




- @m0_37228052
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2024年暑假已经来临,下半年的非常多,许多同学可能是第一次参赛,对于如何准备感到迷茫和无从下手。在这种情况下,我们将分享一些备赛的小技巧,帮助大家在这个暑假更好的入门,即便是零基础的小白也能在数学建模中得心应手。

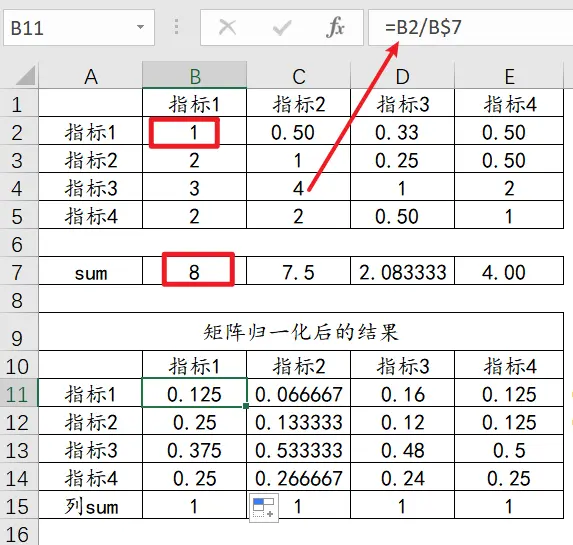
AHP层次分析法是一种解决多目标复杂问题的定性和定量相结合进行计算决策权重的研究方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的课题。1/8=0.125;0.5/7.5=0.066667等等;A指的是原始矩阵(构建矩阵),w指的
在做数据分析时,经常会有这样的困扰:面对几种相似的方法,既不清楚它们各自的使用场景,也无法分清它们之间的差别,一念之差就可能选错方法。如果你也有这样的困扰,建议按照,以便选出正确的方法进行分析。
目录第一部分 把控数据思维第二部分 问卷量表思维参考第三部分 问卷非量表思维参考第四部分 其它本文章为SPSSAU数据分析思维培养的第3期文章。上文讲解如何选择正确的分析方法,除了有正确的分析方法外,还需要把分析方法进行灵活运用。拿到一份数据,应该如何进行分析,总共有几个步骤,第一步第二步应该做什么,需要有个宏观把控,这样才能有规范的研究科学的思维和逻辑。...
是决策分析中的重要环节,常用的分析方法有很多种。比如权重计算时AHP层次分析法和熵值法最为常用;在综合评价中TOPSIS法、灰色关联法等方法比较常用。今天一文总结高频分析方法,大家可以了解方法的适用场景及软件操作教程。一、九种权重计算方法,下面分别介绍常用的分析方法。
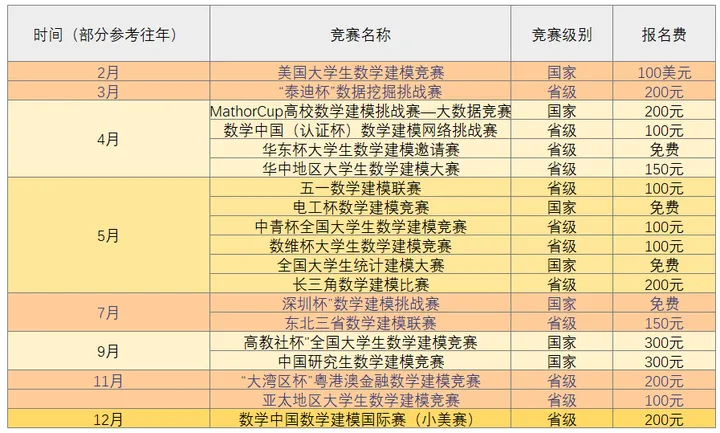
美赛已过,好多小伙伴表示已经错过,不清楚什么时候报名,什么时候准备,其实每年数学建模比赛有很多个,各大比赛的级别、报名时间、参赛对象等要求什么呢?小编从方面详细汇总了19个建模比赛,还在担心自己错过机会吗?码住这篇,一定要看到最后!
本文系统分析了美国大学生数学建模竞赛(MCM/ICM)的题目特点和选题策略。A、B、D题侧重数学建模与编程能力,C题关注数据分析,E、F题强调逻辑与写作。同时详细介绍了数学建模四大核心模型:评价模型(AHP、熵值法等)、预测模型(ARIMA、指数平滑等)、分类与聚类模型(逻辑回归、K-Means等)及统计分析模型(相关性分析、主成分分析等)。针对不同基础的团队提供了选题建议,并推荐了SPSSAU等

如果是进行泰尔指数计算,通常会涉及group项,比如区域(华北、华南、华东、西南、东北)其层次最高,也或者区域的下一层次省份group(北京、天津、河北、上海、浙江等),以及具体最小单位粒度城市,及其对应的GDP/人口信息数据等。比如下图中X有2种情况,Y有3个情况,一种有2*3=6种组合,数据信息只有6种组别的汇总项(即加权项),分别是40,10,20,30,20,50;除原始数据格式外,还有一

本文系统总结了毕业论文常用的12类数据分析方法,包括基本描述分析、差异性分析、相关影响分析、数据降维与聚类分析、权重计算、综合评价、数据预测、问卷研究、市场研究、医学数据分析、一致性检验和文本分析。每类方法都详细介绍了具体分析技术及其适用场景,如方差分析、回归模型、主成分分析、TOPSIS法等。文章还提供了SPSSAU软件操作指南,帮助研究者快速掌握各类统计分析方法的应用。这些方法覆盖了从基础统计

作为一名需要对课题进行研究的大学生,我在日常学习中经常需要用到spss,虽然老师上课已经初步教了我如何用这个软件,然而,在使用过程中我还是遇到了许多问题。具体来说,就是这个软件在很多地方都不够与时俱进,分析起来存在问题。例如,输入数据后,得到的分析结果表存在很多生涩的专有名词,且没有名词解释,导致初学者拿到一份数据的分析结果,并不知道其含义,这个软件的使用情况对外行人很不友好。我不禁在思考,既然这