




- @m0_52680439
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
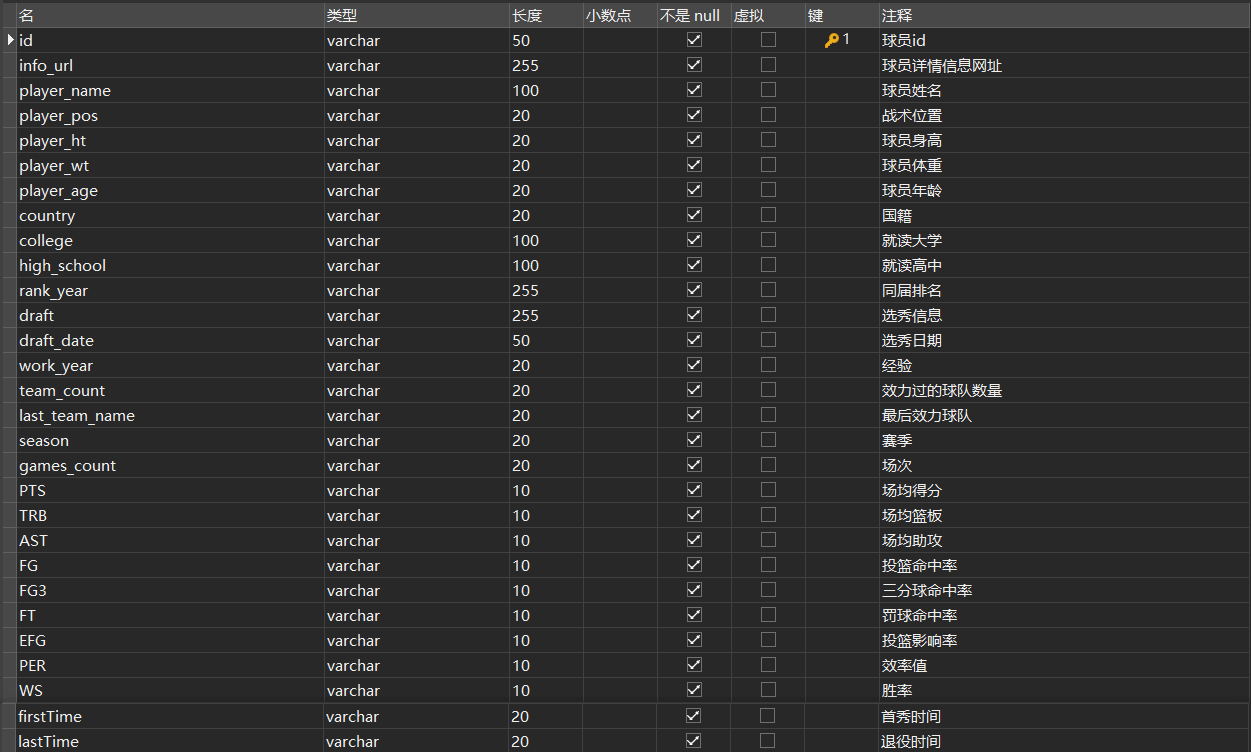
进行读取,完成清洗。升序排列,存储到 MySQL 中。结果保留两位小数,并加上单位。结果保留两位小数,并加上单位。最终将清洗完成的数据根据字段。中所有的空值补充上字符串。或空值数据替换为:数字。1英寸=2.54厘米。或空值替换为:字符串。
1.HDFS2.HDFS有两类节点用来管理集群的数据,即一个(管理节点)和多个(工作节点)。(1)namenode:管理文件系统的命名空间,维护系统数及整棵树内所有的文件和目录,这些信息以和形式永久保存在本地磁盘上。同时也记录着每个文件中各个块所在的数据节点信息,但并不永久保存块的位置信息。(2)datanode:根据需要存储并检索blocks),并且定期向namenode发送所存储的数据块的列表

1.相关方法(1)已经读取了指定的字符数, 底层流的read方法返回-1,指示文件末尾(),或者底层流的ready方法返回false,指示将阻塞后续的输入请求。(2) 如果第一次对底层流调用read返回-1(指示文件末尾),则此方法返回-1,否则此方法返回实际读取的字符数。
1.使用过滤器的步骤:(1)创建过滤器:RowFilter(CompareOperator op,ByteArrayComparable rowComparator),第一个参数接收的是比较操作对象,第二个参数接收的是条件。(2)设置过滤器。

在右侧编辑器begin-end处编写代码补全tablename为待操作表的表名,要求实现如下操作:删除表中行键为row1row2的行;获取表中行键为row3row10的行;四个操作需要依照以上先后顺序,即先删除在获取row3,row10。不需要你直接输出,只需要将批量操作的返回即可。
的整数获取数值,Series对象使用。

查询出工作职责涉及hive的并且工资大于8000的公司名称以及工作经验。