登录社区云,与社区用户共同成长
邀请您加入社区
1.使用pyhton安装pytesseract2.使用brew 安装tesseract3.将pytesseract包的里的pytesseract.py 中的tesseract_cmd的路径换成brew 安装的tesseract包的安装目录。这样才能一次性成功。完整源码import pytesseractfrom PIL import Imageimport pymysqlfrom coverage
原文链接文本识别 使用 Tesseract 进行 OpenCV OCR 和 文本识别在2019年7月18日上张贴 由hotdog发表回复文本识别 用 Tesseract 进行 OpenCV OCR 和 文本识在本教程中,您将学习如何应用OpenCV OCR(光学字符识别)。我们将使用OpenCV,Python和Tesseract 执行(1)文本检测和(2)文本识别。几周前,...
基于OpenCV 5 DNN的轻量化OCR系统设计与实现 摘要 本研究设计并实现了一种仅依赖OpenCV 5 DNN模块的轻量化OCR系统,解决了传统OCR方案依赖框架臃肿、部署复杂的问题。系统支持PP-OCRv3至v6全系列模型,覆盖50余种语言识别,通过OpenCV DNN实现端到端推理。关键技术包括:优化DBNet检测模型适配、实现CRNN识别网络解码、解决OpenCV 5版本兼容性问题。实
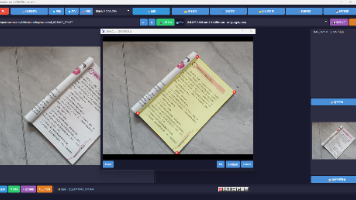
媒资系统是媒体机构用于存储、管理、检索和分发音视频、图片、文本等数字资产的核心平台。
本文介绍了如何在星图GPU平台上自动化部署🖋️ 深求·墨鉴 (DeepSeek-OCR-2)镜像,实现高效OCR文字识别。通过调整分辨率、语言模型等参数,用户可优化识别精度与速度的平衡,适用于古籍数字化、日常办公文档处理等场景,提升文档处理效率。
本文介绍了如何在星图GPU平台上自动化部署🖋️ 深求·墨鉴 (DeepSeek-OCR-2) 镜像,实现高效的OCR文字识别功能。该镜像能够智能识别图片和文档中的文字,并支持表格数据提取,广泛应用于文档数字化、纸质档案电子化等场景,显著提升文本处理效率。
本文介绍了如何在星图GPU平台上自动化部署🖋️ 深求·墨鉴 (DeepSeek-OCR-2)镜像,实现高效的文字识别与文档数字化。该平台简化了部署流程,用户可快速搭建OCR应用环境,轻松将图片中的文字、表格及公式转换为可编辑的Markdown格式,广泛应用于纸质文档电子化、会议纪要整理等场景。
本文介绍了如何在星图GPU平台自动化部署🖋️深求·墨鉴(DeepSeek-OCR-2)镜像,实现生产级OCR文字识别。该镜像支持一键解析文档图片并转换为可编辑文本,典型应用于学术论文数字化、商业报表解析等场景,无需训练模型或调整参数即可获得高精度识别结果。
本文介绍了如何在星图GPU平台自动化部署🖋️深求·墨鉴(DeepSeek-OCR-2)镜像,实现高效OCR文字识别。该镜像能够快速处理文档数字化需求,特别适用于扫描文件文字提取、表格识别等场景,大幅提升办公自动化效率。
本文介绍了如何在星图GPU平台上自动化部署🖋️ 深求·墨鉴 (DeepSeek-OCR-2)镜像,实现高效的文字识别服务。该平台支持一键启动API服务,可快速处理文档数字化、表格和公式识别等场景,显著提升办公自动化与内容处理效率。
本文介绍了如何在星图GPU平台自动化部署DeepSeek-OCR-2开源OCR镜像,实现高效文字识别。该方案支持复杂文档处理,可应用于PDF转文本、表格提取等场景,显著降低OCR使用成本并提升识别精度,适合中小团队快速搭建经济高效的OCR解决方案。
本文介绍了如何在星图GPU平台上一键自动化部署🖋️ 深求·墨鉴 (DeepSeek-OCR-2) 镜像,实现高效文档文字识别与数字化处理。该工具可精准提取图片中的文字并保持原始排版,适用于扫描文档数字化、书籍电子化等场景,大幅提升办公和学习效率。
