




- @qq_35896718
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机械磁盘的读写速度一般为120m/s。固态磁盘的读写速度一般为500m/s。
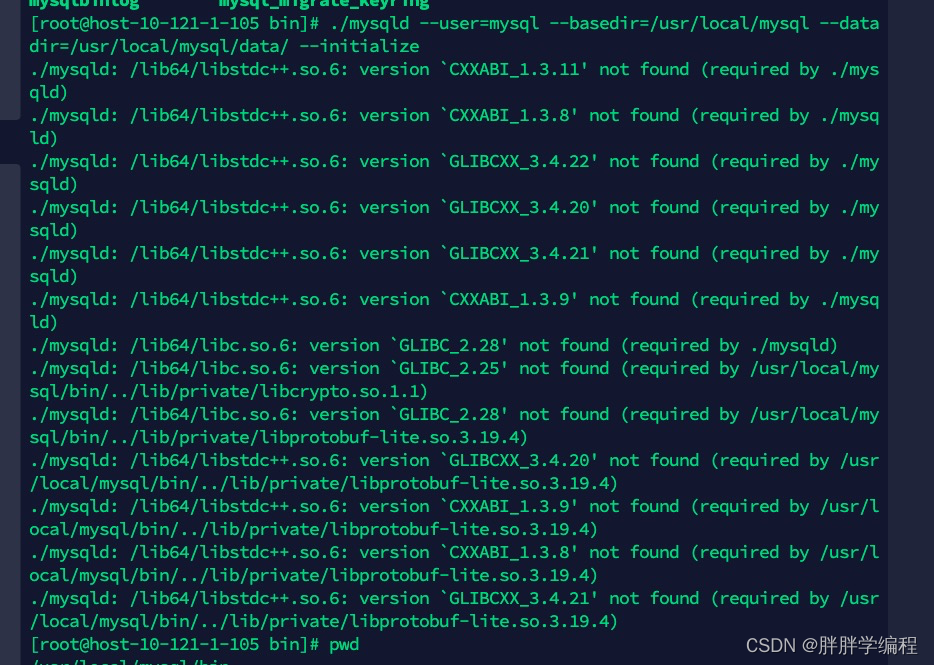
根据报错信息发现最多需要2.34版本, 因此我们需要下载2.34版本。2、安装anaconda因为这里头有这个libstdc++.so的包可以直接用。注:这个libstdc++.so.6包,新的肯定包含有旧版本,所以下载新的就行。3、找到anaconda3中的libstdc++.so包、4、将anaconda中的该包复制到/lib64目录下。5、修改软连接 ,即让这个软连接指向最新版本即可。下载需
2、在服务器登录时指定u为default在这里要指定为admin。之后在maven的package里找到这俩jar包,加到里头。直接在pom.xml加上那个lz4也是必要的不然会报错。1、要写ip而不是主机名。

raise IllegalCharacterErroropenpyxl.utils.exceptions.IllegalCharacterError 点进来,找了半天实在找不到办法..那就暴力的解决问题吧,最起码运行完了,输出结果是对的。

2)整体思路不行,我这边是两头找,前面找的是要删掉的元素,后面找的是不等于要删掉的元素值的位置,然后两者交换。fast指针:指向新数组(删除目标值之后)里需要的元素。1)没必要设置成-1,直接按照val值查找是一样的。我用好长时间才写出来,看了题解感觉他思路贼好。slow指针:需要更新的下标位置。1)用快慢指针的思路来解决问题。一、leecode题目链接。

增量导入命令执行后,在控制台输出的最后部分,会打印出后续导入需要使用的last-value,当周期性执行导入时,应该用这种方式指定--last-value参数的值,以确保只导入新的活修改过的数据。可以通过一个增量导入的保存作业自动执行这个过程,这是适合重复执行增量导入的方式。--last-value 指定已经导入数据的被检查列的最大值(第一次需要指定,以后会自动生成)--check-column

一、知识点export:将Hive的表导入到mysql叫导出搜了很多,发现sqoop在hive导出到mysql时1)不支持where参数对数据进行过滤。2)不支持指定hive表的方式导出,只能指定Hive目录进行导出。二、操作。

按两下shift即可