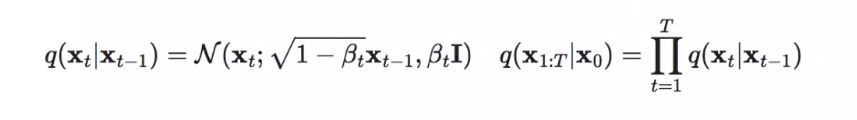登录社区云,与社区用户共同成长
邀请您加入社区
ChatGPT推出"即时结账",用户可在对话内直接下单。独立站卖家该如何让AI读懂、推荐自己?
AI编程越自动化,开发者越需要在目标确认、架构选择、权限变更、验证审查和生产发布等关键节点保留人工判断。本文围绕ChatGPT、Codex与Pro,分析为什么自动执行不能替代工程责任,以及程序员如何从代码执行者转向AI任务的决策者与治理者。
AI任务失败后,连续重试可能让错误进一步扩散。本文从失败分类、停止条件、结果保留、修改回退、状态更新和重新规划等角度,分析ChatGPT、Codex与Pro背后的失败恢复工程,以及开发者为什么需要为复杂AI任务设计可靠的恢复路径。
你可能每天都在用聊天机器人——ChatGPT、文心一言、Kimi……但最近"Agent"这个词冒出来的频率越来越高。很多人觉得:"这不就是更聪明的聊天机器人吗?"
当ChatGPT与Codex进入真实开发流程,AI能够调用工具并不代表能够正确完成任务。本文从工具选择、调用顺序、参数边界、结果解释和失败停止等角度,分析Plus与Pro支持下的工具调用工程,以及开发者为什么需要为AI设计清晰、有限、可验证的执行链。
当ChatGPT与Codex进入真实开发流程,AI完成了什么、为什么这样执行,正在变得越来越难追踪。本文从工具调用、任务状态、决策依据和验证结果等角度,分析Pro支持下的AI可观测性工程,以及开发者为什么需要为每次AI执行建立完整、可审查的工程轨迹。
当ChatGPT与Codex进入真实开发流程,模型能力越强,读取、修改和执行范围越需要受到控制。本文从读取权限、修改权限、命令权限和决策权限等角度,分析Plus与Pro支持下的AI权限工程,以及最小权限原则为什么会成为AI开发系统的重要基础。
同一模型在不同项目中可能产生完全不同的工程结果,关键不只在模型能力,还在任务规格、工具权限、反馈循环、停止条件和人工审查。本文围绕ChatGPT、Codex与Pro,分析Agent Harness如何把AI能力组织成可执行、可验证、可控制的开发系统。
ChatGPT与Codex能够保留大量对话和项目上下文,却仍可能重复执行、忘记进度或沿用失效结论。本文从任务阶段、状态更新、失败处理和人工确认等角度,分析Plus与Pro支持下的AI状态工程,以及开发者为什么需要为长任务建立清晰的状态管理机制。
当ChatGPT与Codex进入真实开发流程,上下文越长并不一定越准确。本文从目标边界、文件范围、状态变化、决策覆盖和信息压缩等角度,分析Plus与Pro支持下的上下文工程,以及开发者为什么需要从“提供更多信息”转向“管理有效信息”。
当ChatGPT与Codex进入真实开发流程,代码能够运行已不等于可以直接合并。本文从需求一致性、异常场景、回归测试、测试可信度和人工审查等角度,分析Pro支持下的AI验证工程,以及开发者为什么需要为每次代码合并建立完整证据链。
当ChatGPT与Codex进入真实开发流程,AI编程的核心能力正在从提示词优化转向任务编排。本文从目标边界、执行顺序、上下文范围、验证标准和回退机制出发,分析Plus与Pro如何支撑不同强度的人机协作,以及开发者为什么需要从代码执行者转向AI任务设计者
ChatGPT、Codex、Plus与Pro正在形成不同分工:ChatGPT负责分析与任务拆解,Codex负责工程执行,Plus和Pro对应不同使用强度。本文从开发工作流、上下文管理、任务边界和工程组织能力出发,分析AI编程从代码生成走向系统化协作的变化。
我做这东西,起因特别朴素:我觉得跟 AI 聊出来的东西,不该是一次性的。你熬半小时调通的代码、花二十分钟让它帮你理顺的思路、改了五版才肯发的文案,这些值得被存住、被翻到、被下次接着用,而不是关个标签页就没了,或者哪天号一封、两个月白聊。测完这一圈,我的结论是:现有工具各有各的硬本事,Chat Memo 的管理、Superpower 的工作台、personal-ai-memory 的召回,我都服,但
本文探讨了使用Codex升级项目依赖时可能遇到的问题及解决方案。主要建议包括:不要盲目升级所有依赖,应分批处理;保留Lock文件避免环境差异;明确限制Codex修改范围;升级后必须进行完整回归测试。文章提出了六步流程:先分析依赖关系、分批升级核心依赖、谨慎处理Lock文件、限定修改范围、全面验证、评估升级必要性。强调依赖升级不是简单修改版本号,而是需要系统性的分析和验证过程,Codex可作为辅助工
