登录社区云,与社区用户共同成长
邀请您加入社区
C++性能优化是一个从宏观架构到微观指令的多层次、系统性工程。它要求开发者深刻理解计算机系统的工作原理、编译器的行为以及C++语言本身的特性。记住,优化的最高境界是在不牺牲代码清晰度、可维护性和正确性的前提下提升性能。始终遵循“先测量,后优化”的原则,从算法和数据结构这个最大杠杆入手,再逐步应用更精细的技巧,最终编写出既优雅又高效的C++代码。---
例如,在频繁查找的场景下,`std::unordered_map`(平均O(1)复杂度)通常比`std::map`(O(log n)复杂度)快得多。同样,在需要频繁在序列中间插入或删除元素时,`std::list`可能比`std::vector`更高效,尽管后者在随机访问和尾部操作上拥有无与伦比的速度。了解不同的函数调用约定(如`__cdecl`, `__stdcall`, `__fastcall
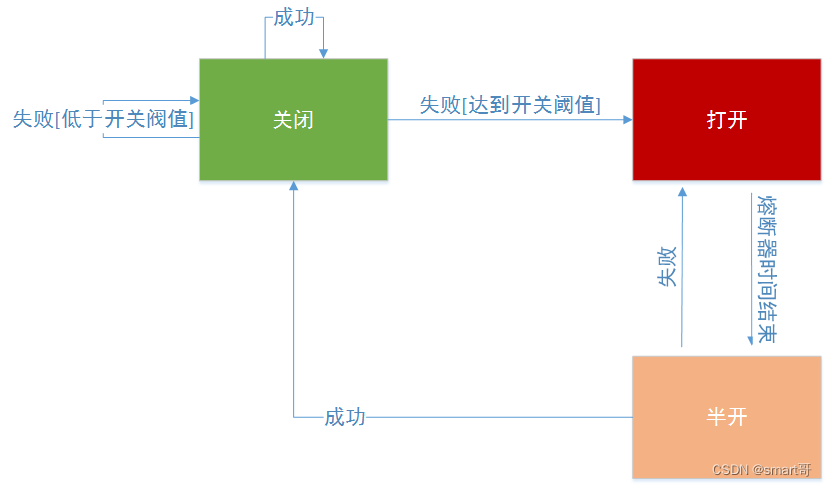
熔断机制基于状态机模型:当错误率超过阈值(如$50%$)时,熔断器进入“打开”状态,所有请求被拒绝;经过冷却期后,进入“半开”状态,允许部分请求尝试恢复;如果成功,则关闭熔断。这能提升系统韧性。数学上,熔断条件可表示为: $$ \text{错误率} = \frac{\text{失败请求数}}{\text{总请求数}} > \text{阈值} $$ 其中阈值通常可配置。
本文深入探讨C++模板元编程的本质与实践技巧,通过“元编程的艺术”视角解析编译时计算的原理与应用,并结合泛型设计案例,揭示其在代码灵活性与性能优化中的独特价值。- 典型元编程库对比(Boost.MPL、`std`实用工具类、Handmade Hero中的嵌套`sizeof`技巧)- 类型别名与典型元函数(如`std::conditional`、`std::enable_if`)- 元组表达法:将结
