




- @key_honghao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
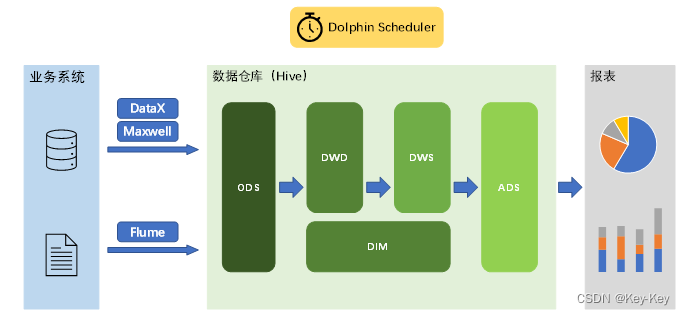
1、数据需求:用户分析日志log、业务数据db2、采集需求:日志采集系统(flume)、业务数据同步系统(Maxwell,datax)3、数据仓库建模:维度建模4、数据分析:对设备、会员、商品、地区、活动等电商核心主题进行统计,统计的报表指标接近100个。5、即席查询:用户在使用系统时,根据自己当时的需求定义的查询,通常使用即席查询工具。6、集群监控:对集群性能进行监控,发生异常及时报警。7、元数
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数据类型字段)事务事实表用来记录各业务过程,它保存的是各业务过程的原子操作事件,即最细粒度的操作事件。粒度是指事实表中一行数据所表达的业务细节程度。周期快照事实表以其规律性的、可预见性的时间间隔来记录事实,主要用于分析一些存量型(例如商品库存,账户余额)或者
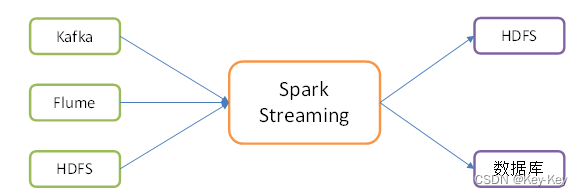
需要继承receiver,并实现onstart、onstop方法来自定义数据源采集。
1、数据需求:用户分析日志log、业务数据db2、采集需求:日志采集系统(flume)、业务数据同步系统(Maxwell,datax)3、数据仓库建模:维度建模4、数据分析:对设备、会员、商品、地区、活动等电商核心主题进行统计,统计的报表指标接近100个。5、即席查询:用户在使用系统时,根据自己当时的需求定义的查询,通常使用即席查询工具。6、集群监控:对集群性能进行监控,发生异常及时报警。7、元数
文章将介绍数据库事务的基本概念,包括事务的 ACID 属性,隔离级别的含义及其区别,脏读、幻读和不可重复读等问题。此外,你还会了解到如何通过 SQL 语句来设置事务隔离级别,以及如何处理事务的回滚和提交。文章还将涵盖如何使用保存点来部分回滚事务操作,并介绍写-写冲突和读-写冲突的概念。
文章列举了45个在计算机网络面试中常见的问题,涵盖了网络体系结构、传输层协议、网络安全等方面。这些问题涵盖了从基础到高级的各种主题,有助于面试者深入了解网络工作原理。无论是关于OSI模型的理解,还是TCP/IP协议栈的应用,都在文章中得到了详细解释。此外,文章还提供了问题的详细答案,为读者提供了备战面试的有力工具。无论是准备计算机网络面试,还是希望巩固网络知识,这篇文章都是一个不可多得的资源。
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数据类型字段)事务事实表用来记录各业务过程,它保存的是各业务过程的原子操作事件,即最细粒度的操作事件。粒度是指事实表中一行数据所表达的业务细节程度。周期快照事实表以其规律性的、可预见性的时间间隔来记录事实,主要用于分析一些存量型(例如商品库存,账户余额)或者
文章列举了45个在计算机网络面试中常见的问题,涵盖了网络体系结构、传输层协议、网络安全等方面。这些问题涵盖了从基础到高级的各种主题,有助于面试者深入了解网络工作原理。无论是关于OSI模型的理解,还是TCP/IP协议栈的应用,都在文章中得到了详细解释。此外,文章还提供了问题的详细答案,为读者提供了备战面试的有力工具。无论是准备计算机网络面试,还是希望巩固网络知识,这篇文章都是一个不可多得的资源。
按照规划,需要采集的用户行为日志文件分布在102,103两台日志服务器,故需要在102,103两台节点配置日志采集flume。日志采集flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到kafka。此处可选择taildirsource和kafkachannel,并配置日志校验拦截器。选择taildirsource和kafkachannel的原因如下:tail
1、Ganglia由gmond、gmetad和gwed三部分组成。是一种轻量级服务,安装在每台需要收集指标数据的节点主机上。使用gmond,你可以很容易收集到很多系统指标数据,如CPU、内存、磁盘、网络和活跃进程的数据等。整合所有信息,并将其以RRD格式存储到磁盘的服务。3)gweb(Ganglia Web)Ganglia可视化工具gweb是一种利用浏览器显示gmetad所存储数据的PHP前端。在
