- @m0_58371965
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
跨平台开发是目前开发较热门的方向,React Native 和 Flutter 均取得巨大的成功,但是也存在一些不足。小编也在关注这个问题,最近发现了一个跨平台框架-Lynx,对 React Native 进行了优化,获得了更接近于 Native 的体验。Lynx 选择了 Vue.js 作为开发框架,相对于 React Native,Lynx 拥有和 Native 一致的首屏体验和交互动画,与 F

前言在前端Vue.js 开发的时候,使用了基于 HTML 的模板语法,允许开发者声明式地将 DOM 绑定至底层 Vue 实例的数据。所有 Vue.js 的模板都是合法的 HTML,前端培训所以能被遵循规范的浏览器和 HTML 解析器解析。开发者比较熟悉的Vue.js 的数据绑定常用的方式就是使用“Mustache”语法 (双大括号) 的文本插值,Mustache 标签将会被替代为对应数据对象上 m

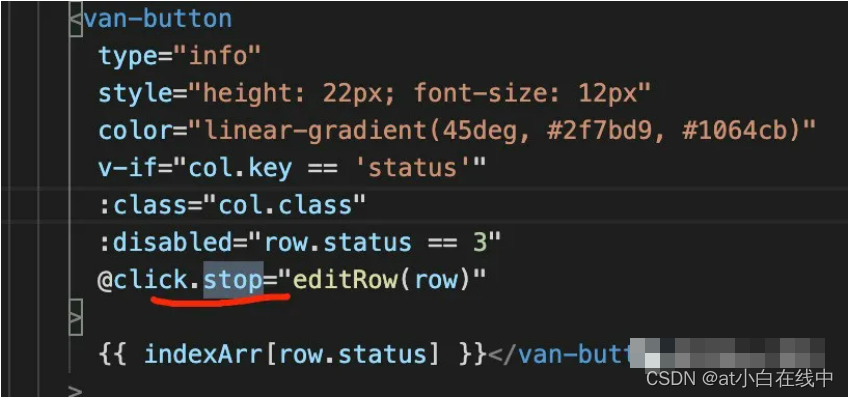
前言在前端开发Vue.js中,关于事件和按键的使用也是比较常见的操作之一,那么与它们相关的事件修饰符和按键修饰符也是延伸前端培训的比较常用的操作。那么本篇博文就来分享一下关于Vue.js中事件修饰符和按键修饰符的使用。一、事件修饰符在Vue.js的事件处理程序中使用v-指令中的v-on指令,是用来进行事件绑定的,也可用@来代替。Vue.js也为v-on指令提供了对应的一些事件修饰符,主要是通过由点