"玩过机器人跟随项目的兄弟应该都见过这种场景:几台设备嘀嘀嘀互相定位,主机实时追踪从机方位。这短短二十行代码干了三件大事:把原始相位差转成角度值,处理±180度边界问题,外加一个滑动平均滤波。注意那个32768的魔数——其实对应着16位有符号数的最大值,说明原厂直接用了ADC的原始数据。配套的Windows评估工具其实是个宝藏,它的3D视图用了DirectX的粒子特效,但核心算法和Linux版本同
本文旨在系统讲解Hystrix熔断器的状态监控机制,覆盖熔断器状态转换原理、健康指标采集算法、监控数据可视化等核心内容。适用于微服务架构下服务容错机制的深度优化场景。从熔断器理论基础出发,逐步深入到Hystrix实现细节,最终通过完整项目演示监控系统的搭建过程。熔断器(Circuit Breaker):自动检测服务故障并切断异常调用的容错模式:滑动时间窗口统计模型:健康指标快照服务网格(Servi
作为Spring Cloud体系内实现熔断机制的关键组件,Hystrix承担着服务容错保护的重要职责。它由Netflix开源,旨在为分布式系统提供延迟处理和容错解决方案。其核心作用在于引入延迟容忍与容错逻辑,精细管理分布式服务间的交互,确保系统的高可用性和鲁棒性。在复杂分布式系统环境中,往往涉及数十个应用,这些应用依赖于多个项目。不可避免地,每个依赖项目都有可能在某个时刻遭遇失败并触发故障。若未对
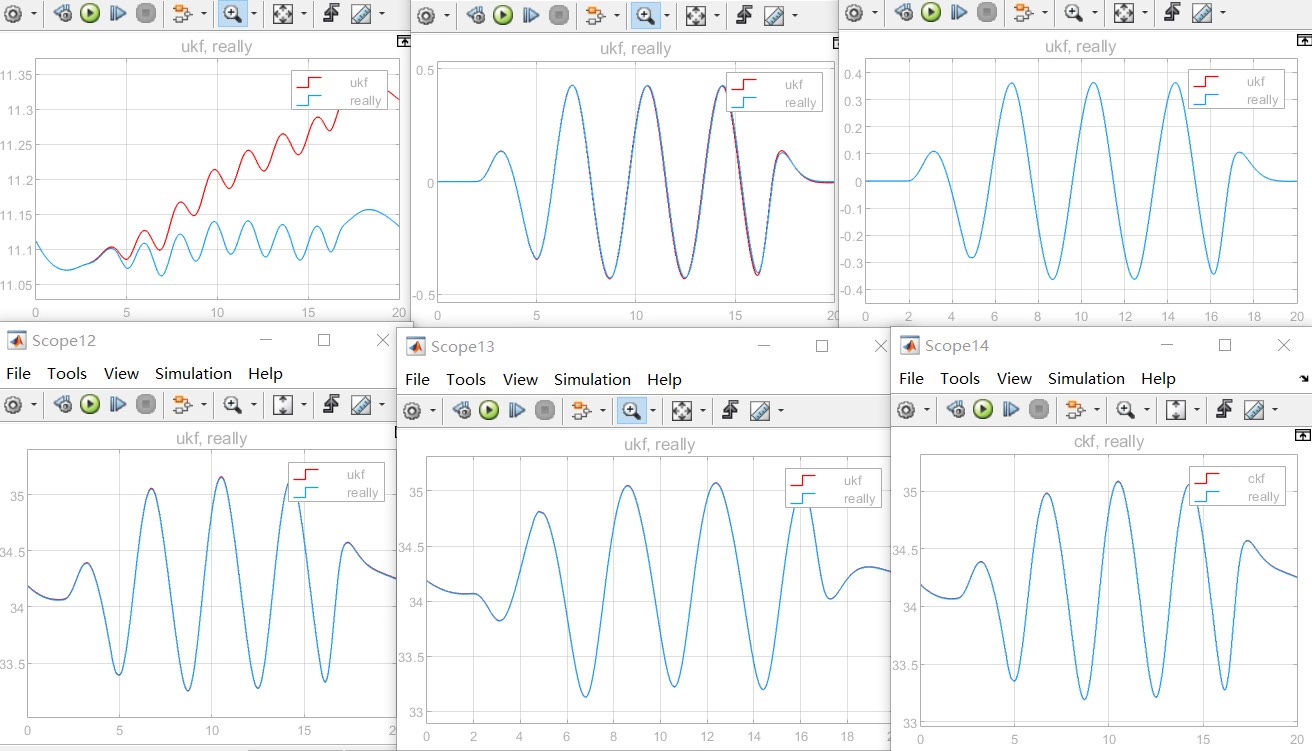
本模型基于Simulink与Carsim联合仿真,这种方式能很好地结合两者优势。Simulink方便搭建各种控制和估计模型,Carsim提供高精度的车辆动力学真实参数。整个模型和代码都是我亲手编写,一方面是为了深入理解车辆状态估计的原理和实现过程,另一方面也方便自己后续参考和学习。基于分布式驱动电动汽车的车辆状态估计,采用的是无迹卡尔曼(ukf)观测器,可估计包括纵向速度,质心侧偏角,横摆角速度,
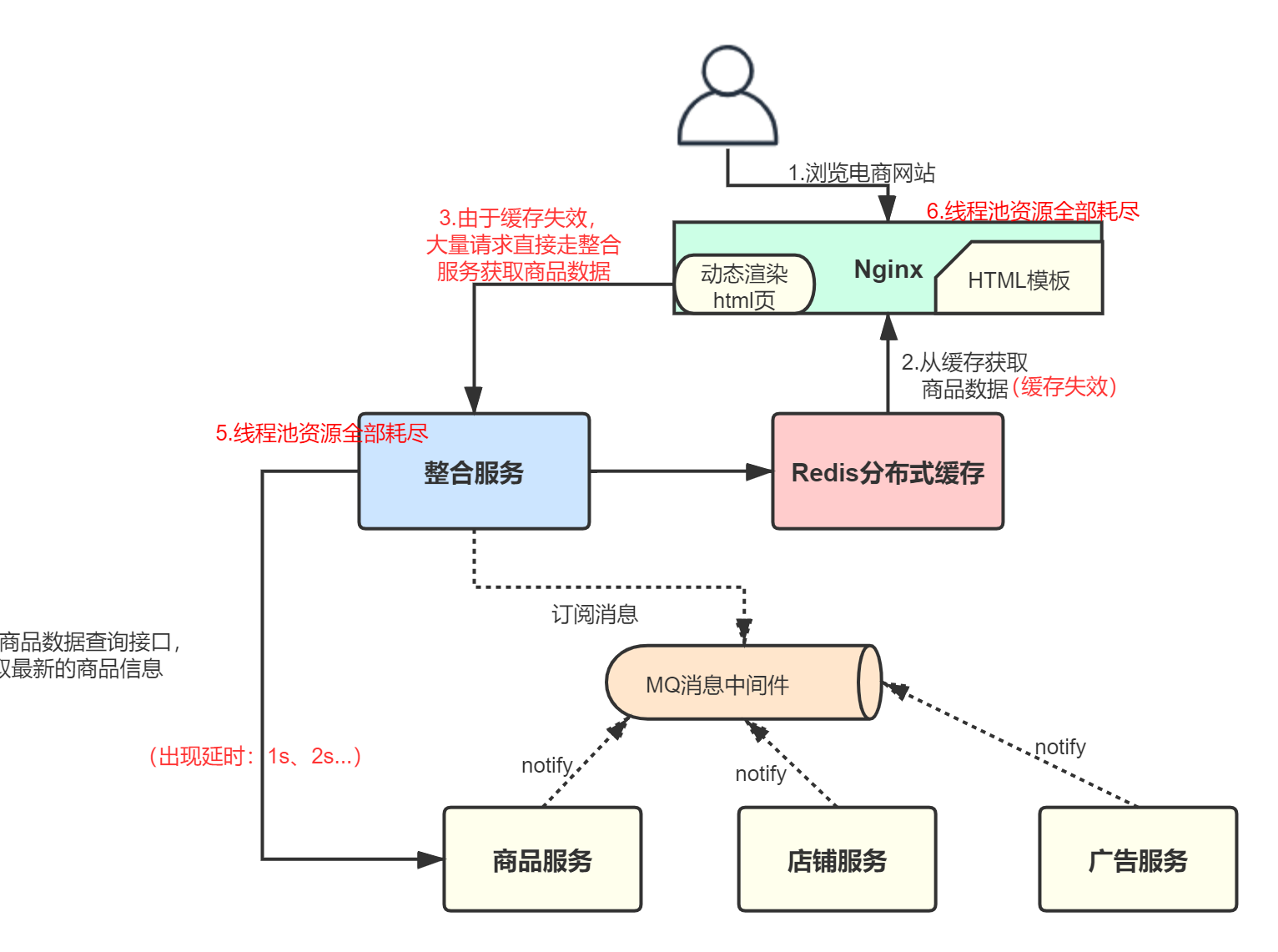
分布式系统中服务与服务之间的依赖错综复杂,一种不可避免的情况就是某些服务会出现故障,导致依赖于他们的其他服务出现远程调度的线程阻塞。某个服务的单个点的请求故障会导致用户的请求处于阻塞状态,最终的结果是整个服务的线程资源消耗殆尽。由于服务的依赖性,会导致依赖于该故障服务的其他服务也处于线程阻塞状态,最终导致这些服务的线程资源消耗殆尽,知道不可用,从而导致整个服务系统不可用,即雪崩效应。为了防止雪崩效
