




- @Transfattyacids
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
题目:《AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models》,AnomalyGPT:利用大型视觉-语言模型检测工业异常, AAAI 2024 Oral日期:2023.12.28单位:中国科学院自动化研究所,中国科学院大学,中科视语(北京)科技有限公司,武汉人工智能研究院论文地址:https://

题目:《Shrinking Class Space for Enhanced Certainty in Semi-Supervised Learning》,ICCV 2023缩小类空间以提高半监督学习的确定性日期:2023.8.13单位:香港大学、南京大学、上海AI Lab、悉尼大学、东南大学论文地址:https://arxiv.org/abs/2308.06777GitHub:https://

4:从平均值(mean)=0,方差(variance)=1的normal distribution中sample出ε,大小与image一致,是一张全是噪音的图片。我们会发现,噪声只由β序列和xt-1所决定(固定的而非可学习的过程),且生成xt-1时只依赖于xt,可以得出在添加噪声的过程中,是一个马尔科夫链过程,进而得出。αT),得到带有噪音的图片(α越大得到的图片带有的噪音占比越大);注意,在得到

文字输入decoder,用于限制图像生成的范围,Encoder输出一个向量,交给decoder,希望还原回一样的图像,encoder和decoder一起训练,希望生成的图像约相似越好同时要对encoder生成的向量做限制,强制其是normal distribution训练encoder,输入一张图片输出一个向量,并保证这个向量是可逆的(大小与输入图像一致),多个向量组成normal distrib
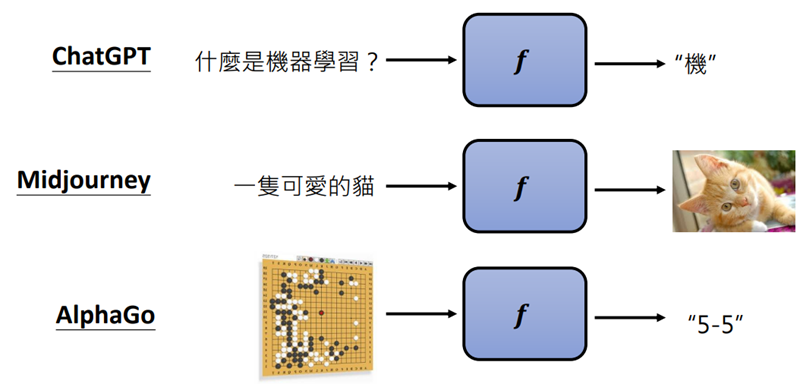
机器学习 ≈ 机器自动寻找一个函数f例如:chatGPT:输入:“什么是机器学习”通过函数f,输出:“机”Midjournery:输入:一只可爱的猫,通过函数f,输出:一张猫猫图片Regression(回归)与Classification(分类)Regression:函数的输出是一个数值例如:输入输入今天的PM2.5值、温度、臭氧量等,输出明天的PM2.5值Classification:函数的输出
题目:《MixTeacher: Mining Promising Labels with Mixed Scale Teacher for Semi-Supervised Object Detection》,CVPR 2023日期:2023.3.16单位:腾讯,上海交通大学,浙江大学,荣旗工业科技公司论文地址:http://arxiv.org/abs/2303.09061作者。

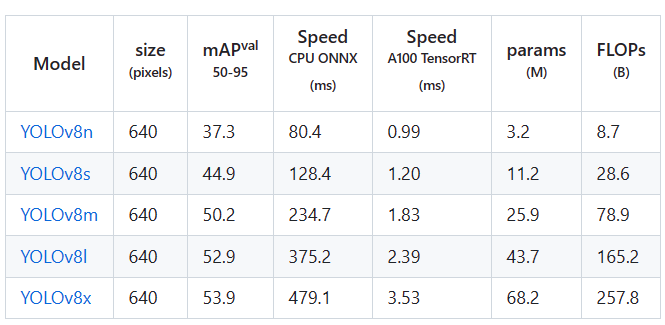
距离上一次发博客都过去一个多月了,期间不是没有在学习,也保持着记笔记的习惯,但由于刚入门ML/DL的领域,能力也一般,现阶段学的很多东西都很基础,很多时间都在看各路大佬们的课、博文或是读论文,笔记里很多内容都是在收集别人的知识产物,整理时也没有很有条理,根本不是能作为博客发布的状态,所以就一直存放在本地了…害,希望接下来能多有自己的产出吧orz。修改文件:/content/YOLOv8/ultra
机器学习 ≈ 机器自动寻找一个函数f例如:chatGPT:输入:“什么是机器学习”通过函数f,输出:“机”Midjournery:输入:一只可爱的猫,通过函数f,输出:一张猫猫图片Regression(回归)与Classification(分类)Regression:函数的输出是一个数值例如:输入输入今天的PM2.5值、温度、臭氧量等,输出明天的PM2.5值Classification:函数的输出

题目:《AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models》,AnomalyGPT:利用大型视觉-语言模型检测工业异常, AAAI 2024 Oral日期:2023.12.28单位:中国科学院自动化研究所,中国科学院大学,中科视语(北京)科技有限公司,武汉人工智能研究院论文地址:https://