




- @zkkkkkkkkkkkkk
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了Celery分布式任务队列的使用方法,包括项目目录结构、配置文件编写和任务定义。主要内容有:1)使用Redis作为消息中间件;2)标准的Celery项目目录结构;3)核心配置文件示例,包含Broker配置、任务参数和定时调度设置;4)任务定义和调用方式,包括普通任务、带重试任务和定时任务;5)常用Celery命令,如启动Worker、Beat调度和任务管理命令。文章提供了完整的代码示例,
本文介绍了如何伪装Python自动化浏览器工具的特征以避免被反爬虫系统检测。主要内容包括:1)使用extract-stealth-evasions工具生成JS补丁代码,通过CDP协议注入浏览器,隐藏自动化特征;2)配合禁用自动化提示等启动参数增强伪装效果;3)针对IP限制的网站,通过浏览器插件方式实现代理认证。这些方法需要在访问目标网站前完成设置,才能有效避免被检测到自动化操作。
摘要:本文介绍了使用DrissionPage和ddddocr破解滑块验证码的方法。主要内容包括:1)滑块验证码类型(滑动缺口和滚动条);2)破解思路(确定缺口位置并计算坐标);3)两种实现方式:自动化方式(使用ChromiumPage模拟操作)和接口方式(轻量化处理);4)重点演示了ddddocr的slide_match()方法识别缺口距离,并通过坐标转换实现滑块拖动。文章还总结了ddddocr在
SyntaxError: future feature annotations is not definedImportError: cannot import name 'StratifiedGroupKFold'xgboost.core.XGBoostError: C:/Users/xxx/learner.cc:567: Check failed:mparam_.num_feature !=
目录一、介绍二、数据介绍三、flaml框架3.1、flaml简介3.2、使用flaml3.2.1、下载flaml库3.2.2、导入相关库3.2.3、数据处理3.2.4、调用flaml四、h2o框架4.1、h2o简介4.2、h2o使用...
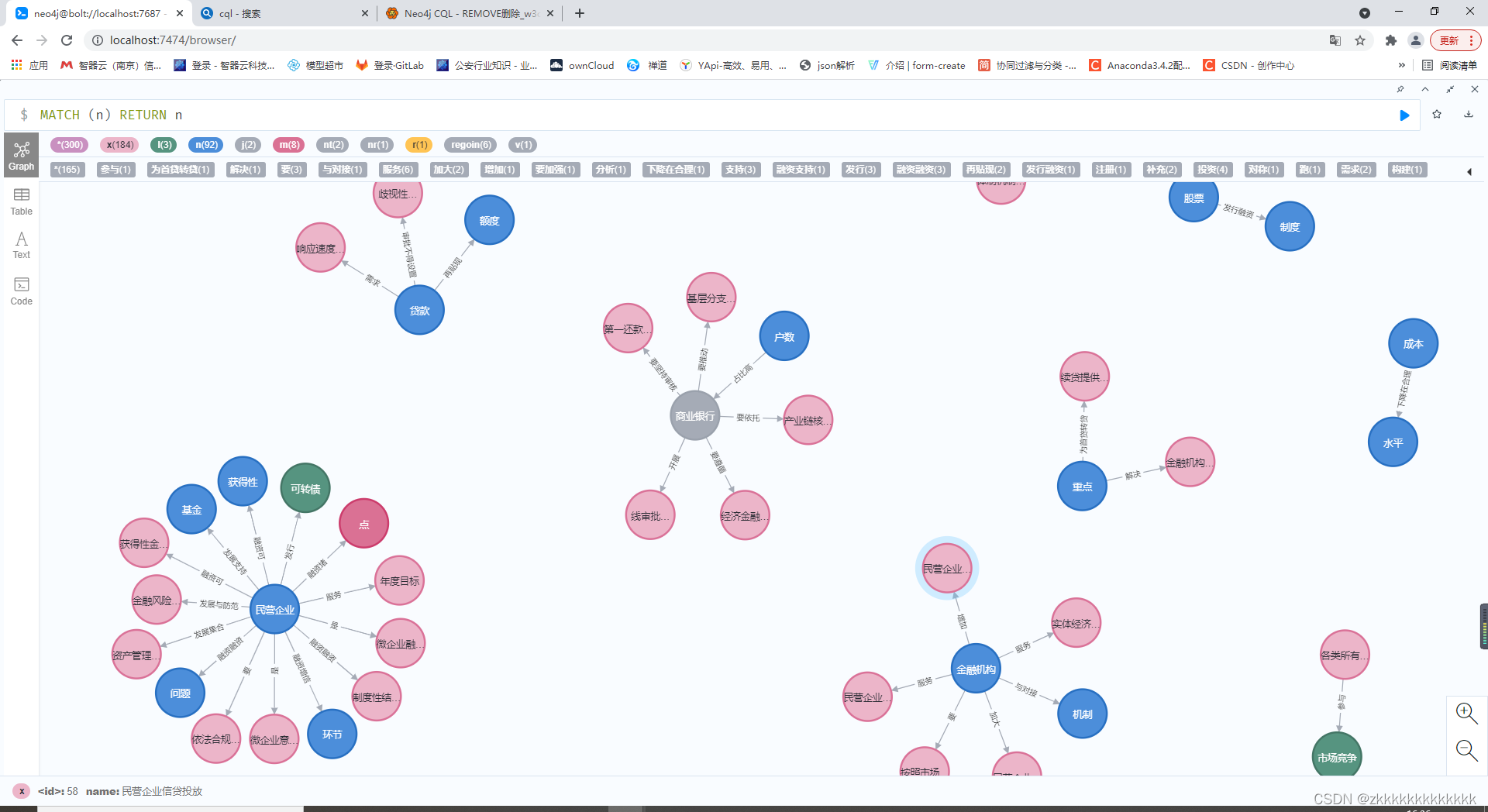
前言一、安装eno4j图数据库二、启动neo4j三、Python连接eno4j3.1、安装py2neo3.2、使用py2neo操作neo4j四、数据入库4.1、抽取三元组关系4.2、效果展示4.3、删除图库中所有实体和关系五、合并相同实体前言本文对非结构化文本数据进行解析成三元组,后写入neo4j图库。记录一些操作代码。在实际项目实战肯定是一体化...
,在新环境中pip install pyspark安装。从0开始,安装后去对应虚拟环境下的site-packages里,可以直观的看到pyspark及其依赖包。pyspark的运行需要java的支持,所以你还需要有java jdk的安装包。,下载你所需的版本的包。接着找一个盘,解压后,配置系统环境变量。安装后即可在python运行pyspark。1.2、conda新建虚拟环境安装。,进去选择版本下
Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encodingPython runtime state: core initializedModuleNotFoundError: No module named 'encodings'Current thread 0x00
python如何上传文件,使用requests的post上传文件。multipart/form-data格式上传。Content-Disposition: form-data; name="file"; filename="样本标签.xlsx"Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.shee
原因是本来使用的是具有python3.6.3版本的conda环境,但是因为python内存堆栈溢出的bug问题。在更新的过程还是有几个细节需要注意下,这边做个记录。如果升级的python版本跨度太大,则要注意一些语法或函数参数在搞版本里是否有弃用更改等情况。如果在conda install python 不指定python=多少版本,那么会默认给你安装最新的。需要注意下环境变量下的anaconda