写文章注册登录首页下载App×微服务架构的服务与发现-Spring Cloud1 为什么需要服务发现简单来说,服务化的核心就是将传统的一站式应用根据业务拆分成一个一个的服务,而微服务在这个基础上要更彻底地去耦合(不再共享DB、KV,去掉重量级ESB),并且强调DevOps和快速演化。这就要求我们必须采用与一站式时代、泛SOA时代不同的技术栈,而Spring Cloud就是其中的佼佼者。DevO
OpenCV作为一个功能全面、社区活跃的开源库,极大地降低了计算机视觉领域的入门门槛。从最基本的图像I/O到复杂的特征提取与机器学习模型集成,它提供了一条清晰的学习路径。本文所介绍的核心技术与应用只是OpenCV强大功能的冰山一角。随着学习的深入,你将会接触到机器学习模块(集成了许多经典算法)、深度学习模块(支持加载和运行主流框架训练的模型,如TensorFlow、PyTorch)、以及针对计算摄
站在Java 20的坐标回望,那些被书写的每一行代码,都是一代开发者对技术本质的持续叩问。从Eric Gamma的Design Patterns: Elements of Reusable Object-Oriented Software到今天分布式系统的设计范式,我们会发现:所有伟大的软件工程实践,都是对计算机科学基本原理的持续重诘与回应。基于ModeShape的类型推导引擎,结合AST扫描与统
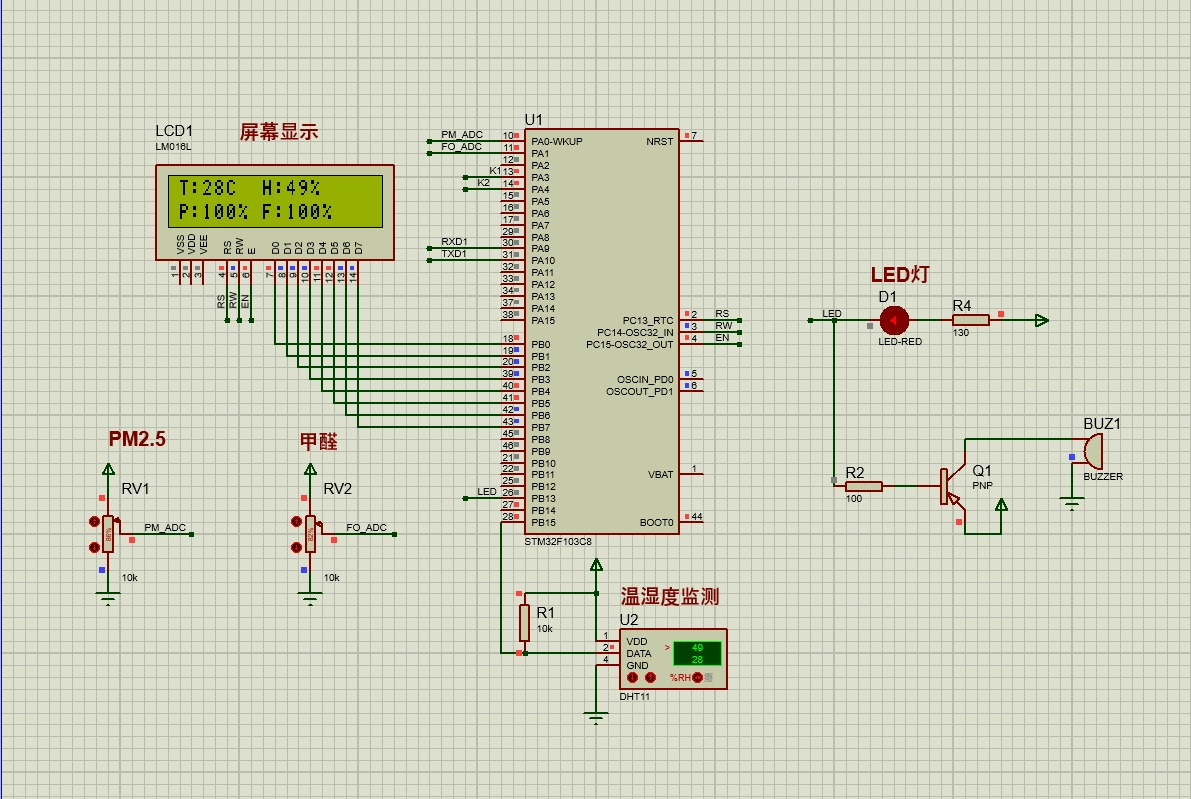
基于51单片机的空气浓度检测系统仿真可检测温湿度,甲醛,pm2.5等空气质量浓度在当下,空气质量越来越受到大家的关注,今天咱们就来聊聊基于 51 单片机打造的空气浓度检测系统仿真,它能检测温湿度、甲醛、PM2.5 等空气质量关键指标。
