




- @qq_33333654
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
gateway报错:org.springframework.cloud.gateway.support.NotFoundException: Unable to find instance for localhost配置:浏览器访问:http://localhost:8888/cloud_producer/get (cloud_producer是我注册到注册中心的一个客户端)...
首先我这里有两张bpmn的图和其对应的xml文件:上图对应的xml:<?xml version="1.0" encoding="UTF-8" standalone="yes"?><definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL" xmlns:activiti="http://acti...
报错:Invalid bound statement (not found): com.xx.xx.mapper.xxMapper背景说明:我在通过idea在maven中创建了子工程后,在子工程的resources文件下创建文件夹,操作如下:1、选中resources点击右键,点击New,点击Directory2、输入: mapper.biz3、点击确定,然后创建mapper的xml文件启动项目正
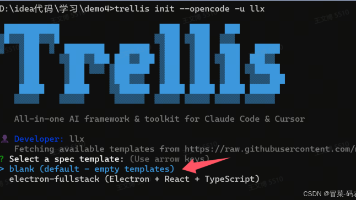
本文介绍了使用OpenCode和Trellis进行AI辅助开发的完整流程。首先需要安装Node.js、OpenCode和Trellis工具,然后在项目目录初始化Trellis并连接GPT授权。文档详细说明了如何切换模型和模式(Plan/Trellis-Plan),并通过菜单管理案例演示了从设计文档生成代码的全过程,包括定义代码规范、生成代码、代码审查及回退操作。文中保留了多处图片占位标记,便于后续
spring.http.server.maxFileSize和spring.http.server.maxRequestSize的值,效果是一样的。然后在application.properties文件中配置。原因:上传文件的请求有个默认配置最大值是2M 超出了最大值。方法二,重写config配置类。
展示效果如图:可进行拖拽、删除,删除后div会回到上面的待拖拽区域源码下载地址:点击这里html代码如下:<!-- saved from url=(0045)http://www.jq22.com/demo/jquery-tdfz20160803/ --><html><head><meta http-equiv="Content-Type" content
错误日志:[Err] 1055 - Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'hema_app.a.iid' which is not functionally dependent on columns in GROUP BY clause; this is..
Redis中另一个常用的数据结构就是list,其底层有linkedList、zipList和quickList三种存储方式。与Java中的LinkedList类似,Redis中的linkedList也是一个双向链表,由一个个节点组成的。Redis中借助C语言实现的链表节点结构如下所示:pre指向前一个节点,next指针指向后一个节点,value保存着当前节点对应的数据对象。listNode的示意图
众所周知,java1.7的时候hashMap结构还是【数组+链表】,而在1.8版本结构变为了【数组+链表/红黑树】,当链表长度达到8时,自动转换为红黑树结构。那么为什么java1.8要对hashMap的数据结构中加入树呢?答案:提高查找效率。此前hashMap中的数据采取【数组+链表】的存储结构,桶数组会将通过hash算法将key值计算得来的相同哈希值数据存储在对应的链表中,而随着链表的数据增多,
创建多个线程去执行不同的任务,如果这些任务之间有着某种关系,那么线程之间必须能够通信来协调完成工作。生产者消费者问题(英语:Producer-consumer problem)就是典型的多线程同步案例,它也被称为有限缓冲问题(英语:Bounded-buffer problem)。该问题描述了共享固定大小缓冲区的两个线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用