本文介绍了如何在星图GPU平台自动化部署【ollama】Qwen2.5-VL-7B-Instruct镜像,实现高效识别高清图像中的微小文字(如小于8px的网页文本或商品标签)。该模型在文档数字化、自动化测试等场景中表现出色,准确率领先,可大幅提升图像文本提取的效率和可靠性。
本文介绍了如何在星图GPU平台上自动化部署🏮 DeepSeek-OCR · 万象识界镜像,赋能嵌入式端文字识别任务。该镜像可高效适配STM32等资源受限设备,典型应用于工业质检中的电路板丝印识别,在离线、低延迟、强干扰环境下实现高鲁棒性OCR,显著提升产线实时检测能力。
本文介绍了如何在星图GPU平台上自动化部署🖋️ 深求·墨鉴 (DeepSeek-OCR-2)镜像,赋能Unity引擎实现AR场景下的实时文字识别。通过端侧高效推理,该方案可快速提取并定位现实环境中招牌、铭牌、碑文等文字内容,广泛应用于AR导览、工业维修辅助与教育交互等典型场景。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,实现高效的文字识别与提取。该平台简化了部署流程,用户可快速搭建OCR环境,应用于文档数字化、图片文字提取等场景,轻松将PDF或图像转换为可编辑的文本内容。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,快速搭建文字识别服务。该平台简化了部署流程,用户可轻松实现图片和PDF文档的自动化文字提取,广泛应用于文档数字化、办公自动化等场景,显著提升信息处理效率。
本文介绍了如何在星图GPU平台上自动化部署🏮 DeepSeek-OCR · 万象识界镜像,实现浏览器端实时文字识别。该方案支持发票识别、白板转笔记、黑板公式提取等典型场景,全程本地处理,保障隐私与低延迟。
本文介绍了如何在星图GPU平台上一键自动化部署DeepSeek-OCR-2镜像,快速搭建智能OCR识别环境。该工具能将扫描版PDF、图片中的文字高效转换为可编辑文本,典型应用于合同、发票等纸质文档的数字化处理,显著提升办公自动化效率。
本文介绍了如何在星图GPU平台上一键自动化部署DeepSeek-OCR-2镜像,实现高效的文字识别应用。该镜像支持从PDF和图片中快速提取文字内容,可广泛应用于文档数字化、发票信息识别等场景,大幅提升办公自动化效率。
本文介绍了如何在星图GPU平台自动化部署DeepSeek-OCR-2镜像,实现高效合同扫描件文字提取。该平台简化了部署流程,用户可快速搭建OCR处理环境,应用于企业合同数字化管理、关键信息提取和文档检索等场景,显著提升文档处理效率与准确性。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,实现图片文字的智能识别与提取。该平台简化了部署流程,用户可快速搭建个人OCR系统,应用于办公文档电子化、会议纪要整理等场景,大幅提升文字处理效率。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,实现高效的文字识别应用。该平台简化了部署流程,用户可通过其Gradio界面轻松上传PDF或图片文件,快速将文档内容转换为可编辑的文本,特别适用于合同处理、报表数据提取等办公自动化场景。
本文介绍了如何在星图GPU平台上一键自动化部署DeepSeek-OCR-2镜像,实现智能文字识别功能。该工具能自动解析图片或PDF中的文字内容,并转换为结构化文本,广泛应用于合同条款提取、学术文献数字化等场景,大幅提升文档处理效率。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,实现高效智能文字识别。该镜像支持图片和PDF文档的自动化处理,可广泛应用于文档数字化、表格数据提取等场景,显著提升文字识别效率和准确率。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,实现高效OCR文字识别。通过调整置信度阈值与优化后处理清洗逻辑,可显著提升文档识别的准确性,适用于合同、报告等文档的自动化文字提取与处理。
本文介绍了如何在星图GPU平台上自动化部署🏮 DeepSeek-OCR · 万象识界镜像,快速构建高精度文字识别应用。用户无需复杂环境配置,即可实现超市小票、发票等日常文档的端到端OCR识别,自动提取结构化文本并保留排版信息,显著提升办公与学习场景下的信息处理效率。