先说个有趣的发现:用Maxwell提取的磁链特性曲线在Simplorer里跑仿真时,电流波形比传统等效电路模型仿真结果足足多了15%的谐波分量——这就是磁饱和效应在作怪。仿真使用Maxwell搭建了经典磁阻电机模型,在Simplorer中搭建了功率主电路,利用Simulink完成开关控制。仿真使用Maxwell搭建了经典磁阻电机模型,在Simplorer中搭建了功率主电路,利用Simulink完成
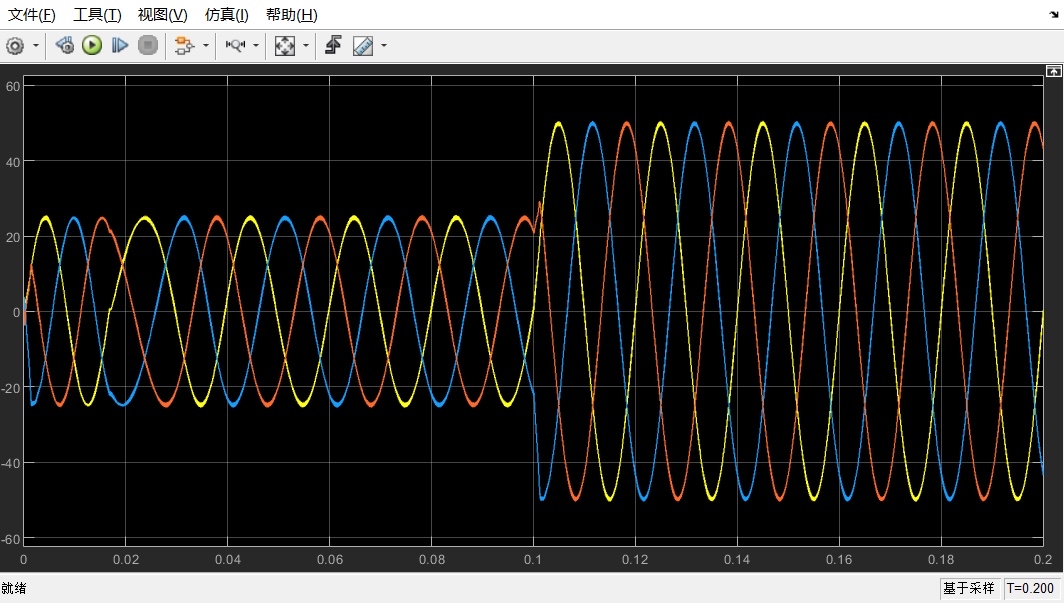
三相LCL型并网逆变器 MATLAB内含:SPWM模块,LCL滤波结构,有源阻尼电容电流比例反馈模块,PI控制器模型采用dq轴电流矢量控制。模型图、电网电压和并网电流波形图如下。适用matlab2018及以上版本在电力电子领域,三相 LCL 型并网逆变器因其出色的滤波性能,在可再生能源并网等应用中占据重要地位。今天咱就唠唠如何在 MATLAB 环境下搭建它,并且深入剖析其核心模块。
基于小信号建模的下垂控制稳定分析,文章完全浮现。关键词:微电网,下垂控制,小信号模型,根轨迹,稳定性。
飞轮储能系统的建模与MATLAB仿真(永磁同步电机作为飞轮驱动电机)不是模型嘿,各位技术爱好者!今天咱们来聊聊飞轮储能系统的建模以及用 MATLAB 进行仿真的事儿,这里的飞轮驱动电机用的是永磁同步电机。飞轮储能系统可是个很有潜力的技术,在很多领域都能发挥大作用,比如电网调峰、不间断电源等等。
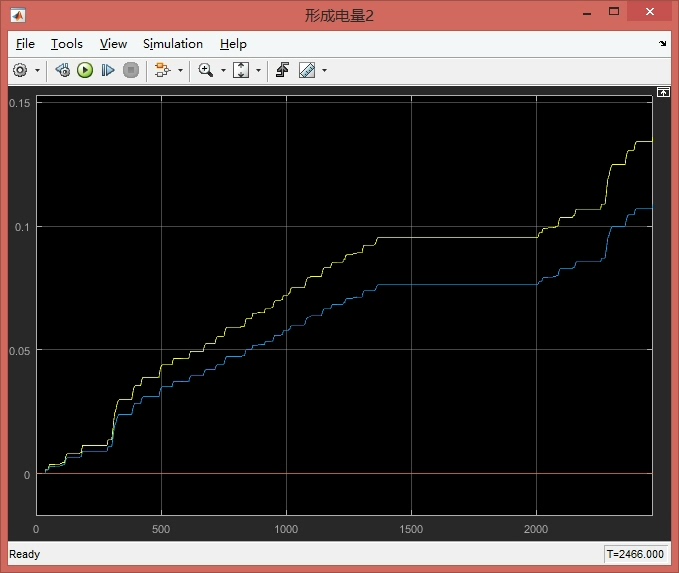
制动能量回收Simulink模型四驱制动能量回收simulink模型四驱电动汽车simulink再生制动模型MATLAB再生制动模型/制动能量回收模型电动车电液复合制动模型原创!原创!原创!刹车回能模型电机再生制动模型目标车型:前后双电机电动汽车/轮毂电机电动汽车模型包括:轮毂电机充电模型/电池发电模型/控制策略模型/前后制动力分配模型/电液制动力分配模型/输入模型(注:控制策略模型,因此整车参数
两电平三相并网逆变器,有限控制集模型预测控制,控制部分采用代码编程实现,输出电流电压波形如下,带参考文献,适合初学者。可根据自己需求设置相应系统参数。最近在实验室折腾三相并网逆变器控制,发现有限控制集模型预测控制(FCS-MPC)这玩意儿特别适合刚入门的同学上手。今天就带大家用Python代码实现这个算法,边写代码边理解控制逻辑。
