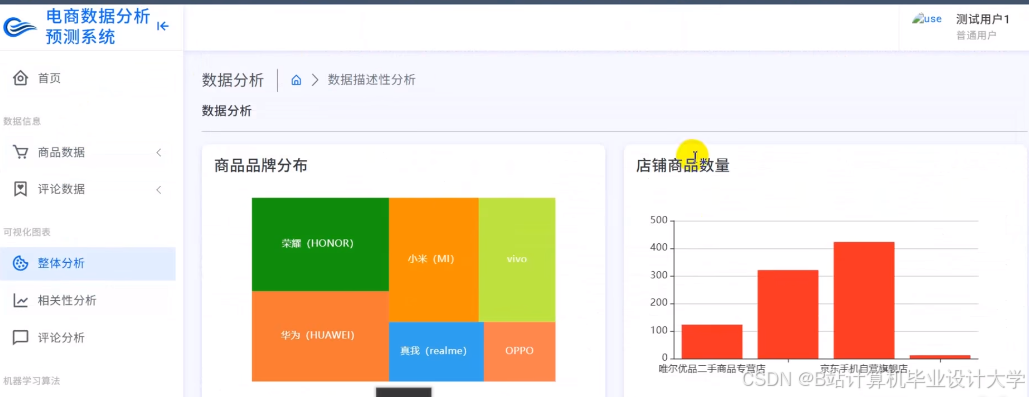
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻
更多推荐

 14
14 0
0- 0



 已为社区贡献99条内容
已为社区贡献99条内容

所有评论(0)