




- @Barok
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DemoGen技术通过全合成演示生成框架,实现机器人从单次人类演示中"举一反三"。其核心利用任务与运动规划(TAMP)和3D点云编辑,将演示分解为运动段和技能段,通过算法生成适应不同位置的虚拟数据。实验显示,仅需1次演示生成的100-200条合成数据,即可达到25次人类演示的效果(成功率88%),降低20倍数据采集成本。该技术支持单/双臂操作,在抓取、搬运等任务中展现出色泛化能力,且生成速度达0.

具身智能(Embodied Intelligence)是将人工智能(AI)与物理实体结合,使机器不仅能在数字世界中“思考”,还能在现实世界中“行动”的一种技术范式。从自动驾驶汽车到智能机器人助手,具身智能正在改变我们与技术的互动方式。随着技术的飞速发展,这一市场被认为有望成为下一个万亿级产业。根据国际数据公司(IDC)的预测,到2030年,具身智能市场规模可能达到1.5万亿美元,年复合增长率(CA

CangjieMagic是一个突破性的LLM Agent开发平台,基于仓颉编程语言构建。作为首款此类平台,它引入了新颖的Agent DSL(领域特定语言)架构、原生支持MCP(可能是“Magic Communication Protocol”)通信协议,以及高级智能规划功能。CangjieMagic于2025年3月开源,标志着智能Agent开发领域的一次重大飞跃,为开发者提供了一个强大而灵活的框架

一文带你吃透具身智能产业链

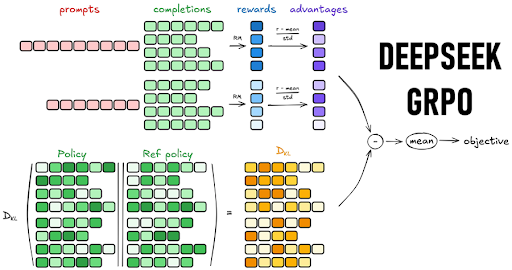
Group Relative Policy Optimization(GRPO)是一种新型的强化学习算法,由DeepSeek提出,旨在提升大语言模型(LLMs)在推理任务中的表现。它基于近端策略优化(PPO)框架进行改进,通过独特的奖励机制和策略更新方式,使模型在训练过程中能够更有效地学习和优化策略,从而增强模型的推理能力和性能。与传统的强化学习算法不同,GRPO在训练过程中摒弃了价值网络,采用组
CangjieMagic是一个突破性的LLM Agent开发平台,基于仓颉编程语言构建。作为首款此类平台,它引入了新颖的Agent DSL(领域特定语言)架构、原生支持MCP(可能是“Magic Communication Protocol”)通信协议,以及高级智能规划功能。CangjieMagic于2025年3月开源,标志着智能Agent开发领域的一次重大飞跃,为开发者提供了一个强大而灵活的框架
一文带你吃透具身智能产业链
显卡寡头老大的下一步,瞄准了所有智能机械设备上的显卡。

具身智能(Embodied Intelligence)是将人工智能(AI)与物理实体结合,使机器不仅能在数字世界中“思考”,还能在现实世界中“行动”的一种技术范式。从自动驾驶汽车到智能机器人助手,具身智能正在改变我们与技术的互动方式。随着技术的飞速发展,这一市场被认为有望成为下一个万亿级产业。根据国际数据公司(IDC)的预测,到2030年,具身智能市场规模可能达到1.5万亿美元,年复合增长率(CA
第一课:ELBO和VAE