登录社区云,与社区用户共同成长
邀请您加入社区
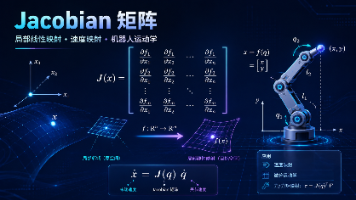
摘要: 雅可比矩阵是多变量微积分中描述向量值函数一阶导数的核心工具,由德国数学家雅可比提出。其本质是通过局部线性化近似非线性函数,广泛应用于控制科学、机器人学、数值优化、机器学习等领域。数学上,雅可比矩阵的行对应单个输出的梯度,列反映单个输入对所有输出的影响。关键运算包括雅可比-向量乘积(JVP)和向量-雅可比乘积(VJP),分别对应自动微分的前向与反向模式。雅可比与梯度、Hessian的区别在于
本文系统介绍了多元统计分析的基础知识,主要包括统计量、大数定律与中心极限定理、协方差矩阵、多元统计量等核心内容。首先阐述均值、方差、标准差等基本统计量公式,然后重点讨论切雪夫不等式、大数定律及其推论,以及中心极限定理的数学表达。在多元统计部分,详细推导了协方差矩阵的构建方法及其性质,并介绍了多元均值、方差、相关系数矩阵的计算公式。最后给出了多元正态分布的概率密度函数和行列式的数学定义。全文通过严谨
本文探讨了多线程矩阵乘法的实现原理与Python实践。文章首先介绍了线程与进程的基础概念,分析了多线程编程的优势与挑战。随后详细讲解了矩阵乘法的数学原理和分块策略,阐述了多线程矩阵乘法的并行计算原理。在实践部分,分别给出了单线程和多线程的Python实现代码,并介绍了线程安全和线程池等优化技巧。通过性能测试对比发现,多线程版本在大规模矩阵计算中可获得显著加速效果(2000x2000矩阵加速比达6.
避免频繁的小内存分配,因为`new`和`delete`操作代价较高。智能指针(如`std::unique_ptr`, `std::shared_ptr`)能有效防止内存泄漏,但需注意`std::shared_ptr`的控制块开销和原子操作成本。例如,在需要频繁查找的场景下,`std::unordered_map`(平均O(1)复杂度)通常优于`std::map`(O(log n)复杂度)。例如,G
C++作为一门“全能型”编程语言,其核心技术包括面向对象编程(OOP)、模板机制和内存管理策略,这三者共同构成了其高效、灵活与复杂的底层逻辑。- 封装(Encapsulation):通过类(Class)将数据与其操作绑定,隐藏内部实现细节,提供接口对外暴露功能。- 二进制兼容性(ODR-violation):模板定义必须与声明处于同一翻译单元(如头文件)。
+j) { // 隐藏循环展开。| 网络包缓存 | 3.2M ops/s | 12.8M ops/s | 337%|| FIFO队列| 78%| 284μs|| 实时渲染节点 | 1.1M/s| 9.6M/s| 845%|| 工作窃取| 99%| 32μs|| 场景 | 原始new/delete | 内存池方案 | 性能提升 || 数据量 | 传统循环 | AVX优化 | 加速比 |
原文:towardsdatascience.com/calculating-the-uncertainty-coefficient-thiels-u-in-python-fce72a02431b?·发表于·6 分钟阅读·2024 年 10 月 18 日。
URDF (Unified Robot Description Format) 是一种 XML 格式,用于描述机器人的结构信息,包括:机器人正向运动学的目标是给定关节向量 q=[q1,q2,...,qn]Tq = [q_1, q_2, ..., q_n]^Tq=[q1,q2,...,qn]T,计算末端执行器(End-Effector)在基座坐标系下的位置和姿态。如果机器人由 nnn 个关节和
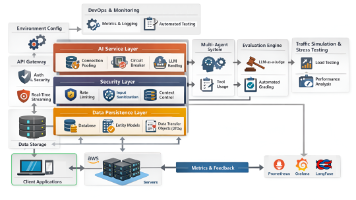
现代的 agentic AI systems(代理型 AI 系统),无论运行在 development、staging 还是 production 环境中,都应构建为一组职责明确的 architectural layers(架构层),而非单一服务。每一层分别负责 agent orchestration、memory management、security controls、scalability、
本文通过Python模拟实验,直观展示了大数定律和中心极限定理在伯努利、均匀和指数三种分布中的表现。通过100万次实验验证,揭示了样本均值如何收敛于理论值(大数定律)以及样本均值分布趋近正态分布(中心极限定理)的统计规律,为数据分析和机器学习提供实践基础。
本文提出了一套基于超复数广义分形流形的统一理论框架,将数学物理、量子场论、粒子物理、弦论、中微子物理、生命科学、人工智能等多个领域整合在一个几何体系中。该理论包含10个具有诺贝尔奖潜力的突破性主题,每个主题都提出了原创性数学工具并解决了相应领域的核心问题,包括:建立了无界广义豪斯多夫维数公理体系;给出了精细结构常数的几何闭式解;通过代数退化链解释了标准模型粒子谱;精确计算了缪子反常磁矩;揭示了26
