- @yangyin007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
智能体是一类能够感知环境、独立决策并采取行动以达成目标的系统或程序。自主决策:能够主动分析任务,规划策略并动态调整执行方案多工具协作:可整合多种模型、API和外部工具完成复杂任务持续优化:通过交互和反馈不断改进性能智能体的出现,使AI系统不再只是被动工具,而成为可以协助、替代甚至超越人类完成特定任务的自主系统。初创企业/个人开发者:Coze、n8n,快速验证想法企业级应用开发:Dify、LangC

本篇文章我们从0到1实战了从部署k8s集群,到训练一个CV算法模型的小案例,不仅掌握了构建集群和训练CNN模型的基本流程,还学习了如何评估使用模型进行推理,帮助将来使用的时候得心应手。K8S工具功能强大,如何进行计算资源分配,限制,调度等延伸能力,感兴趣的同学可以继续往下深究,如何训练模型,使用模型这些技能都是CV算法工程师的基础能力,若感兴趣可以在案例的基础上进行延伸扩展,试试模型优化参数调优。
这套监控功能还是挺强大的,就是Prometheus的表达式有点多。附上几个链接:Prometheus官方文档Grafana官方文档代码地址。
这并非指模糊的“AI 会帮你写代码”,而是指那些枯燥的日常工作,例如:“哪里出错了”、“哪里发生了变化”、“哪些需要我审核”、“这个 PR 添加了测试吗”以及“为什么流水线失败了”。你也可以在这里进行基本的分类。它不应该“批准所有内容”,而应该总结变更内容,指出风险,并指出明显的疏漏,例如“未更改任何测试”或“此更改涉及身份验证”,然后由您决定如何处理。从更高层来看,你希望助手能够进行轻量级的问题
例如,如果您配置了 Telegram 机器人令牌,所有三个网关副本都将拥有相同的令牌,但 Telegram 一次只能将消息发送到一个活动的 Webhook 端点。一台配置良好的单台 VPS,配合 systemd、完善的监控和定期备份,就能处理绝大多数实际工作负载,而无需 Kubernetes 那样复杂的运维。中讨论的高级内存后端(QMD、Cognee、Mem0),则这些服务应该各自拥有独立的持久性
在这之前,我从未用过mcp,只用过最原始的 vs code插件,codex gemini Claude 的官方插件。我的claude 是 官网pro订阅(Google pay付款),codex是 一刀gpt team (贝宝付款)以下教程基于mac的vs code,如果你是windows,那么这个教程并不适用。简单说一下需要什么:算了,什么都不需要,需要一颗探索的心。慢慢摸索,通宵在我的mac上面
当需要信息时,将当前查询也转化为向量,在向量数据库中进行相似性搜索(Similarity Search),找到最相关的记忆片段,并注入到当前 Prompt 中。记住之前的对话上下文,避免用户重复信息,使 Agent 具有状态,能够跨越多次交互保留和回忆信息。它们一个管“当下”,一个管“过去”,相互协作,共同构成了Agent完整且强大的记忆能力,并且。,将详细的短期记忆压缩成简洁的长期记忆要点存入向
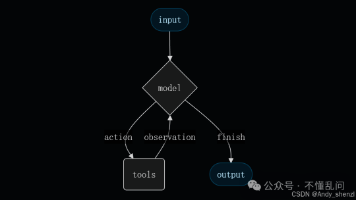
规划模块是AI Agent的“大脑决策中心”,负责将复杂任务分解为可执行的子任务序列,并动态调整执行策略。它使Agent能够处理多步骤、需要推理的复杂问题。
LangChain 在 1.0 版本中,将所有 Agent 的创建方式统一为了一个入口——create_agent()。它取代了旧版本中的 create_react_agent、create_json_agent、create_tool_calling_agent 等多种分支函数,真正让开发者用一行代码即可创建任何类型的智能体。在 LangChain 0.x 时代,框架内的 Agent 系统经历了
不仅实现了对微信群内关键内容的快速抓取,还能精准总结特定成员在某段时间内的发言,真正解决了“重要内容被埋没”的痛点。目前通义千问 Qwen3 模型不仅可以在阿里云百炼平台上直接体验模型,智能体和工作流内也已接入 Qwen3 模型,可以将 Qwen3 结合知识库,插件,MCP 能力,创建更强大的 AI Agent。可以看到,他先调用了时间,然后再群聊中筛选了记录,成功的总结了大佬的语录,并且进行了一