登录社区云,与社区用户共同成长
邀请您加入社区
本文探讨了AI Agent时代对Linux系统工具的新需求。传统工具如df遵循Unix哲学,专注于单一功能,依赖工程师通过经验组合信息来理解系统状态。然而AI Agent需要更直接的上下文信息来减少推理步骤,降低操作风险。文章以x df为例,展示了如何整合文件系统类型、挂载属性等关键信息,使Agent能快速判断存储状态。作者指出,未来需要更多工具来显式表达系统隐藏关系,帮助机器可靠操作计算机,而非
静态库(.a文件)是指程序在编译链接时将库的代码完整复制到可执行文件中,程序运行时不再需要外部库文件。静态库在链接阶段被直接嵌入到最终的可执行文件中,形成独立的二进制程序。动态库(.so文件)则采用不同的机制:程序运行时才去链接动态库代码。与动态库链接的可执行文件仅包含所用函数的入口地址表,而非整个目标文件的机器码。在程序执行前,操作系统将动态库从磁盘加载到内存,这个过程称为动态链接。特性静态链接
它具有强大的横向扩展能力,能够通过添加更多的存储节点来提升存储容量和性能。它采用了弹性哈希算法(EC),摒弃了传统的元数据服务器,从而实现了真正的分布式存储架构。这使得 GlusterFs 在处理大规模数据存储时表现出色,广泛应用于云计算、大数据存储等领域。
从磁盘眼中的文件,到操作系统眼中的文件,再到用户眼中的文件,这篇文章都会给予较为完整自洽的解释。需要注意的是,OS以块为基本单位进行IO,所以一个DataBlock不是一个扇区,而一般是4KB,而若干个inode结构体因为单个体积太小所以挤在一起,不是一个inode一个块。不同文件系统的inode类型是不同的,所以需要每个文件系统提供inode的创建方法。,包括每个分组的大小,分组内的结构划分,分
数据恢复技术是计算机存储领域的重要分支,其核心原理基于文件系统对删除文件的处理机制。当文件被删除时,操作系统通常只是标记存储空间为可用,而非立即擦除数据。这种设计使得通过专业工具扫描磁盘原始数据成为可能。随着技术进步,现代数据恢复工具已融合深度学习、量子计算等前沿技术,显著提升了碎片化文件和加密数据的恢复成功率。在工程实践中,数据恢复技术广泛应用于误删文件恢复、系统崩溃修复等场景。2026年的专业
文件系统是操作系统管理存储的核心机制,却常常被开发者视为“黑盒”。本文将从磁盘硬件原理出发,深入浅出地剖析 Linux 中经典的ext 文件系统如何组织数据、管理文件,并揭示inode、块、软硬链接等关键概念的底层实现。通过理解这些机制,你不仅能更高效地使用文件系统,还能在调试、优化乃至数据恢复时多一份底气。让我们一起揭开文件系统的神秘面纱!
本期博客详细讲解了ext文件系统,包括inode编号和块号,路径解析与缓存,如何存储大文件,如何找到文件在那个分区等等
本文深入解析了Linux Ext2文件系统的存储机制。首先介绍了磁盘的物理结构(磁道、扇区、柱面等)和逻辑寻址方式(CHS与LBA转换)。重点阐述了Ext2文件系统的组织方式:将磁盘划分为块组,每个文件由inode存储属性信息(权限、大小等)和数据块指针,而文件名则通过目录项与inode关联。通过分析ext2_inode结构体,解释了文件属性存储的细节,并说明了如何通过inode编号定位文件内容。
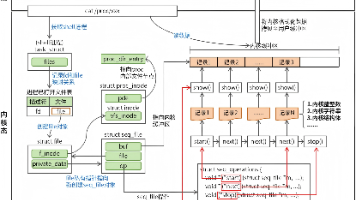
proc文件系统介绍,proc文件系统内核实现原理分析、seq_file机制、proc文件读取示例分析。
Linux initramfs深度解析: 从内核启动到根文件系统的桥梁(3)
Linux initramfs深度解析: 从内核启动到根文件系统的桥梁(5)
Linux,文件系统,rootfs
ext2是Linux经典的非日志文件系统,采用块组机制将磁盘划分为多个自包含单元。每个块组包含超级块、块组描述符表、块位图、inode位图、inode表和数据块。文件通过inode的15个指针(12个直接、1个间接、1个双重间接、1个三重间接)寻址,支持最大2TB单文件。目录作为特殊文件存储线性排列的目录项。ext2具有冗余备份、局部性优化等特点,但不支持日志,异常掉电后需完整扫描修复。该设计为后