当我们学习完hystrix,首选想到的是它能不能结合起feign起到远程调用的作用,答案肯定是可以的。
通过在 Spring Boot 项目中集成 Hystrix,可以帮助开发者有效应对服务调用的各种故障场景。Hystrix 提供的熔断器、降级、隔离策略等功能能够显著提升系统的稳定性和容错能力。在实际应用中,开发者可以根据需要调整 Hystrix 的配置,灵活使用不同的隔离策略。同时,通过 Hystrix Dashboard,可以实时监控系统中各个服务的运行状况,及时发现问题并做出调整。集成 Hys
【代码】maven中导入spring-cloud-starter-netflix-hystrix出现错误。
错误现象UT005023: Exception handling request to /actuator/hystrix.streamgithub上的issue解决方案查看github代码发现在master分支上已经将这个问题修复,但是当前maven中央仓库最新jar包1.5.18中并没有修复。解决方案: 自己打一个jar包覆盖掉原来的jar包我是自己打了包一个1.5.19版本的jar包放到公司
熔断开启:所有请求不走接口直接走fallback方法熔断开启一段时间之后会打开半熔断状态。半熔断状态:允许少量请求走半熔断状态如果响应成功则关闭熔断 如果响应失败则继续开启熔断。熔断关闭:接口发生短路则走fallback方法如果连续几次之后则会开启熔断状态。3.启动类添加注解@EnableHystrix。1.添加pom.xml文件。4.feign注解修改。
一、hystrixhttps://blog.csdn.net/zjcsuct/article/details/78198632二、实现方式1.通过注解实现2.AOP实现3.继承方式实现三、hystrix监控1.单机监控修改项目配置1、pom.xml<dependency><groupId>com.n...
