




- @u010438035
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用cephadm部署ceph。处理ssh默认端口修改问题。上面命令中的mon.test要根据实际情况修改。更进一步,可以将阈值从默认的5%改到3%

二、英特尔® Memory Latency Checker (英特尔® MLC) 是一种工具,用于测量内存延迟和 b/w,以及内存延迟如何随着系统负载的增加而发生变化。它还提供了进行更精细化调查的多个选项,其中也可以测量从特定内核集到高速缓存或内存的 b/w 和延迟。测试发现数组大小对测试结果影响比较大,不同的编译器也对测试结果有影响(gcc的测试结果高于icc的);软件是内存带宽性能测试的基准工
手机打开开发者模式,使用USB线连接至个人PC,连接方式选择传输文件,使用adb devices测试连接,第一次显示未授权,打开手机,点击授权,再次查询就可以了。更新gradle.properties后要点击sync同步一下。Android如何打包release包。【RadioGroup自动换行】来自。

首先:sudo apt install overlayroot 安装一下软件然后编辑配置文件:/etc/overlayroot.conf。
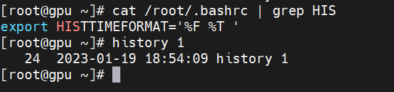
在对linux系统进行操作的时候经常多开好几个ssh窗口,执行很多命令,如果操作内容很多,时间一久就会忘记,很有必要把每一次的操作记录保存下来用于日后查看;还有一种情况就是多人协作的场景,经常会出现不同人在同一台服务器上同时操作,操作的内容互相影响,这时也非常需要有一个审计日志,可以很方便的查看哪个用户做了什么操作,执行了什么命令。以下是记录 bash 命令日志的参考方法,借此可以实现Linux系
在webui 界面训练好模型之后点击“Export”选项卡,然后,在“模型路径”中输入原始模型路径,然后在“检查点路径”中选择自己微调得到的 checkpoint路径,然后在“最大分块大小(GB)”中设置为4,同时设置一下导出目录,最后点击“开始导出”,就可以看到输出的模型了。按照自己需求配置训练参数,所有的参数都配置好之后,点一下“预览命令”,确认命令没有问题之后,就可以点击“开始”进行训练了。

初次打包需要下载一些依赖包,需要能够连接到github。

受资源限制,本次只测试meta-llama/Meta-Llama-3.1-8B-Instruct。升级transforms至4.43.1后解决。于是改用魔搭社区提供的版本。
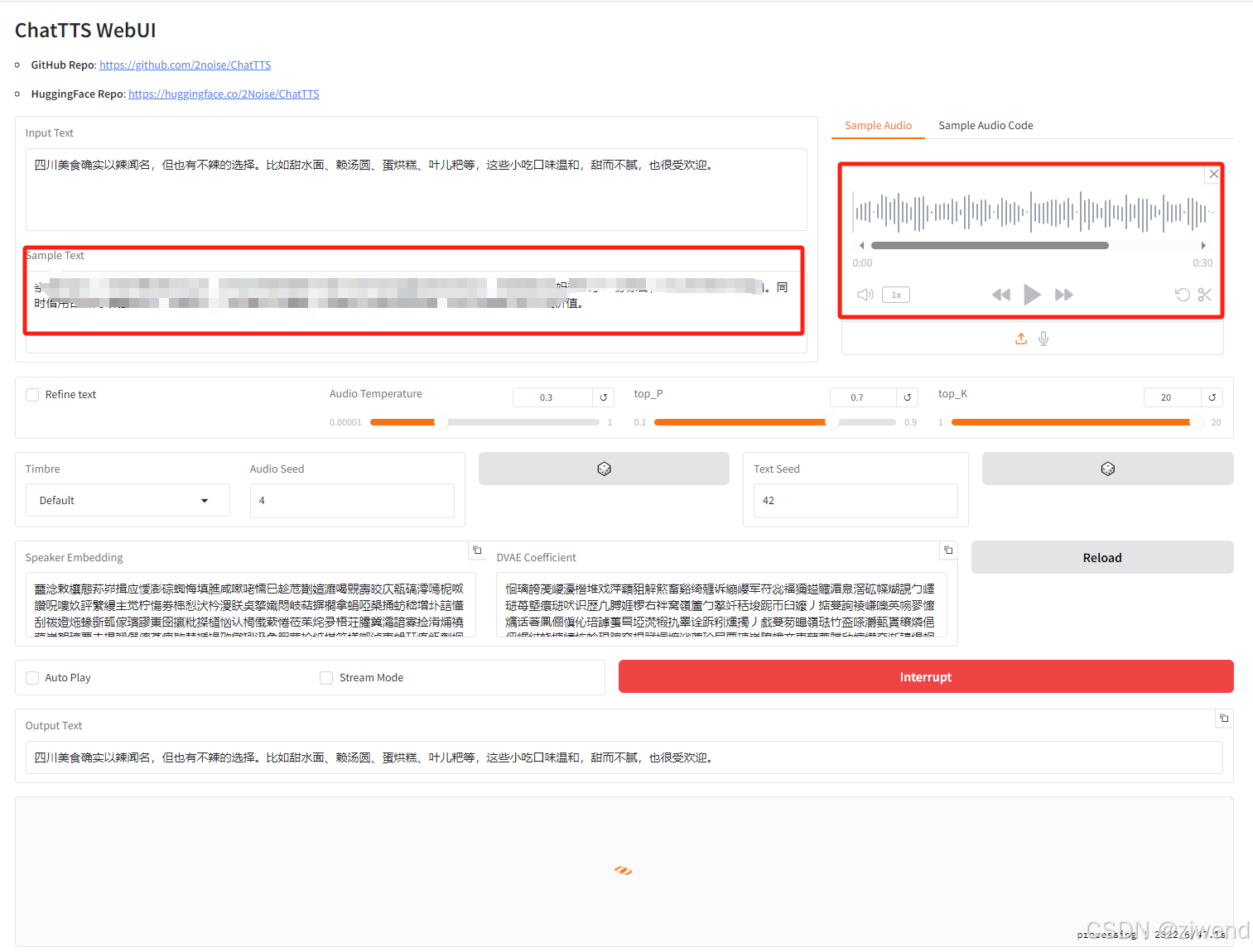
试用了chatTTS官网推荐的https://voicv.com/voice-cloning进行语音克隆,发现生成的音频效果很差,无法使用。合成的语音比较完整,有点声音克隆的效果,但是声音忽高忽低,音色也不固定,一段文字,前半部分和后面感觉不像是同一个人说的。这个生成的内容和cosyvoice一样,中间有缺失,而且缺失的地方是一致的,不知道二者底层是否使用的是同样的处理逻辑;以上步骤繁琐复杂,可以
测试时发现,刚开始逻辑简单的时候,大模型给出的代码闭着眼睛去应用就可以,但是后面一旦逻辑加的越来越多的,大模型给出的修改代码一定要仔细检查一下。参考下图创建一个小程序项目,推荐使用智能创建,可以使用自然语言描述一下这个小程序的页面具体布局,实现的功能等,然后这里会调用腾讯的混元大模型自动创建一个项目,会生成基本的页面布局,以及一部分页面逻辑。3、如果发现当前使用的大模型不能满足需求,可以尝试切换为
