




- @zouxin_88
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1、新建场景,创建一个球,在球上添加组件Trail Renderer。2、在Trail Renderer组件设置Time为0.5,Materials材质。3.Width下点击右键“Add key”添加控制点,起始宽度为1.0,结束宽度为0.0。在Scene场景中拖动球,就可以看到拖尾效果了。...
1.下载Sqlite库文件libsqlite3.so、sqlite3.dll,网上找的话到处都是。3.在Andorid上运行时,需要将数据库文件复制到另一个位置。2.将已建好的数据库文件放到StreamingAssets下。
使用Unity3d完成了可用于可视化的数字地球,该地球没有三维地球,但可以根据需求进行主题变色,下面是一些效果。技术交流Q-Q:5 1 5 7 1 6 0 3 0 ...
3.打开场景Assets\OpenCVForUnity\Examples\MainModules\dnn\YoloObjectDetectionExample\YoloObjectDetectionWebCamTextureExample.unity。1.打开Assets\OpenCVForUnity\StreamingAssets\dnn\setup_dnn_module.pdf。6.也可以自己

本数字地球全部由作者自由开发完成,未使用任何第三方插件,拥有完全知识产权。2021年10月9日更新已支持离线版高程数据和离线卫星影像数据。2021年1月22日更新全球任意位置模型可正常加载,无变形抖动。2021年12月15日更新日出、日落、大气散射、蓝天效果。说明这个不是GIS软件,是一个带地形的三维地球。2021年11月24日更新支持。2021年11月15日更新支持。,运行流畅无卡顿,占用内存小

Unity3d+Vuforia在iOS平台下扫描物体时出现黑色一闪一闪的解决办法:将ARCamer中的Clipping Planes中Near改为0.3即可。
树莓派端python示例及代码import ioimport picameraimport loggingimport socketserverfrom threading import Conditionfrom http import serverPAGE="""\<html><head><title>Picamera MJPEG Streaming<
【代码】在Unity3d中使用Netly开启TCP服务。
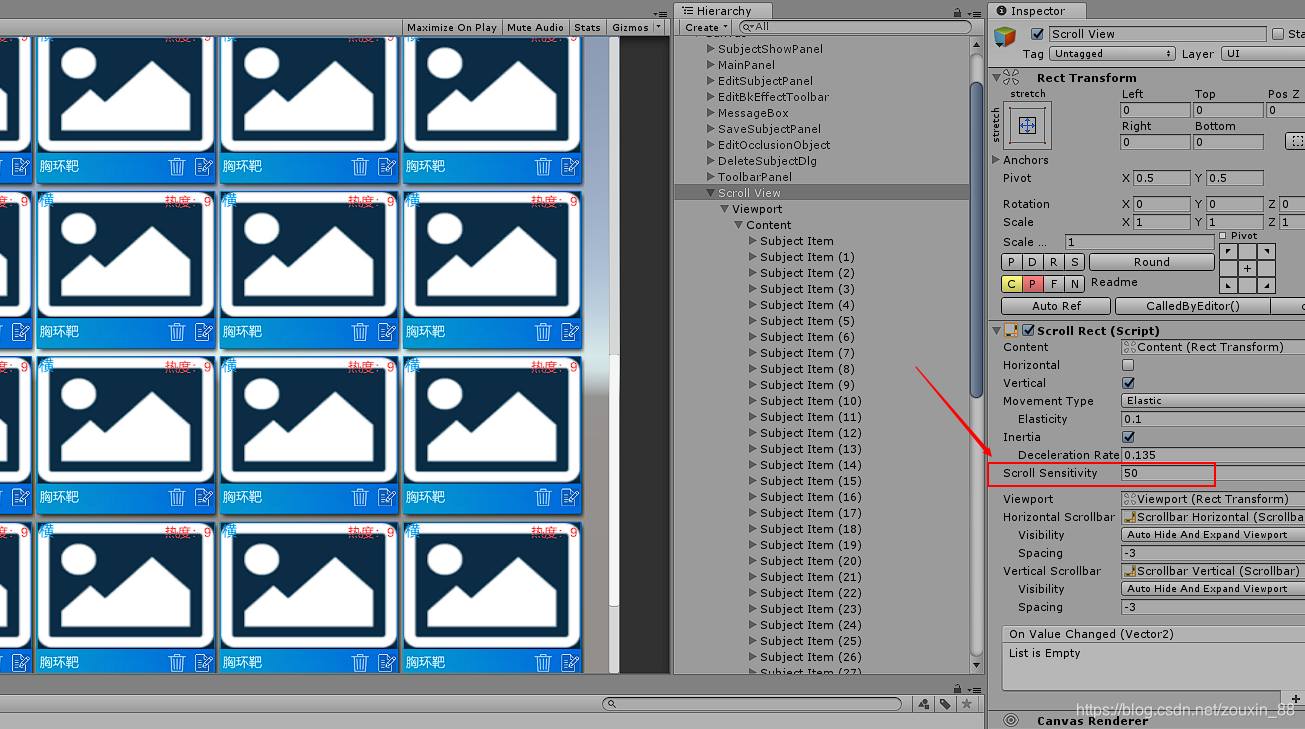
将ScrollRect的Scroll Sensitivity改大一些
最近接到一个需求,要求unity3d中读取ShapeFile格式文件。原以为找个插件几下就能搞定,结果找了一大圈一无所获。参考了一些代码,但是都不是针对Unity3d平台的,看来只好自己搞了。研究了一下ShapeFiles格式,搞出来了。(下图中还未完成文字的加入相关开发)GIS软件原图...