登录社区云,与社区用户共同成长
邀请您加入社区
随着5G技术的普及和移动设备性能的提升,Python在手机网页开发中的应用将更加广泛。人工智能和机器学习的集成将成为趋势,Python在这些领域的优势将帮助开发者创建更智能的网页应用。然而,也需注意移动环境的多样性带来的兼容性挑战,以及安全性和性能优化的持续需求。通过不断学习和技术更新,开发者可以充分利用Python的强大功能,推动移动网页技术的进步。Django是一个高级框架,提供了全功能的解决
Java 8引入的Stream API是处理集合数据的现代化工具,它允许以声明式方式处理数据序列,提供了一种高效、可读性强的数据处理方法。Stream不是数据结构,而是对数据源(如集合、数组)的元素进行聚合操作的包装器,支持函数式编程风格,能够实现复杂的查询、过滤、映射和归约操作。通过流水线式的操作链,Stream可以显著简化代码并提升处理效率,尤其适合大数据量的批处理场景。
来自全球的开发者持续贡献针对特定领域的数百个专用库,从复杂的统计分析Bonferonni校正实现代码到机器学习模型的可视化工具,社区协作模式确保了技术解决方案的快速迭代。Anaconda Conda-Forge组织提出的元包管理方案(Meta-Package System)是可能的出路:通过定义core、contrib、experimental三个层级的标准化接口,允许库开发者在不破坏向后兼容性的
摘要: A 股市场素有“牛短熊长、震荡为主”的特征。传统的趋势突破策略在漫长的震荡市中往往面临反复止损的磨损。本文将利用 Python (Backtrader + Tushare) 构建一个基于 布林带 (Bollinger Bands) 的均值回归策略。该策略利用统计学原理,在股价偏离正常波动范围时进场,旨在捕捉高胜率的修复行情。
2026年人工智能赋能社会发展国际学术会议(AI4Society 2026)将于2026年8月14–16日在中国重庆举行。会议特别强调人工智能在实际应用中的落地,包括医学成像、遥感、工业检测、基础设施监测以及基于视觉的智能系统等方向。通过融合算法研究、系统设计与工程实现,AI4Society 2026 将为跨学科交流与合作提供高水平的国际平台。
本文通过AI宏观因子分析模型,结合核心通胀数据、货币政策预期、债券市场定价、国际油价变化及AI生产率因素,分析市场对于年内货币政策路径的最新判断,以及人工智能技术对通胀与利率预期的潜在影响。
2026 年 8 月各类国际学术会议火热征稿进行中,暑期正是产出学术成果的绝佳时机!本次汇总覆盖理工、计算机、生物医药全学科优质 EI/Scopus 会议,名校背书、出版正规、检索稳定,审稿高效、上岸率可观,适配毕业加分、职称申报、课题成果产出,科研朋友尽快规划投稿。
本文介绍了一个基于Java和小程序的校园资讯平台设计与实现方案。系统采用SSM框架和MySQL数据库,包含管理员和用户两个角色。管理员功能包括学生管理、兼职信息管理、二手物品管理等;用户可通过小程序访问平台资讯。系统实现了二手物品展示、评论互动等核心功能,具有界面清晰、操作简便的特点。文章详细阐述了系统设计、功能模块、数据库结构及核心代码实现,为校园资讯平台开发提供了实用参考。