Hystrix是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提升系统的可用性与容错性。Hystrix主要通过以下几点实现延迟和容错。包裹请求:使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立线程中执行。这使用 了设计模式中的“命令模式”。跳闸机制:当某服务的错误率超过一定的阈值时,Hystrix可以自动或手动跳闸,停止请求该
1、引入依赖2、配置这里可以配置多个网关,我在这里配置了两个,通过数组下标的方式对每一个网关进行配置3、编码先创建一个类继承GlobalFilter和Ordered,在重写的filter方法中编写逻辑需求,我这里是开头为 /1comsumer/ 的请求需要登录,返回了一个字符串。
项目组具体参数配置:单体服务TPS:800/S#并发执行的最大线程数,默认10hystrix.threadpool.default.coreSize=1000#配置是让Hystrix的超时时间改为2秒 ,默认为1秒hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=1000#隔离策
springcloud中fegin调用常见问题注: 本文基于Springcloud Edgware版本一、fegin调用首次失败问题1、Fegin简介:feign是一个声明式的伪Http客户端,它使得写Http客户端变得更简单。使用Feign,只需要创建一个接口并注解。它具有可插拔的注解特性,可使用Feign 注解和JAX-RS注解,Feign 整合了Ribbon。2、原因分析:feg...
Resilience4j 作为轻量级替代品,提供更灵活的容错机制,支持 Java 8+ 和函数式编程。本指南将逐步讲解如何配置 Resilience4j 实现超时、重试和熔断功能,确保服务弹性。通过以上配置,Resilience4j 能有效替代 Hystrix,提升微服务的容错能力。建议从简单场景开始,逐步添加规则,确保系统稳定。例如,一个外部服务调用:先设置超时,失败后重试,如果连续失败则触发熔
maven 配置<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.0.RELEASE</version><...
