




- @no2454410
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
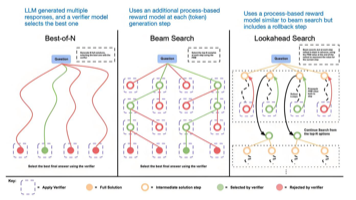
SGLang 与 vLLM 并非替代关系,而是同源互补的推理框架:vLLM 擅长通用高并发推理,是简单对话场景的高效选择;SGLang 聚焦复杂结构化任务,通过前端 DSL 与 RadixAttention 技术,实现“可编程性+高效性”的统一,是 Agent 等复杂 LLM 应用的最优解。
很多人误以为OpenClaw是“新的聊天AI”,实则它的定位是「开源、自托管的AI Agent系统」——简单说,它不是“只会聊天的大脑”,而是“能自主干活的数字员工”,核心是让AI从“问答工具”升级为“执行工具”。权威求证渠道:OpenClaw官方GitHub仓库(可直接检索项目源码及文档)、官方发布的《OpenClaw橙皮书v1.0》(涵盖架构、部署、生态全内容,适配版本v2026.3.7)。核
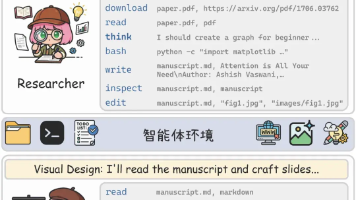
因为当 Claude Code 开始复用你的工作流,它就不再只是一个会听命令的助手,而更像一个逐渐熟悉你做事方式的同事。解决网页执行、解决信息压缩、解决技能发现、解决工作流沉淀、解决长会话控制,testing / docs / refactor / git / research 这些,则是在把 Claude Code 从“会写代码”推向“能承担完整工作流”。但用久了你会发现,真正把人和人拉开差距的
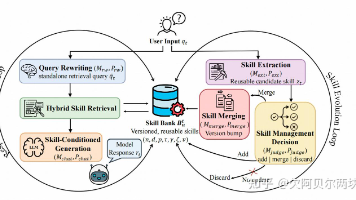
AutoSkill 的框架,由两个紧密耦合的过程组成。右侧循环,技能演化,通过提取和维护将交互经验转化为显式技能。左侧循环,技能增强响应生成,利用当前技能库通过查询重写、技能检索和上下文注入来支持响应生成。通过这种方式,系统通过显式记忆增长而非模型微调来持续改进。其中表示第轮的用户查询, 表示模型回复。英文GPT-3.5子集表现最优:10,243个对话生成631个技能,平均每对话26.13条消息。
以往的模型不知道自己生成的排版长什么样。更重要的是,所有生成内容均为 .pptx 可编辑格式,支持自由修改与二次创作,彻底摆脱类似 nanobanana 那样 “生成后无法编辑” 的困扰,让 PPT 创作真正可控、高效、灵活。更值得关注的是,在成本 — 性能曲线中,DeepPresenter-9B 位于前沿的 “突变点” 位置,意味着在性能与价格之间达到了极具竞争力的平衡。,实现了同等级别的智能表
FinGenius 基于 Python 语言构建,运用了先进的专家系统技术,能够对复杂的 A 股市场数据进行深度分析与解读。从技术架构来看,它整合了多个关键组件,形成了一个有机的智能决策系统。其核心在于通过一系列精心设计的算法,实时抓取并处理来自各大金融数据源的海量数据,包括股票价格走势、成交量、公司财报数据以及宏观经济指标等。在处理这些数据时,FinGenius 利用多智能体技术,模拟了 6 位

RAGFlow全面接入MinerU 2.0,通过pipeline、vlm-transformers、vlm-sglang三种解析模式的灵活适配,不仅解决了复杂文档解析的精度瓶颈,更通过架构层面的深度整合,降低了企业级RAG应用的落地门槛。对于开发者而言,这一升级意味着无需再为文档解析环节单独选型、开发适配代码,可直接基于RAGFlow构建端到端的高精度RAG系统。后续RAGFlow还将持续优化Mi
李飞飞出书《我看见的世界》是最近李飞飞开公司拉投资了,需要宣传吧,去B站搜署名李飞飞的AI课程,基本都是李飞飞的学生主讲,李飞飞本人唯一露脸的只有一节课,仍旧是只谈人工智能的历史,学术问题不涉及,也就是说,她那个团队干活的是学生,但名头都是打她的名字,这是很不正常的,业界应该都知道是怎么回事,她是学术界,有斯坦福给她背书,但如果是工业界,她之前短暂被谷歌聘用过,后面就没有续了。至于物理学出身的李飞

思维链最初是大模型预训练中的 “意外发现”:当要求模型解数学题时 “step by step” 思考,其正确率会显著提升。这一现象与 “上下文学习”(In-context learning,模型无需训练就能通过任务指示和示例掌握新任务)共同成为大模型智能涌现的标志性特征,最初让学界和业界颇为震撼。大模型的数学与逻辑能力薄弱,是用户普遍反馈的问题。这一短板严重制约了大模型的商业化落地 —— 人们难以
算力计算的核心是“拆解硬件运算单元数量×单位时间运算次数”,CPU与GPU的差异本质是架构设计的差异(通用vs并行),导致算力差距悬殊。实践中需注意:先明确场景:科学计算看FP32算力,AI训练看FP16/TF32算力,AI推理看INT8算力;获取官方参数:核心数、频率、运算单元数量等必须来自厂商官方文档;结合实际场景修正:通过工具实测(如Linpack、TensorRT)获取实际可用算力,避免仅