本文基于AI宏观预测模型、机器学习、事件驱动模型、特征工程及多因子决策引擎等人工智能分析框架,结合美国6月非农就业(NFP)、美元指数、美联储政策预期及全球黄金需求等核心变量,解析黄金单日上涨逾2%的底层驱动逻辑,并探讨AI模型如何重构黄金市场未来走势。
内容摘要:2026年4月至5月,汇德隆家电萧山11家门店围绕"新汇德隆之夜"第五届活动及39周年庆典,联动PC屏保画报广告展开集中营销投放。当京东用算法在手机里"猜你喜欢",汇德隆用PC屏保画报广告在白领电脑屏幕上"主动拦截"。汇德隆39年,萧山11店,用约2.44万元费用、121.8万次展现、4.91%稳定点击率证明:本地家电卖场的反电商之道,不是打价格战,而是打认知战。电商的优势在于"主动推送
面试官问:"Llama 的归一化层,连均值都不算,你知道吗?"> "3 年大模型开发经验,精通 Transformer 架构,熟悉 Llama、Qwen、DeepSeek 等主流开源模型的训练与微调。"
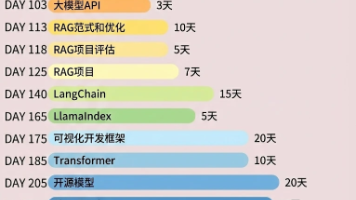
本文是【2025吴恩达机器学习课程笔记】全16篇系列文章的官方汇总目录帖。内容严格遵循吴恩达老师的教学大纲,覆盖了从监督学习(线性回归、逻辑回归、神经网络)、无监督学习(K-均值、PCA、异常检测)到强化学习(Q-Learning、DQN)的完整知识体系。本帖提供全系列博文的超链接导航,旨在为学习者构建一份清晰的学习路线图和一站式快速查阅指南。无论你是初学者系统入门,还是从业者巩固知识,这都是一份
第1关:什么是质心#encoding=utf8import numpy as np#计算样本间距离def distance(x, y, p=2):'''input:x(ndarray):第一个样本的坐标y(ndarray):第二个样本的坐标p(int):等于1时为曼哈顿距离,等于2时为欧氏距离output:distance(float):x到y的距离'''#********* Begin **
本资源汇集了国科大马丙鹏老师计算机算法作业中的内容,旨在帮助学生深入了解分枝限界法在 0/1 背包问题中的应用,提升算法理解和问题解决能力。
本文介绍了图像滤波的基本概念和五大经典滤波算法,包括均值滤波、高斯滤波、中值滤波、双边滤波和导向滤波。图像滤波通过滑动窗口对邻域像素进行统计或加权计算,用于去噪、平滑和边缘保留等预处理任务。文章详细阐述了均值滤波的数学原理和实现步骤,包括离散域计算、卷积核表达、边界处理以及具体例题的手动计算与代码验证。通过Python代码实现展示了均值滤波的实际应用,帮助读者深入理解算法底层逻辑。这些经典滤波方法
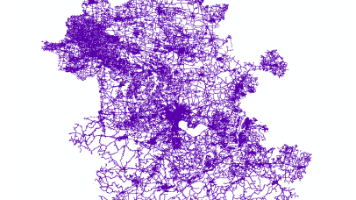
该数据集收录了2024-2025年全国34个省份道路数据,其中包含道路名称、道路类型、道路编号、是否为单行道、是否为桥梁以及是否为隧道等变量。道路矢量数据对于提升城市交通效率、优化交通规则、增强导航服务的准确性等方面具有不可替代的作用,是现代城市管理和发展的重要基础。该数据集主要以shp的格式存储。以安徽省为例来预览该数据。