如下图的过程所示,灾难性雪崩形成原因就大致如此:服务提供者不可用。如:硬件故障、程序BUG、缓存击穿、并发请求量过大等。重试加大流量。如:用户重试、代码重试逻辑等。服务调用者不可用。如:同步请求阻塞造成的资源耗尽等。雪崩效应最终的结果就是:服务链条中的某一个服务不可用,导致一系列的服务不可用,最终造成服务逻辑崩溃。这种问题造成的后果,往往是无法预料的。
压测环境:4C8G云主机,1000并发请求。
Hystrix:微服务韧性演进史 摘要:本文探讨了微服务架构中韧性设计的重要性与演进历程。首先分析了微服务环境下服务间调用增多、故障传播风险加剧等挑战,强调了构建韧性系统的必要性。随后重点介绍了Netflix Hystrix的诞生背景及其核心机制,包括熔断器模式、隔离、降级和限流等功能。通过Java代码示例展示了Hystrix的基础使用方法,演示了如何通过继承HystrixCommand类来实现支
本文探讨了Hystrix动态刷新配置的两种实现方案。首先分析了静态配置的局限性,如缺乏灵活性、响应迟缓等问题,对比了动态配置的实时调整、零停机更新等优势。随后详细介绍了基于Netflix Archaius和Spring Cloud Config的两种动态配置实现方式,包括核心机制、依赖引入和配置初始化步骤。文章通过代码示例展示了如何将动态属性绑定到Hystrix,实现不重启服务即可调整超时时间、熔
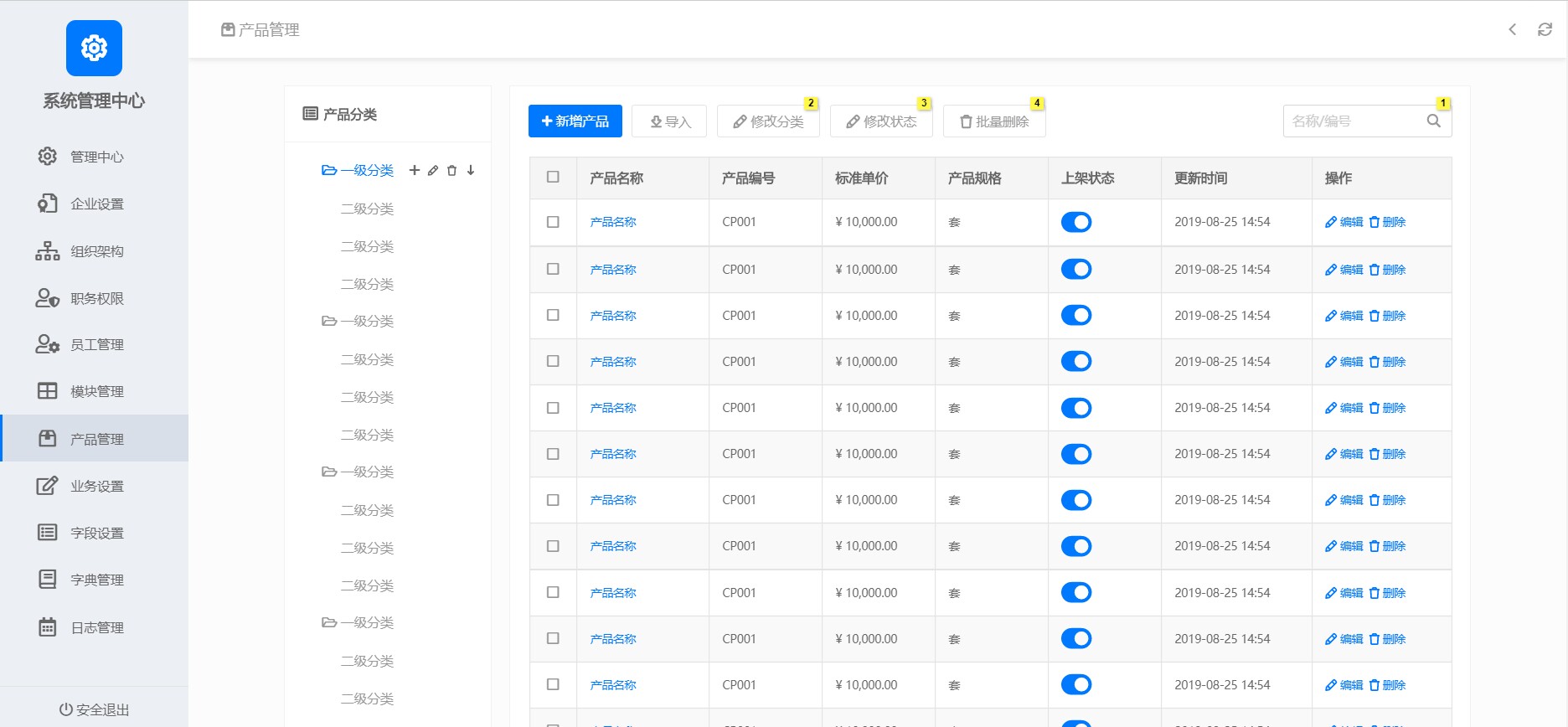
CRM后台原型模板#产品原型#Axure#文件大小6.21M,系统业务分为12个核心模块:管理中心、系统公告、企业设置、组织架构、职务权限、员工管理、模块管理、产品管理、业务设置、字段设置、字典管理、日志管理等。对于想做产品的同学或者想深入了解CRM后台系统的朋友,极具研究学习价值和办公使用价值!致力于让产品人专注产品本身,不受原型实现的困扰~适合人群:互联网产品经理、学习使用axure的同学最近
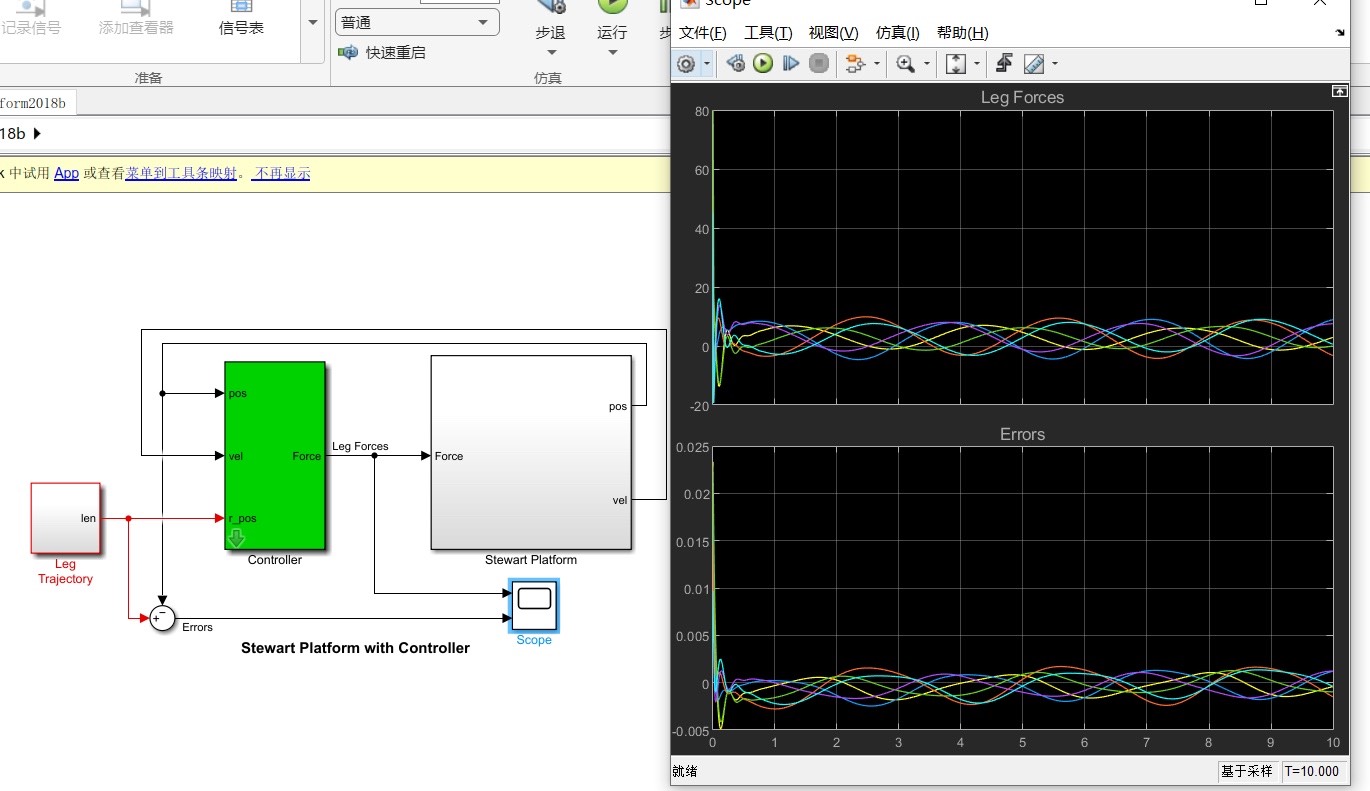
MATLAB仿真Gough-Stewart并联机器人斯图尔特6自由度并联机器人逆运动学仿真 动力学控制pid控制1.搭建了六自由度Stewart并联机器人simulink/simscape仿真模型2.建立了逆向运动学仿真 输入位置和姿态求解各个杆长3.运用pid控制器进行动力学跟踪控制使用MATLAB进行了Gough-Stewart并联机器人的仿真。首先,我搭建了一个六自由度的Stewart并联机
