




- @YY007H
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【摘要】服务器上使用pip时出现OpenSSL模块报错,显示"X509_V_FLAG_CB_ISSUER_CHECK"属性缺失。初步判断系pip损坏所致,但常规重装方法因报错无法执行。最终通过系统级更新解决:执行sudo apt-get update和sudo apt-get upgrade openssl命令升级OpenSSL后问题得以解决。该方案绕过了直接修复pip的尝试,
一个针对深度学习应用优化的 GPU 加速库。它提供了高性能、高可靠性的加速算法,旨在加速深度神经网络模型的训练和推理过程。cuDNN 提供了一系列优化的基本算法和函数,包括卷积、池化、规范化、激活函数等,以及针对深度学习任务的高级功能,如循环神经网络(RNN)的支持。这些算法和函数充分利用了 NVIDIA GPU 的并行计算能力,提供了显著的性能加速。

本文介绍了如何在AutoGo项目中集成TomatoOCR纯本地离线文字识别插件。该插件支持中英文、繁体字、日语和韩语识别,准确率达99%,支持多种返回格式且无需联网。文章详细说明了插件集成步骤:1)准备Go开发环境;2)下载插件并放置到指定位置;3)配置main.go文件并设置license授权码。同时提供了完整的代码示例和参数配置说明,包括识别语言设置、检测模型调整、返回类型选择等功能。插件支持
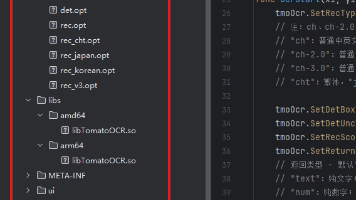
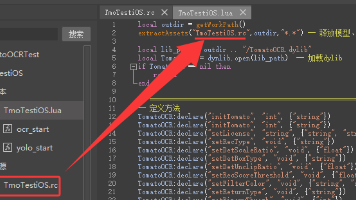
本文介绍懒人精灵iOS版集成TomatoOCR纯本地离线文字识别插件的方法。该插件支持多语言识别,准确率99%,支持多种返回格式且无需联网。集成步骤包括:1)下载懒人精灵开发工具和OCR插件;2)新建项目并添加插件资源;3)通过Lua代码加载插件并调用识别功能。插件提供丰富的参数配置选项,可调整识别类型、检测参数和返回格式等。识别结果可通过坐标点击或文本形式获取,适用于自动化脚本开发,相比服务器部
pytorch的cpu的包可以在国内镜像上下载,但是gpu版的包只能通过国外镜像下载,网上查了很多教程,基本都是手动从先将gpu版whl包下载下来,然后再手动安装,如何最快的通过pip的命令安装呢?下面我细细讲下。