本文标志着我们从监督学习迈向无监督学习。文章首先详细介绍了无监督学习的核心任务——聚类,并深入剖析了最经典的K-均值(K-means)算法,包括其迭代步骤、优化目标(失真函数)以及在实践中如何选择聚类数量K。随后,文章转向了无监督学习的另一大应用——异常检测,阐述了其基于密度估计的核心思想,并详细介绍了一种基于高斯分布的异常检测算法的实现与评估方法。
本文介绍了Welford在线算法,这是一种高效计算大数据集统计量的方法。针对内存不足时处理大规模数据的问题,文章对比了传统方差计算方法的缺陷(内存占用大、数值稳定性差),详细阐述了Welford算法的核心思想:通过维护均值、计数和平方差三个变量,实现增量式流式计算。该算法具有O(1)空间复杂度和O(N)时间复杂度,能有效避免数值计算中的精度损失问题。文中提供了Python实现代码和实际应用示例,展
CREATE DATABASE 语句用于创建数据库。
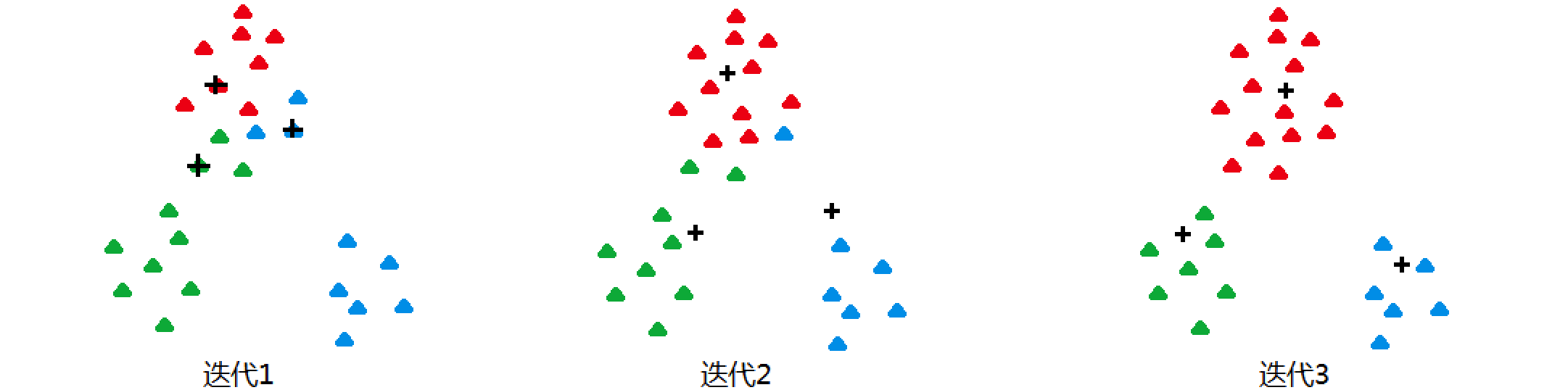
K均值聚类算法在图像处理领域,尤其是图像分割中,是一种广泛应用且效果显著的无监督学习方法。它通过迭代过程将图像中的像素点划分为K个不同的簇,每个簇由一个中心点代表,从而实现对图像的初步分割。初始化中心点:首先随机选择K个像素点作为初始的簇中心。分配像素点:计算每个像素点与K个中心点的距离,将每个像素点分配给距离最近的中心点所在的簇。更新中心点:对于每个簇,计算所有像素点的平均值,将这个平均值作为新
站在强化学习的山巅回望,那些让我们抓狂的复杂环境,不过是成长路上的垫脚石。记住:每个报错信息都是系统在和你对话,每次训练崩溃都是认知升级的契机。当你下次看到回报曲线突然跳水时,不妨笑着对它说:“又抓到你了,小调皮!” 保持这种黑客般的探索精神,终有一天,你会从环境的征服者进化为规则的制定者。编程之路,道阻且长。但只要你手里握着Stable Baselines3这把瑞士军刀,胸中装着这五把金钥匙,再
上期内容分析、证明了竞彩官方终赔时,当主队让1球同时又满足:让负赔率>平负均值赔率的情况出现了6胜3平1负,说明了竞彩官方给出的让负过大条件下并不利于客队打出,此时近十场中主不败概率90%,其中主胜的概率为60%,
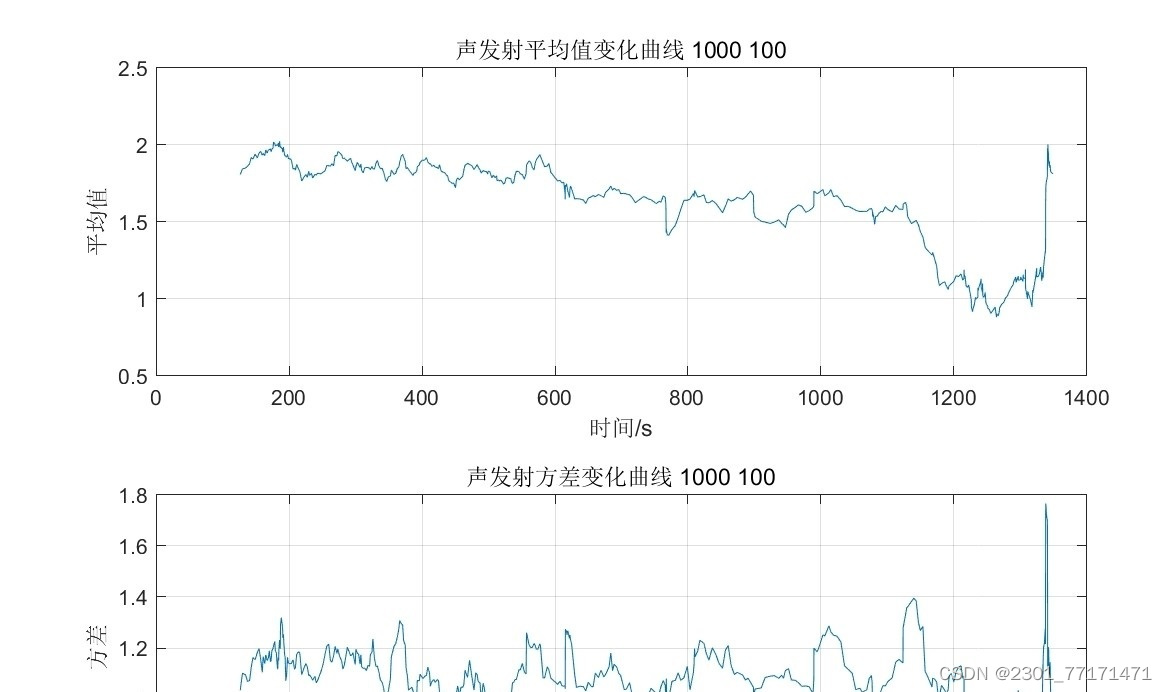
MATLAB计算声发射活动度s值(或变异系数,或均值与方差,三选一)m文件(参数可调)
MODIS(MCD12Q1)中国2001-2024年土地覆盖数据集是基于Terra和Aqua卫星观测数据,应用监督分类算法生成的年度、空间分辨率约为500米的科学数据集。
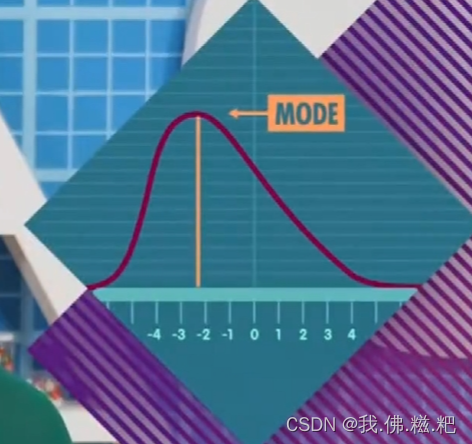
分别是众数,中位数,和平均值,这是一个偏态分布,一旦出现平均值比众数中位数大得多的情况就说明有一个极端数据在影响平均值,这类问题看众数可能更好的表现数据的普遍情况,根据数据的不同情况选择使用一种或几种集中数据类型来表示数据特点,这是我对这节课的理解。