linux kernel 在启动阶段后期,分析设备树匹配相应的driver在用sysfs构建系统的设备和驱动的连接和分类信息。在sysfs devices下会有设备major 和minor信息。/dev目录下是系统中所有的设备节点,设备节点就是设备文件,操作设备文件就是操作具体的设备。设备文件分为字符设备和块设备文件。创建这些文件的方式在古早时期就是mknod 命令,它参数就是设备文件名称和maj
本文系统讲解了 Ext 系列文件系统的核心原理,从最底层的磁盘硬件结构开始,逐步深入到文件系统的组织管理和文件操作机制。首先,磁盘的物理结构包括盘片、磁头、磁臂和主轴,存储结构分为磁道、扇区和柱面。早期的 CHS 寻址方式存在 8.4GB 的容量限制,现代磁盘采用 LBA 寻址方式,将三维物理结构抽象为一维扇区数组,由磁盘固件完成两者之间的转换。其次,文件系统引入了块、分区和 inode 三个核心
本文深入探讨了Linux内核中文件管理的机制。首先阐述了 Linux 一切皆文件的设计理念,硬件设备也被抽象为文件。其次详细分析了文件描述符的本质—文件描述符表的下标,通过这个整数可以找到对应的struct file结构体。文章还解析了stdin、stdout、stderr的默认文件描述符0/1/2,并讲解了重定向的实现原理。此外,文章对比了用户级缓冲区和内核缓冲区的差异,解释了缓冲区的刷新策略及
本文详细解析了Linux中/etc/fstab文件的配置方法,重点介绍了5个关键参数以避免系统重启后挂载回退只读的问题。通过实际案例和技术分析,帮助管理员正确配置文件系统挂载选项,确保系统稳定性和数据安全。
本文详细介绍了在Linux系统中使用fdisk工具进行磁盘扩容的实战步骤,包括分区表无损重建和文件系统扩容的三种场景。通过精确删除原有分区、重建分区参数设置以及文件系统扩容操作,确保数据安全的同时有效解决磁盘空间不足问题。特别适用于运维人员处理服务器磁盘扩容需求。
本文深入解析 Linux 文件系统中 7 个最常见的错误码(EACCES、ENOENT、ENOSPC、EROFS 等),从现象到根因再到解决方案,帮助开发者和系统管理员快速定位和解决文件系统问题。内容涵盖权限不足、文件不存在、磁盘空间耗尽等典型场景,提供详细的排查命令和实用技巧,是 Linux 系统管理的必备参考。
本文详细介绍了Linux磁盘管理的完整流程,从使用fdisk进行磁盘分区到使用mkfs.ext4格式化文件系统的5个关键步骤。通过实战示例和优化建议,帮助管理员高效完成磁盘扩容和配置,特别适合服务器环境下的存储管理需求。
本文深入解析Linux /proc文件系统的工作原理,从进程信息读取到mount bind隐藏技术的实现机制。通过分析/proc目录结构和内核动态生成机制,揭示ps/top等工具背后的运作原理,并详细讲解如何利用mount bind隐藏进程及相应的检测技术。
本文深入解析Docker容器目录结构,重点介绍三种定位overlay2存储驱动下MergedDir的方法。通过docker inspect命令、find搜索和路径拼接三种技术,帮助开发者高效管理容器文件系统,适用于调试、数据恢复等场景,提升Docker容器运维效率。
主题关键点mkdir-p级联创建,-m指定权限cp复制目录必须加-r,目标目录存在时会作为子目录复制进去mv移动 + 重命名,同一文件系统内极快(只改目录项)rm删除不可逆!rm -rf是双刃剑,慎用软链接ln -s,指向路径,可跨文件系统,目标删除则失效硬链接ln,同一 inode 的多个名字,不可跨文件系统,不可链接目录通配符(任意)、?(单字符)、[](字符集)、{}(展开)
本文深入解析了Linux 5.4.18内核中文件描述符(fd)与struct file的关联机制,详细介绍了从open()系统调用到fd_install的三步流程。通过分析get_unused_fd_flags、do_filp_open和fd_install等关键函数,揭示了Linux文件系统的核心工作原理,为系统编程和性能优化提供了重要参考。
