




- @weixin_44943389
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
(按部门、功能划分网络,如财务部、研发部各一个 VLAN)(不同 VLAN 的设备不能直接互访)合理规划 VLAN 可以让网络更。(除非通过路由器或三层交换机)。
在网络安全领域,**IDS(入侵检测系统)IPS(入侵防御系统)**就像是公司的安保系统。虽然它们长得很像,但职责和“权力”大不相同。
通过这种类比,可以更直观地理解**:DMZ是网络的“前线哨所”,内网是“后方指挥部”,防火墙是“层层关卡”,外网则是“无序的战场”**。四者协作,构建起一个既开放又安全的网络体系。(危险丛林 → 外城墙 → 交易市场 → 内城墙 → 核心宫殿)
当学习率过大时,可能导致梯度下降算法无法收敛,甚至可能发生震荡或发散,导致损失函数值不断增加而无法找到最优解。在这个例子中,学习率的初始值为0.2。如果学习率设置得太大,每次更新参数的步长就会很大,可能会越过损失函数的最小值,导致算法无法收敛。为了解决这个问题,可以尝试减小学习率,例如将其设置为 0.01 或更小的值,然后重新运行代码。的值在每个 epoch 中发生剧烈的变化,而损失函数的值并没有

将完整的数据集按照比例划分为训练集和测试集。上面的内容是完整的数据集,有关键的标签。
然而,在实际项目中,你可以结合使用 Node.js 和 Vue 来构建一个完整的应用程序。例如,你可以使用 Node.js 构建后端 API,并使用 Vue 作为前端框架来与后端交互,从而创建一个完整的全栈应用。:Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,它使 JavaScript 能够在服务器端运行。Node.js 和 Vue 是两个不同的技术,它

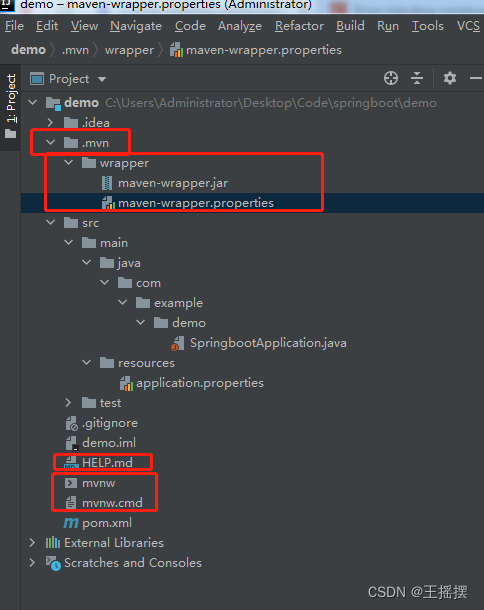
Maven Wrapper 是一个用于在项目中管理 Maven 的工具,它能够确保所有团队成员使用相同版本的 Maven,从而避免因不同版本的 Maven 导致的构建问题。Maven Wrapper 可以确保项目中的每个开发者都使用相同的 Maven 版本,从而保持构建的一致性。Maven Wrapper 会根据项目中的配置自动下载并使用指定的 Maven 版本,确保每个项目都使用相同的 Mave
GitHub的Wiki可以用于托管任何类型的文档,包括开发文档、技术文档、操作手册、用户指南等。它支持Markdown、reStructuredText等多种格式,并提供了许多功能,例如文档编辑、版本控制、评论、协作等。GitHub中的Wiki是一个基于Git版本控制系统的文档托管平台,它允许用户创建和编辑文档,并将其与特定GitHub仓库相关联。总的来说,GitHub的Wiki是一个方便的文档管

总的来说,CSV文件在机器学习和深度学习中扮演了一个重要的角色,因为它们提供了一种通用的、易于使用的方式来存储和处理数据,使得数据的获取和预处理变得更加方便和高效。然而,在某些情况下,对于大规模、高性能的系统,可能会使用更高效的数据格式,但CSV文件仍然是一个非常有用的起点。这种表格化的结构很符合机器学习模型对数据的要求。:CSV文件通常包含适当的标头(header),其中包括了每列数据的名称或特

传统的RNN中,循环神经元的权重矩阵是共享的,也就是说,在时间序列的不同时间步上,循环单元的权重是相同的。而在IndRNN中,每个时间步的循环单元都有独立的权重,因此它们之间没有共享。IndRNN(Independently Recurrent Neural Network)是一种递归神经网络(RNN)的变体,其特点是具有独立的循环权重。请注意,IndRNN是一种特殊的神经网络结构,具体的应用需要