均值漂移聚类算法是一种基于密度的非参数聚类方法,通过迭代将数据点向密度最高区域移动实现聚类。与K均值不同,它无需预设簇数,自动根据数据确定簇数。算法流程包括初始化簇、计算质心、迭代移动和收敛停止。Python实现可使用scikit-learn库,主要步骤包括数据生成、带宽估计、模型训练和结果可视化。该算法在计算机视觉、图像处理等领域有广泛应用,优势在于无需模型假设、能处理复杂形状簇,但高维数据表现
本文介绍了四种常用的均值计算方法:算术平均、几何平均、调和平均和平方平均。算术平均是最基础的计算方式,适用于描述数据集中趋势;几何平均适合处理增长率、比率等乘积关系数据;调和平均则适用于速率、比率等反比关系数据;平方平均(均方根)常用于处理波动较大的数据。每种方法各有特点和应用场景,选择合适的方法取决于数据类型和分析目的。文章详细阐述了各种均值的数学原理、计算方法和典型应用,并提供了Python实
引言: k均值(k-means)是一种聚类算法,其工作流程如下:随机选择k个点作为初始质心(质心即簇中所有点的中心),然后将数据集中的每个点分配到一个簇中,具体来讲,为每个点找距其最近的质心,并将其分配给该质心所对应的簇。这一步完成之后,每个簇的质心更新为该簇所有点的平均值。重复以上步骤,直到质心不发生变化。 k均值的操作解释参见图1。图1 然而随机地选取初始...
本摘要简要介绍MODIS(MCD19A2)中国区域2000-2024年度平均气溶胶光学厚度(AOD)数据集。
本文通过构建黄金市场基础设施分析模型,结合香港黄金中央清算系统上线进程、伦敦合格交割标准(London Good Delivery)、亚洲黄金流动性分布以及区域金融中心竞争格局,分析香港建立本土黄金清算网络对亚洲黄金定价权、实物交割效率及跨境资金流动可能产生的影响。
本文通过AI宏观因子模型,结合黄金价格走势、能源市场变化、美联储政策预期、美元指数以及美债收益率等关键变量,分析黄金震荡回升背后的驱动逻辑,并探讨影响未来市场方向选择的核心定价因子。
本文通过AI多因子定价模型、金银比偏离监测系统以及宏观流动性分析框架,结合贵金属价格表现、工业需求变化和美债收益率结构,分析当前白银相对黄金的弱势格局,以及金银比突破关键区间后市场可能面临的定价重估过程。
本文通过全球央行黄金储备数据、实际利率变化路径及黄金价格走势表现,结合AI宏观因子分析模型、多变量资产定价框架与央行行为数据特征,分析全球央行购金行为的结构性变化,以及实际利率因子对黄金价格影响权重回升的市场现象,探讨黄金定价逻辑从央行需求驱动向宏观利率驱动过渡的阶段性特征。
均值算法
——均值算法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区








 快递鸟社区
快递鸟社区



 DAMO开发者矩阵
DAMO开发者矩阵



















 2048 AI社区
2048 AI社区

 AtomGit开源社区
AtomGit开源社区



