




- @admin_15082037343
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Spring官方已经停止对Spring Security Oauth2的维护,项目和相关文档也被移除Spring Authorization Server是官方新推出的OAuth2.1和OpenID Connect1.0的实现两个主要的版本,0.4.x:jdk8。1.x: jdk17这里用的版本是0.4.1OAuth2.0已经不在推荐使用密码模式,OAuth2.1已经废除密码模式,这是为了安全考虑
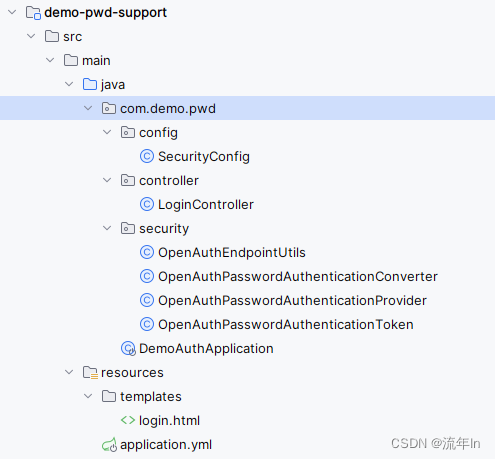
一:源码打包这里为什么是kettle 9.2,因为kettle 9.3+需要jdk11这里直接去下载kettle的源码,。这里需要自己搭建一个nexus仓库,因为有些包从kettle的仓库里面下载不下来。nexus新建仓库代理, 记得加到public里面去完整的settings.xmlidea导入kettle,等待下载maven依赖,慢慢等,需要很长的时间。这个包在kettle的远程仓库也没有,可
目录相关环境:项目场景:问题描述:原因分析:解决方案:相关环境:elasticsearch:7.7.1,三个节点的集群java: 1.8项目场景:商城搜索,两个操作。操作一:用户首次查询,将数据从es查询出来,再缓存到redis,之后的查询,直接读redis。操作二:后台管理数据,删除es部分数据,重新添加这部分数据,再删除缓存。问题描述:上面的流程看起来是没有问题,但是删除es部分数据的时候还是
指定主题名称指定分区数指定副本个数脚本执行完成后,log.dir目录下创建对应的主题分区。4个分区,两个副本总共八个副本,分配到三台机器(这里是用windows搭建的集群),8=3+3+2。如果是三个分区三个副本,9=3+3+3。主题、分区、副本、log关系如下这里我们还可以通过zk的客户端查看主题信息还可以通过describe来查看分区的分配细节手动指定副本的分配方案。根据分区号的数值从小到到大