




- @weixin_43778179
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
冯丹教授表示:“从技术趋势来看,高性能异构算力、高速网络、大存力新型盘框、算子卸载等技术的发展,带来了数据中心架构的变革,加速了以CPU为中心的耦合架构走向彻底存算分离、资源池化共享的以数据为中心的Diskless架构,这种架构进一步简化了数据中心基础设施构建,能够实现存力和算力资源的集约高效发展,已经成为大规模数据中心发展的重要技术趋势。通过计算语义的卸载,存储直出语义接口,主机侧软件栈打薄,减

ms_fast_dispatch的调用是由Pipe的接收线程直接处理的,因此性能比前者要好。5.否则调用函数in_q->enqueue(m, m->get_priority(), conn_id) , 本函数把接收到的消息加入到DispatchQueue的mqueue 队列里, 由DispatchQueue的线程调用ms_dispatch处理。需要注意的是,这里的消息发送都是异步发送,请求的ack

下载astyle-3.4.6-x64.zip,解压缩文件,进入astyle-3.4.6-x64目录下取出astyle.exe文件,将其放到要存放的目录下,这里是放在C:\Program Files (x86)\Source Insight 4.0文件夹下。1. 下载AStyle.exe工具,官网地址:https://sourceforge.net/projects/astyle/files/-H
把N+M份数据分别保存在不同的设备或者节点中,并通过N+M份中的任意N份数据块还原出所有数据块。SHEC编码方式为SHEC(K,M,L),其中K代表原始数据块data chunk的数量,M代表校验块parity chunk的数量,L代表计算校验块parity chunk时需要的原始数据块data chunk的数量。其最大允许失效的数据块为:ML/K。以SHEC(10,6,5)为例,其最大允许失效的

计算机科学中最有趣的事情之一就是编写一个人机博弈的程序。有大量的例子,最出名的是编写一个国际象棋的博弈机器。但不管是什么游戏,程序趋向于遵循一个被称为Minimax算法,伴随着各种各样的子算法在一块。Minimax算法又名极小化极大算法,是一种找出失败的最大可能性中的最小值的算法。Minimax算法常用于棋类等由两方较量的游戏和程序,这类程序由两个游戏者轮流,每次执行一个步骤。我们众所周知的五子棋
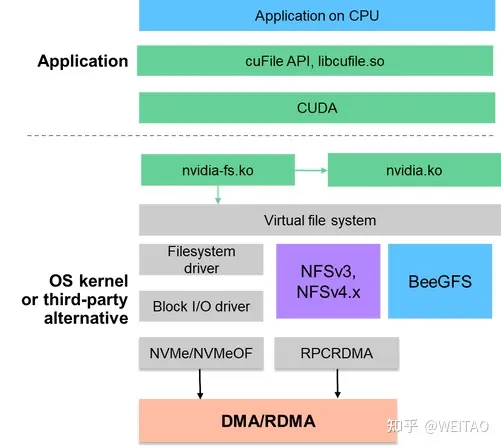
如下图所示, 通过在VFS层嵌入内核模块 nvidia-fs.ko 和 nvidia.ko 来管理GPU 内存地址和CPU RAM及GPU RAM的IO操作,这扩展到了PCI总线允许数据在GPU和网卡之间搬运,元数据仍然存储在CPU RAM,而数据块则允许直接读取到GPU RAM。在这样的新时代,企业需要全新的存储解决方案,才能以高效且经济的方式从容应对来势汹汹的数据洪流。Paraview是一个开
本文结合计算机系统的架构,我们从内存访问的角度,介绍了各种地址空间(虚拟、物理、总线)的概念。以及物理内存和设备内存访问三个方向(CPU->DRAM, CPU -> Device Memory, Device DMA -> DRAM)。最后介绍了DMA 映射编程常用的方法,如果觉得不过瘾,建议继续研究作者参考的内核 Document。

如下图所示, 通过在VFS层嵌入内核模块 nvidia-fs.ko 和 nvidia.ko 来管理GPU 内存地址和CPU RAM及GPU RAM的IO操作,这扩展到了PCI总线允许数据在GPU和网卡之间搬运,元数据仍然存储在CPU RAM,而数据块则允许直接读取到GPU RAM。在这样的新时代,企业需要全新的存储解决方案,才能以高效且经济的方式从容应对来势汹汹的数据洪流。Paraview是一个开
rgw_thread_pool_size:rgw前端web的线程数,与rgw_frontends中的num_threads含义一致,但num_threads 优于 rgw_thread_pool_size的配置,两个只需要配置一个即可;这两个参数是管理filestore的目录分裂/合并的,filestore的每个目录允许的最大文件数为: filestore_split_multiple * abs

在最近上线过程中遇到cpu占用率过高问题由于问题已解决,此时仅重现操作方法1.先用top命令,找到cpu占用最高的进程 PID如上图2.再用ps -mp pid -o THREAD,tid,time查询进程中,那个线程的cpu占用率高 记住TID3.jstack 29099 >> xxx.log打印出该进程下线程日志4.sz xxx....