




- @qq_18055167
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
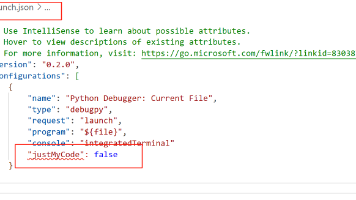
在调试代码时,若需要跟踪第三方库或框架的调用,只需在VS Code的launch.json配置文件中添加"justMyCode":false设置。该配置会禁用"仅调试我的代码"模式,使调试器能够进入非用户编写的代码(如系统库和依赖项),便于深入排查问题。配置方法简单直观,如图所示。这一技巧特别适用于需要分析底层调用或排查依赖问题的开发场景。
Step 3:删除/用户/XXX//.vscode/AppData/Roaming/Code。Step 2: 删除/用户/XXX/.vscode文件夹。Step 1: 从控制面板删除vscode。这是说明VScode版本太高了。从中可以下载2023年出的版本。

文章目录DM检验的原理代码实现函数说明实例本文参考DM检验的原理给定两个预测的预测结果,我们希望比较他们的预测结果,以用于模型预测精度的比较。Diebold-Mariano检验本质是一个t检验,用于检验产生预测的两个损失序列的平均值是否相等。即,它是一系列损失差的零均值的t检验。原假设:DM统计量均值为0,即两个模型的预测效率一致。备择假设:两个模型的预测效率不一致。**注意:**在使用DM检验式
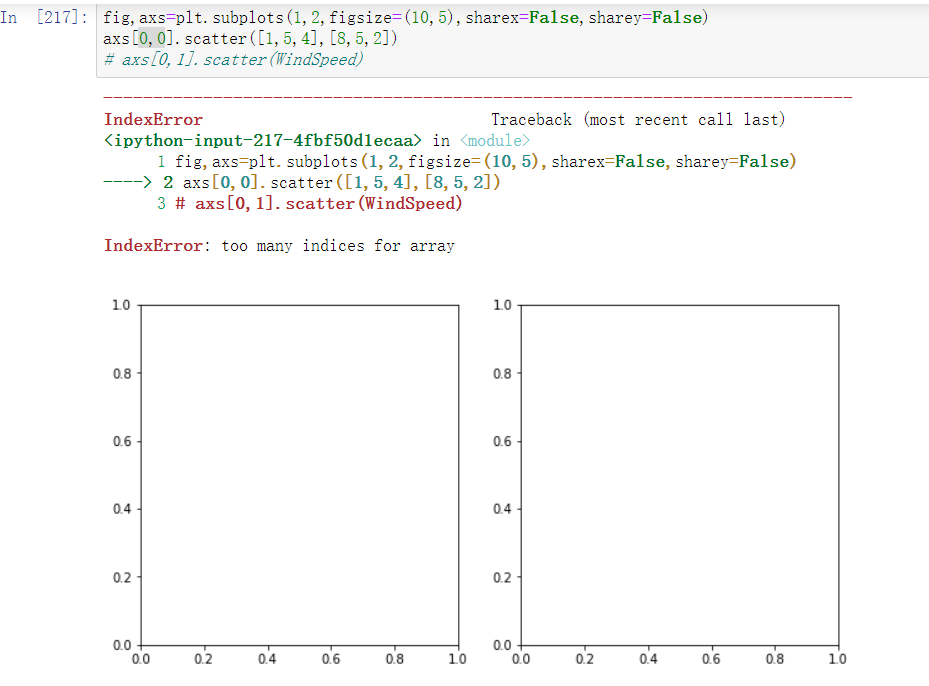
subplots作图中subplots(1,n)分配的坐标轴索引是一维的不能用二维方法引用,错例如下:正确的做法:
Step 3:删除/用户/XXX//.vscode/AppData/Roaming/Code。Step 2: 删除/用户/XXX/.vscode文件夹。Step 1: 从控制面板删除vscode。这是说明VScode版本太高了。从中可以下载2023年出的版本。
获取当前线程import threading#返回当前线程t=threading.current_thread()print(t)#获得这个线程的名字t.getName()#判断线程是否存活t.is_alive()创建线程import threading#创建一个线程my_thread=threading.Thread()#创建一个名称为my_tread的线程my_t...
accelerate最核心的价值是简化大模型训练 / 推理的硬件适配,它抽象了不同硬件(单卡、多卡、CPU、TPU、GPU 混合精度)的底层差异,让你用一套代码就能在任意硬件环境下运行,不用针对不同设备写不同的逻辑。硬件适配自动化:不管你是用单张 GPU、多张 GPU(单机多卡 / 多机多卡)、CPU,还是 TPU,甚至是低显存的显卡,accelerate 都能自动适配,比如自动做模型分片、内存优
Ipopt(Interior Point OPTimizer)是一个用于求解非线性优化问题的开源软件包。它特别适用于大规模的非线性规划(NLP)问题。

在 LaTeX 里,tabularx 是一个很实用的包,它能够创建宽度固定的表格,而且可以自动对列宽进行调整。\newcolumntype{L}{>{\raggedright\arraybackslash}X} % 左对齐\newcolumntype{C}{>{\centering\arraybackslash}X} % 居中对齐\newcolumntype{R}{>{\raggedleft\ar
vba代码如下:Sub 合并当前工作簿下的所有工作表()Application.ScreenUpdating = FalseFor j = 1 To Sheets.CountIf Sheets(j).Name <> ActiveSheet.Name ThenX = Range("A65536").End(xlUp).R