跨境订阅支付方式实测:虚拟卡解决 ChatGPT / Claude 付款难题
本文针对前端项目常见的登录认证和权限控制问题,提出系统性解决方案。通过分析完整的认证链路(Token存储、用户状态恢复、路由守卫等),指出三个关键排查点:刷新后状态丢失、权限判断过早、前端权限控制不足。强调修改应严格限定范围并补充回归测试,同时提醒不能仅依赖前端隐藏菜单实现权限控制。文章还提供了Pro版使用场景建议,帮助开发者高效解决登录跳转、权限丢失等问题,同时确保系统安全性。
《Codex多仓库开发优化指南》针对AI编程工具在跨项目协作中的上下文混淆问题,提出系统解决方案:1)按仓库划分独立任务并确认技术栈;2)建立AGENTS.md记录项目规范;3)实施"仓库身份确认"流程;4)单任务聚焦单一问题;5)GitDiff审查修改边界。通过结构化流程设计,有效降低项目规则串线风险,同时提供适用于不同使用强度的版本选择建议。关键措施包括任务隔离、规范文档化
ChatGPT付款后仍然显示Free,不一定代表订阅失败。本文围绕订单状态、登录账号、网页与App订阅入口、恢复购买和状态同步,整理5个常见排查方向。
摘要:Codex在修复复杂Bug时需要多步骤操作,额度不足会影响效率。ChatGPT Plus/Pro用户可购买Codex Credits补充使用量。临时性需求(如偶发布版本排查)适合补充Credits,而高频使用(如日常多项目维护)则建议升级Pro。使用前建议优化任务范围,避免无效消耗。本文对比了两种方案的适用场景,并给出额度管理建议。(149字) 关键词:Codex额度、Codex Credi
文章摘要:Codex修复复杂Bug时若频繁触发限制,需根据使用频率选择方案。短期高峰需求适合灵活补充Credits,而高频使用场景(如每日调试)则建议评估Pro版本以减少中断成本。关键要区分使用场景:偶发问题补Credits,持续中断需统计消耗,长期调试考虑升级Pro。同时应优化任务范围,避免无效消耗。核心在于判断任务中断是否影响项目交付效率。(149字)
摘要:本文探讨开发者同时维护多个项目时如何选择ChatGPT服务方案。当Codex作为固定开发工具频繁使用时,需要评估Plus和Pro版本的适用场景:Plus适合偶尔项目切换或月底集中更新,可通过补充Credits应对短期超额;若每日需多仓库操作、文件修改、测试调试等高频使用,Pro版更合适。关键判断标准是额度限制是否影响开发流程。建议优化项目管理,为每个仓库建立技术文档(AGENTS.md),避
摘要:处理Codex额度不足时,Credits适合偶发性需求(如临时赶项目),而Pro套餐更匹配长期高频使用场景(如日常开发工具)。选择依据应参考月度使用强度:偶尔超限选Credits灵活补充,频繁中断则Pro更高效。注意任务拆分优化也能缓解额度压力。
更换梯子的节点,某些节点会出现这个问题,换个国家的节点即可。
Keywords: simple这些公式是针对状态空间模型中的一个重要概率分布,即高斯分布(也称为正态分布)的一般形式。在状态空间模型中,高斯分布用于描述系统状态的不确定性,并且通常假定其满足马尔科夫性质,即当前状态只依赖于前一个状态。在这个公式中,假定状态满足马尔科夫性质,即当前状态只依赖于前一个状态,因此。表示根据前一个状态的值,生成当前状态的概率密度函数,这个概率密度函数是一个由。个条件概率
文章摘要:开发者对比了TD组合与CC组合(Codex+ChatGPT5.6sol)在开发跨平台文件朗读应用时的表现。CC组合展现出更强的问题识别能力,自动检测需求文档不一致并澄清模糊点,严格遵循MASE框架,主动优化开发流程(如MVP策略、并行任务分配),并提升代码质量(3500行有效代码+5400行测试代码)。其健壮性、变更管理能力和跨平台适配效率(macOS/安卓一次通过)显著优于TD组合,被
ChatGPT
——ChatGPT
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AtomGit AI 社区
AtomGit AI 社区




 智能体开发者社区
智能体开发者社区









 AI编程社区
AI编程社区