




- @Joker_ZJN
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
SSE(Server-Sent Events)技术解析 SSE是一种基于TCP的应用层协议,支持服务器向客户端单向推送消息。其核心特点是: 连接建立:客户端发起SSE请求,服务器响应后建立持久连接 数据格式:采用标准的事件流格式(text/event-stream),包含id、event、data等字段 实现方式: 利用Servlet 3.0的AsyncContext实现连接持久化 Spring框
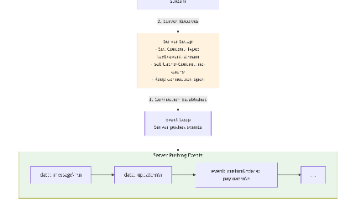
PostgreSQL的JSONB类型提供了高效操作JSON数据的能力。它采用树形结构存储数据,通过排序和压缩优化查询性能。JSONB支持丰富的查询操作(->、->>、#>等),条件过滤(@>、?等),以及修改操作(||、-、jsonb_set等)。此外,还提供聚合函数和JSONPath查询功能。底层数据结构分为整体信息、位置信息和数据存储区三部分。为提高查询效率,Po

PostgreSQL正成为越来越多企业的数据库选择,其与MySQL的核心差异体现在设计哲学上。PostgreSQL作为"重装部队",支持丰富的数据类型(JSONB、数组、地理空间等)和复杂查询,提供GIN、GiST等特色索引优化高级查询,但配置相对复杂。MySQL则作为"轻骑兵"追求简单快速,适合常规业务场景。两者事务隔离级别相同,但PostgreSQL采用

一文详解如何使用JAVADOC来生成标准JAVA API文档。

一文详解如何在IDEA中使用merge/rebase合并代码、解决冲突。

一文详解各种情况下的git的版本回滚,五分钟,看完就会。

IDEA git操作大全,cherry pick、revert、squash等等,持续更新中......

一文详解HBase下载安装教程。

看懂这一篇,就能理解分布式数据库的核心,详聊分布式数据库的鼻祖bigtable。

一文快速入门kibana数据可视化,用kibana来搭建数据大屏