前言在前端开发的时候,对于数据处理是很重要的一块,尤其是要根据实际的业务需求来处理数据,有很强的兼容性要求。而且有些时候后端提供的数据和实际的业务需求数据是有偏差的前端培训,所以前端在拿到后台返回的数据之后,需要对数据进行“二次加工”处理,从而来满足业务需求。那么本篇文章就来分享一下在处理数据时候比较重要的一种方式:JavaScript中对数组进行合并之后的去重操作,这是一个比较常见的操作,分享出

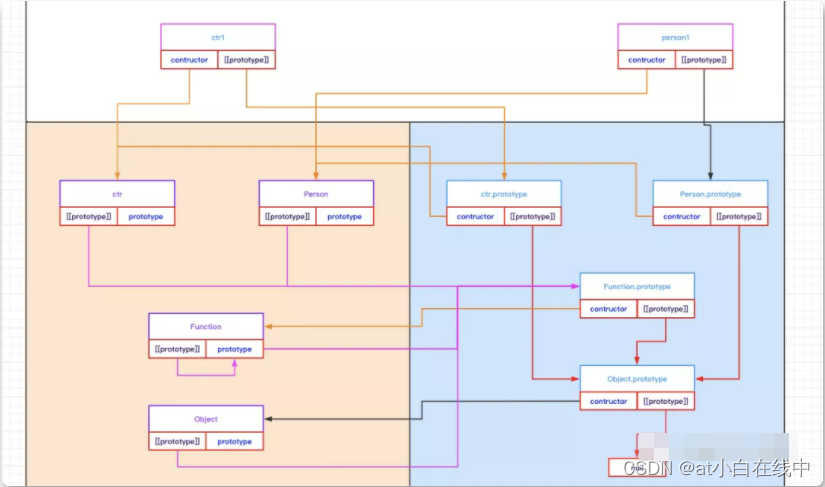
1. 普通对象和函数对象「javascript内部只有普通对象和函数对象」typeof {} // objecttypeof [] // objecttypeof function() {} // functiontypeof new Function('str', 'console.log(123)') // functiontypeof null // object2. 构造函数functio
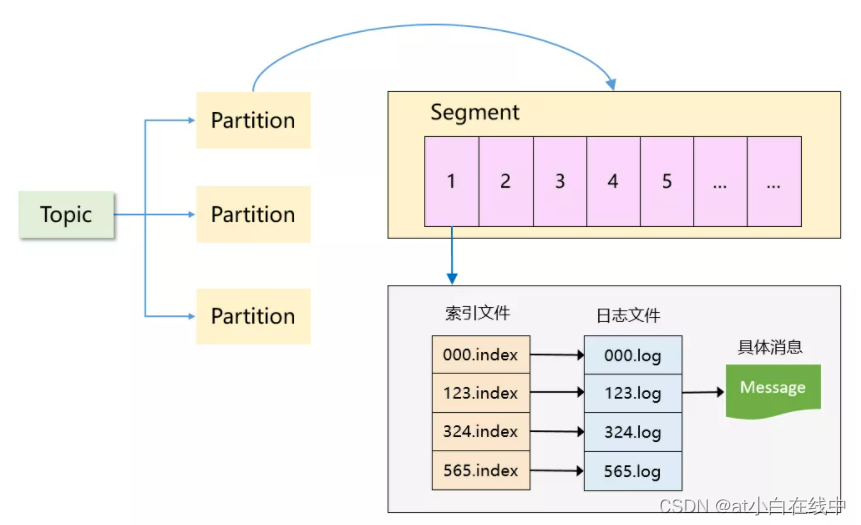
1. Kafka 的存储难点是什么?为什么说存储设计是 Kafka 的精华所在?之前这篇文章做过分析,Kafka 通过简化消息模型,将自己退化成了一个海量消息的存储系统。既然 Kafka 在其他功能特性上做了减法,大数据培训必然会在存储上下功夫,做到其他 MQ 无法企及的性能表现。图1:Kafka 的消息模型但是在讲解 Kafka 的存储方案之前,我们有必要去尝试分析下:为什么 Kafka 会采用
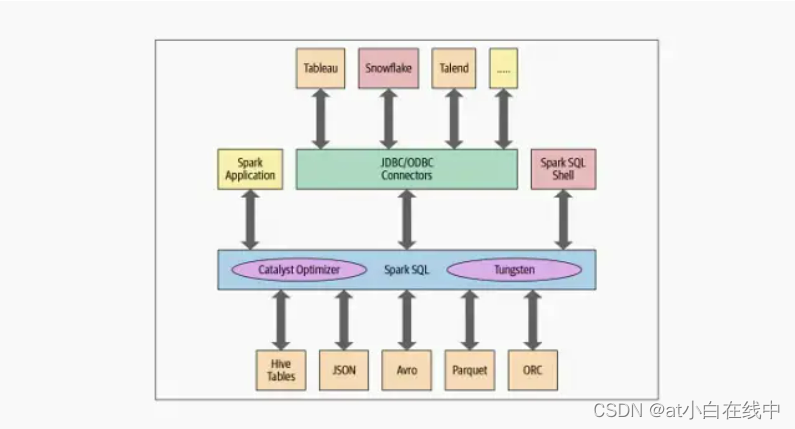
Spark SQL作为Spark计算查询的重要支撑,在Spark生态当中的重要性是不言而喻的。Spark SQL使得一般的开发人员或者非专业的开发人员,也大数据培训能快速完成相应的计算查询需求,这也是其存在的重要意义。今天的大数据开发学习分享,我们就来讲讲Spark SQL及基础引擎。在编程级别上,Spark SQL允许开发人员对具有模式的结构化数据发出与ANSI SQL:2003兼容的查询。自从