一个针对深度学习应用优化的 GPU 加速库。它提供了高性能、高可靠性的加速算法,旨在加速深度神经网络模型的训练和推理过程。cuDNN 提供了一系列优化的基本算法和函数,包括卷积、池化、规范化、激活函数等,以及针对深度学习任务的高级功能,如循环神经网络(RNN)的支持。这些算法和函数充分利用了 NVIDIA GPU 的并行计算能力,提供了显著的性能加速。
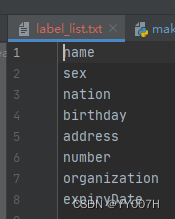
全网的身份证识别大部分都是通过识别整张图片,然后再对数据进行格式化解析,这会照成很大的局限性,比如非摆正图片,图片上有其他干扰信息,这就会导致通过此方式来识别大大降低了准确率和不确定性。这篇文章将会通过专业性角度来讲解如何更好的进行相关卡证的识别。......
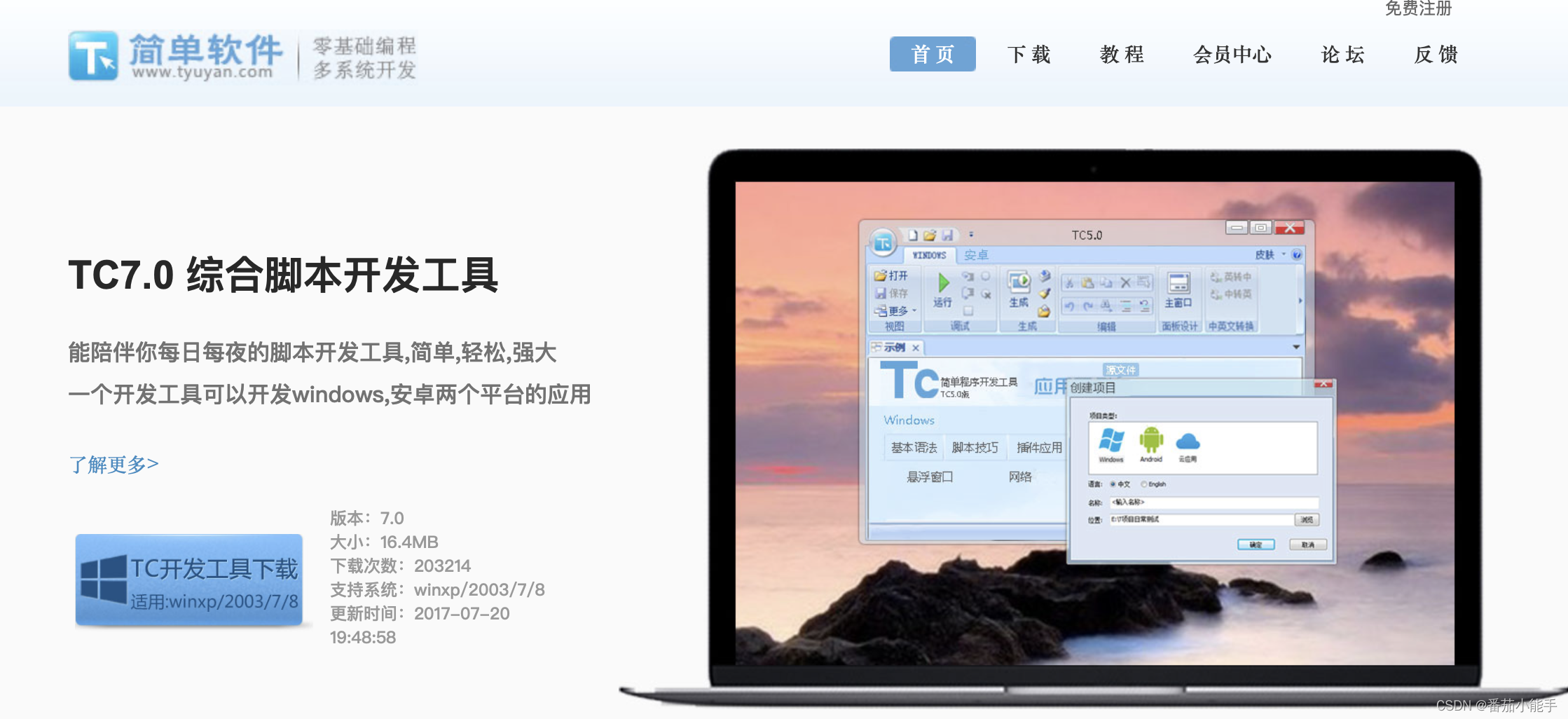
tc综合脚本开发工具是一种用于Windows平台的自动化测试工具,以及一个功能丰富的集成开发环境(IDE),它使用VBScript编写脚本语言,学习成本高。所以针对于该平台的文字识别插件几乎没有,本篇文章主要讲解下TC综合脚本开发工具PC端纯本地TomatoOCR离线文字识别插件如何使用和集成。
本文介绍了如何在AutoGo项目中集成TomatoOCR纯本地离线文字识别插件。该插件支持中英文、繁体字、日语和韩语识别,准确率达99%,支持多种返回格式且无需联网。文章详细说明了插件集成步骤:1)准备Go开发环境;2)下载插件并放置到指定位置;3)配置main.go文件并设置license授权码。同时提供了完整的代码示例和参数配置说明,包括识别语言设置、检测模型调整、返回类型选择等功能。插件支持
pytorch的cpu的包可以在国内镜像上下载,但是gpu版的包只能通过国外镜像下载,网上查了很多教程,基本都是手动从先将gpu版whl包下载下来,然后再手动安装,如何最快的通过pip的命令安装呢?下面我细细讲下。