本文摘要: 该研究提出了一套基于超复数广义分形流形的统一理论框架,将现代物理学多个前沿领域的关键问题纳入几何化描述体系。核心创新包括:1)建立无界广义豪斯多夫维数公理体系;2)给出精细结构常数的几何闭式解;3)通过代数退化链理论推导出64种基本粒子态;4)精确计算缪子反常磁矩;5)解释26维弦论的自洽性;6)预测中微子混合角θ13=π/21;7)揭示《易经》六十四卦与32维流形的拓扑同构;8)构建
本文提供了一份详细的C++教程,指导如何复现CCPC竞赛中的'太阳轰炸'概率题。从数学建模、概率公式推导到模运算的避坑技巧,再到完整的代码实现,逐步解析如何将理论转化为AC代码。特别强调了模运算中的常见错误和正确处理方法,适合算法竞赛选手和编程爱好者学习参考。
本文通过Python代码可视化大数定律和中心极限定理,帮助读者直观理解这些概率论核心概念。使用NumPy和Matplotlib进行蒙特卡洛模拟,展示了样本均值如何收敛到期望值,以及不同分布随机变量和的分布如何趋近正态分布。文章包含实际应用案例和常见误区分析,是数据科学学习者的实用指南。
本文教你如何用Python的NumPy和SciPy库快速计算离散与连续概率模型,告别繁琐的手工计算。通过实战示例展示概率质量函数(PMF)、累积分布函数(CDF)和概率密度函数(PDF)的高效实现,帮助数据科学学习者将概率论理论转化为可执行的代码解决方案。
本文通过Python的NumPy和Pandas实战演示,帮助读者直观理解概率论中的期望、方差与协方差概念。通过构建虚拟班级成绩数据集和股票投资组合分析案例,展示了这些统计量在实际数据分析中的应用价值,特别适合数据分析师和机器学习工程师提升基础统计能力。
本文通过几何投影的视角,直观解释了条件期望E(X|Y)的核心概念,帮助读者摆脱死记公式的困境。结合Python代码验证,展示了条件期望在离散和连续随机变量中的应用,并探讨了其在机器学习中的实践意义。这种几何类比不仅简化了理解,还揭示了条件期望与线性回归、决策树等方法的深层联系。
本文通过几何视角解析条件期望,将其视为概率空间中的投影操作,帮助读者直观理解这一概率论核心概念。文章结合Python代码示例,展示了如何用投影思维替代死记硬背,并详细讲解了条件期望的五大性质及其在实际应用中的计算方法,包括非参数估计和参数化方法。
本文通过Python代码和动态图表,直观演示了大数定律与中心极限定理在概率论中的应用。从掷骰子实验到不同分布的收敛速度对比,再到蒙特卡洛模拟计算π值,帮助读者摆脱死记硬背,真正理解这些核心统计概念。文章还提供了质量控制等实际应用案例,并揭示了样本量不足和相关性对定理的影响。
本文通过Python的NumPy和Matplotlib库,详细展示了如何可视化理解离散型与连续型概率分布。从二项分布、泊松分布到正态分布、指数分布,结合代码实例和交互式可视化,帮助读者直观掌握概率密度函数和概率分布函数的核心概念,提升数据科学中的概率论应用能力。
本文通过Python可视化技术,生动解析概率密度函数(PDF)与分布函数(CDF)的数学概念,结合Matplotlib和Seaborn实现动态图形展示。从离散型到连续型概率分布的对比,到微积分关系的可视化验证,帮助读者直观理解概率论核心知识,并提供完整代码示例。
在概率论与统计学中,非传递性关系是一个深刻且反直觉的概念,它描述了类似“石头剪刀布”的循环相克现象,即A优于B、B优于C,但C却优于A。其核心原理在于通过精心设计随机变量的概率分布,操纵其均值与方差的对比关系,从而在成对比较中构建出稳定的概率优势循环。这一原理在机器学习模型评估、博弈论策略设计及决策理论中具有重要价值,它警示我们,在涉及多重比较的复杂系统中,简单的线性排序可能失效。本文以布拉德利·
摘要: 本文探讨AB实验中随机化(Randomization)的核心作用及样本比例失衡(SRM)的危害。随机化是确保实验组与对照组同质性的关键,为因果推断构建“平行宇宙”。然而,工业实践中分流错误、数据丢失等问题常导致SRM(如预期50:50,实际40:60),引发严重偏差。例如,策略导致部分用户崩溃且数据未上报,造成“幸存者偏差”,使结果失真。检测SRM需优先通过卡方检验验证样本比例(P<
多元正态分布描述多维连续数据;正态逆维希特分布作为其共轭先验,提供了一种动态更新均值向量和协方差矩阵联合信念的机制;这种关系简化了贝叶斯推断的计算,使得在观测数据后,后验分布仍能保持解析形式,便于实际应用(如金融建模、机器学习等)。
一、
典型相关分析是研究两组变量之间相关关系的一种多元统计方法。它能够揭示出两组变量之间的内在关系在一元统计分析中,用相关系数来衡量两个随机变量之间的线性相关关系;用复相关系数研究一个随机变量和多个随机变量的线性相关关系。然而,这些统计方法在研究两组变量之间的相关关系时却无能为力。比如要研究生理指标与训练指标的关系,居民生活环境与健康状况的关系,人口统计变量(户主年龄、家庭年收入、户主受教育程度)与消费
参考资料:电子工业出版社的《深入浅出统计学》前言利用样本准确地预测总体,并以一定方式说明预测结果的可靠程度,通过样本了解总体,并学习如何反过来通过总体了解样本。本篇目录参考资料:电子工业出版社的《深入浅出统计学》前言具体内容一、总体均值的估计二、总体方差的估计三、比例的抽样分布1、比例分布的期望和方差2、比例分布的概率计算四、均值的抽样分布1、均值分布的期望和方差2、均值分布的概率计算五、中...