通过掌握 Python 的高级编程技术和优化策略,开发者不仅能高效构建智能化应用,还能显著提升开发效率。在人工智能与自动化技术蓬勃发展的今天,Python 以其简洁的语法、丰富的生态和强大社区支持,成为智能应用开发的首选语言。本文聚焦 Python 的高级编程技术,结合实战案例,探讨如何高效构建智能应用,并通过开发效率优化策略提升生产力。- PyTorch 和 TensorFlow:作为主流的深度
全文概览文章目录为什么需要hystrix特色功能项目准备接口测试业务隔离线程隔离信号量隔离服务降级触发条件不足服务熔断服务限流请求合并HystrixCollapser工作流程HystrixDashboard聚合监控新建hystrix-turbinepomyml启动类源码为什么需要hystrixhystrix官网地址githubHystrix同样是netfix公司在分布式系统中的贡献。同样的也进入的
本章我主要讲解了Hystrix的两种资源隔离技术:线程池隔离和信号量隔离,并分别针对它们的用法和使用场景做了介绍。相信读者已经对Hystrix的主要功能有了一个初步了解,下一章我将讲解Hystrix的整个请求流程。
本章,我介绍了Hystrix的熔断功能,读者要特别注意断路器的三种状态之间的转换关系,Hystrix对所有command请求进行监控统计,当异常请求达到一定比例时,就会触发熔断机制。
hystrix
——hystrix
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵


 脑启社区
脑启社区

 AtomGit开源社区
AtomGit开源社区


 腾讯云开发者社区
腾讯云开发者社区


 开源鸿蒙跨平台开发者社区
开源鸿蒙跨平台开发者社区
 AI硬件创业社区
AI硬件创业社区

 魔乐社区
魔乐社区













 松山湖开发者村综合服务平台
松山湖开发者村综合服务平台

 2048 AI社区
2048 AI社区


 智能体开发者社区
智能体开发者社区

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 HarmonyOS开发者社区
HarmonyOS开发者社区

 深开鸿 技术专区
深开鸿 技术专区