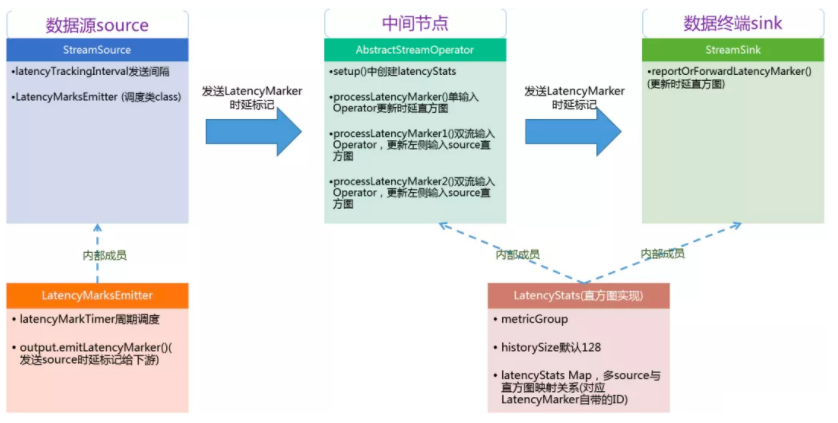
一、背景Flink Job端到端延迟是一个重要的指标,用来衡量Flink任务的整体性能和响应延迟(大部分流式应用,要求低延迟特性)。通过流处理引擎竞品对比,我们发现大部分流计算引擎产品,都在告警监控页面,集成了全链路时延指标展示(直方图)。一些低延时的处理场景,例如用于登陆、用户下单规则检测,实时预测场景,需要一个可度量的Metric指标,来实时观测、监控集群全链路时延情况。二、源码分析来源1、本
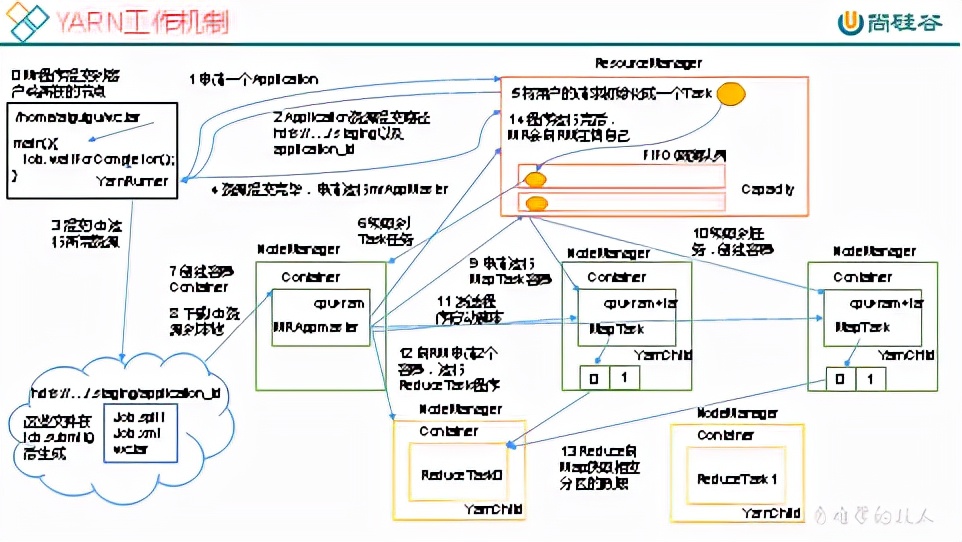
1.作业提交过程之YARN,如图所示。作业提交全过程详解(1)作业提交第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。第2步:Client向RM申请一个作业id。第3步:RM给Client返回该job资源的提交路径和作业id。第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。第5步:Client提交完资源后,向R
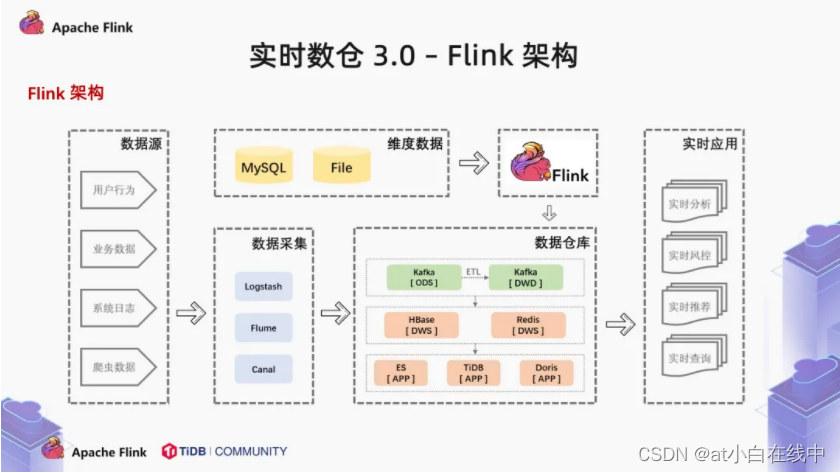
一、实时数仓经典架构实时数仓有三个著名的分水岭:第一个分水岭是从无到有,Storm 的出现打破了 MapReduce 的单一计算方式,让业务能够处理 T+0 的数据。第二个分水岭是从有到全,Lambda 与 Kappa 架构的出现,使离线数仓向实时数仓迈进了一步,而 Lambda 架构到 Kappa 架构的演进,实现了离线数仓模型和实时数仓模型的紧密结合。第三个分水岭是从繁到简,Flink 技术栈