目录概率论基础条件概率排列组合全概率公式贝叶斯法则贝叶斯意义概率论基础概率论与数理统计是研究什么的?随机现象:不确定性与统计规律性概率论:从数量上研究随机现象的统计规律性的科学数理统计:从应用角度研究处理随机性数据,建立有效的统计方法,进行统计推理条件概率加法公式:若事件A与B互斥,则P(A⋃B)=P(A)+P(B)P(A\bigcup B) = P(A) + ...
缘由:在学习深度学习入门:基于Python的理论与实现时,没有看懂第四章交叉熵误差函数,当监督数据采用非one-hot表示时。所以做了一个小测试案例,终于明白了,花了我几个小时的时间,学习不能着急呀。一、结果和细节分析注:使用mnist手写数字体数据集。(1)、交叉熵误差函数输入数据只有一个时:y和t都是1*n的矩阵,只需要求一行的相应和就可以得到这个数据对应的误差。采用mini_batch批处理
对于分布函数的形式已知,对于其中的未知参数,应用样本X1、X2…Xn所提供的信息去对其一个或者多个未知参数进行估计,这类问题称为参数估计问题。参数估计在机器学习中的应用最为广泛。接下来就做一个简单的介绍学习。一、矩估计设θ1,θ2,...θk\theta _1,\theta _2,...\theta _kθ1,θ2,...θk为待估参数,X1,X2,...XnX_1,X_2,...X...
主要介绍了医学统计学中的样本均数和样本率的抽样分布
统计学习方法(第二版)第一章学习笔记目录统计学习方法(第二版)第一章学习笔记废话在前明确目的极大似然估计的假设前提贝叶斯估计的假设前提先验概率、后验概率废话在前 本文的名字虽叫学习笔记,但是并不是记录统计学习方法的详细笔记,而只是对一些难以理解的知识点提出自己的一些尚不成熟的看法。 第一章主要是一些基本概念,第一章的两道习题都是关于贝叶斯估计和极大似然估计的,在读到这两个估计方法的时候(包
目录一、估计量与估计值二、评估统计量的标准三、点估计四、区间估计一、估计量与估计值1.估计量:用于估计总体参数的随机变量如样本均值、样本比例、样本方差等例如:样本均值就是总体均值μ的一个估计量2.参数用θ表示,估计量用表示3.估计值:估计参数时计算出来的统计量的具体值如果样本均值x拔=80,则80就是μ估计值二、评估统计量的标准1.无偏性:估计量抽样分布的数学期望等于被估计的总体参数。设总体参数为
贝叶斯决策、判别函数笔记
参数点估计背景:研究统计量的性质和评价一个统计推断的优良性,完全取决于其抽样分布的性质统计推断的基本问题(1)参数估计问题:总体X的分布函数的形式已知,但它的一个或多个参数为未知,需要借助于X的样本来估计它们(2)假设检验问题:总体X的分布函数的形式完全未知,或只知其形式,但不知其参数,为了推断总体的某些未知特性,提出某些关于总体的假设参数估计问题实现过程:假定总体分...
大题1-三门炮,同时向敌机发射,射中概率相互独立且分别为0.5,0.6,0.4,敌机被一门炮击中坠落的概率为0.5,被两门及以上的炮击中坠落概率为1,(1)求敌机坠落概率(2)求已知敌机坠落,A击中的概率。填空题4-已知P{X+Y=1}=0.5,P{X=0}=a+0.3,P{X=0,Y=1}=a,且X=0与X+Y=1相互独立,求a(概率以X-Y二维离散分布律形式给出-0.3、a、b、0.2)计算机
本文详细介绍了马尔可夫链的概念和原理。
概率论
——概率论
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI Agent技术社区
AI Agent技术社区






 脑启社区
脑启社区


