本文介绍了如何在星图GPU平台自动化部署🏮 DeepSeek-OCR · 万象识界镜像,实现高效精准的文字识别。该镜像适用于复杂文档处理、表格结构还原及多语言混合识别等场景,显著提升数字化文档处理的准确性和效率。
本文介绍了如何在星图GPU平台自动化部署DeepSeek-OCR-2镜像,实现高精度文字识别。该OCR模型能智能解析文档结构和布局,适用于学术文献数字化、企业文档处理等场景,用户可通过简单上传PDF文件快速获得可编辑文本,大幅提升文档处理效率。
本文介绍了如何在星图GPU平台自动化部署DeepSeek-OCR-2镜像,实现无需代码的智能文字识别。该工具能高效处理扫描文档、PDF文件等,准确提取可编辑文本,特别适用于办公文档数字化、学术资料整理等场景,大幅提升工作效率。
本文介绍了如何在星图GPU平台自动化部署DeepSeek-OCR-2镜像,实现高精度文字识别。该镜像支持复杂文档、表格和多语言混合内容的准确提取,适用于企业文档数字化、学术资料整理等场景,大幅提升OCR处理效率和自动化水平。
本文介绍了如何在星图GPU平台上一键自动化部署DeepSeek-OCR-2镜像,实现高效智能的文字识别功能。该工具可快速准确提取图片、PDF中的文字内容,适用于文档数字化、资料整理和内容创作等场景,大幅提升办公和学习效率。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,快速搭建个人文字识别服务。该服务能高效识别图片或PDF中的文字,并理解文档结构,典型应用场景包括将会议白板照片、扫描合同等纸质资料快速转换为可编辑的电子文档,极大提升信息处理效率。
本文介绍了如何在星图GPU平台上一键自动化部署DeepSeek-OCR-2镜像,实现高效OCR文字识别。该工具可智能解析合同、发票等文档,大幅提升数字化处理效率,典型应用于财务报销单自动录入,准确率超95%,节省90%工作时间。
本文介绍了如何在星图GPU平台上一键自动化部署DeepSeek-OCR-2镜像,实现高效OCR文字识别。该镜像通过升级的DeepEncoder V2编码器和vLLM推理加速,显著提升复杂文档(如表格、图文混排材料)的处理精度与速度,适用于企业文档数字化、学术资料整理等场景。
本文介绍了如何在星图GPU平台自动化部署DeepSeek-OCR-2镜像,实现高效OCR文字识别。该镜像通过创新的DeepEncoder V2架构和智能区域聚焦技术,在处理文档扫描、图像转文字等场景中,识别速度比传统OCR提升50%,同时保持高精度和低资源占用。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,实现高效OCR文字识别。该平台简化了部署流程,用户可快速搭建专业OCR环境,应用于文档数字化、图片文字提取等场景,显著提升处理效率与自动化水平。
本文介绍了如何在星图GPU平台上一键自动化部署DeepSeek-OCR-2镜像,实现PDF文档的高精度文字识别与提取。该镜像支持多语言和复杂版面的处理,可广泛应用于电子书制作、企业档案数字化等场景,显著提升文档处理效率。
本文介绍了如何在星图GPU平台上自动化部署DeepSeek-OCR-2镜像,实现高效图片文字识别。该平台简化了部署流程,用户可快速搭建OCR服务,应用于纸质文档数字化、会议纪要整理等场景,大幅提升信息提取效率。
本文介绍了如何在星图GPU平台自动化部署DeepSeek-OCR-2镜像,实现高效图像文字识别。该工具支持中英文等多语言混合识别,可快速从图片、PDF中提取文字内容,适用于文档数字化、手写笔记转换等场景,大幅提升信息处理效率。
文字识别
——文字识别
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 AMD开发者中国社区
AMD开发者中国社区

 AI Agent技术社区
AI Agent技术社区


