本文深入解析Linux 5.4.18内核中文件描述符(fd)与struct file的三层映射机制,从open()到fd_install()的完整链路。通过剖析fd的分配策略、files_struct的动态管理及struct file的生命周期,帮助开发者优化文件系统性能、排查资源泄漏问题,并理解Linux文件访问的核心原理。
本文深入解析Linux VFS虚拟文件系统的三层抽象架构,揭示其如何统一EXT4、NTFS、FAT32等不同文件系统的访问接口。通过超级块、索引节点、目录项和文件对象四大核心数据结构,VFS在内核层面实现文件系统差异的透明化,为上层应用提供一致的POSIX接口。文章详细剖析了文件打开的全流程、多文件系统共存机制及性能优化策略,是理解Linux文件系统设计的核心指南。
虚拟文件系统(VFS)作为Linux内核的核心子系统,实现了对多种文件系统的统一抽象。其核心原理是通过super_block、inode、dentry和file四大数据结构,构建起应用程序与具体文件系统之间的桥梁。从技术价值看,VFS不仅解决了ext4、XFS等不同文件系统的兼容性问题,还通过dentry缓存等机制显著提升IO性能。在实际应用场景中,无论是常规文件操作、容器技术中的OverlayF
本文介绍了ext系列文件系统的基本原理。首先讲解了磁盘硬件结构,包括盘片、磁头、扇区、磁道和柱面等概念,以及CHS和LBA两种寻址方式。然后阐述了文件系统的基本概念,如块、分区、inode等,并详细说明了ext2文件系统的组织结构,包括块组、超级块、inode表和数据块等核心组件。文章还描述了文件访问流程,涉及路径解析、dentry缓存和挂载机制。最后介绍了软硬链接的实现原理及其区别:软链接是独立
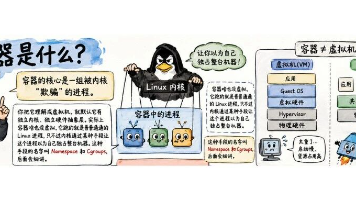
从技术原理来讲的话,容器是基于 Linux 内核的特性,实现了轻量级的进程隔离。通过巧妙运用命名空间(Namespaces)和控制组(Cgroups),容器内的进程拥有自己独立的资源视图,彼此之间互不干扰,就像在不同的小世界里运行。这不仅保障了应用的稳定运行,启动速度可达到秒级,资源利用率大幅提高,单机可以轻松承载数千个容器实例 ,这是传统部署方式难以企及的。
操作系统是计算机系统的核心软件,负责管理硬件资源并提供基础服务。其内核架构决定了系统的性能、安全性和可扩展性,常见的包括宏内核、微内核及混合内核等设计。理解不同操作系统的内核原理、文件系统组织、权限模型和软件生态,对于构建稳定、高效的技术栈至关重要。在工程实践中,这些差异直接影响开发环境搭建、跨平台部署和团队协作效率。例如,Windows的注册表与ACL权限、Linux的FHS标准与包管理器、ma
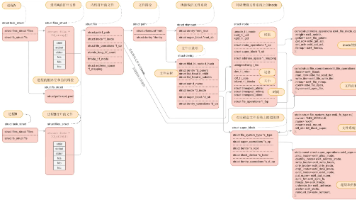
本文摘要:文章首先介绍文件系统的层次结构,分析其组织方式;其次阐述文件系统的全局布局特点,包括存储分布和管理机制;最后重点讨论虚拟文件系统(VFS)的核心功能及其抽象接口,并详细说明文件系统挂载的实现原理和过程,涵盖挂载点的建立与管理等关键技术。全文系统性地解析了文件系统架构的关键组成部分及其交互机制。
本文深入探讨Python文件系统操作中的三个关键避坑要点:绝对路径的正确使用、符号链接的安全处理以及跨平台编码问题。通过具体代码示例和最佳实践,帮助开发者解决脚本在不同环境下运行时常见的路径解析错误、符号链接循环和文件名编码异常等问题,提升代码的健壮性和跨平台兼容性。
文章摘要: 文件存储管理是外存与文件间的空间分配机制,类比内存管理。主要方法包括: 空闲表法:记录连续空闲区,适合连续分配; 空间链表法:离散或连续分配均可,分空闲盘块链(单块为节点)和盘区链(连续块为节点); 位示图法:通过字号/位号与盘块号转换管理空间; 成组链接法:结合索引分配思想,通过栈结构动态管理空闲块,分配时逐步弹栈,回收时压栈或处理栈溢出。核心逻辑类似内存分配,但针对外存特性优化。
本文总结了文件操作的核心流程与共享保护机制。文件操作包括创建(分配空间+添加目录项)、删除(释放空间+删除目录项)、打开(加载目录项到内存表)、关闭(移除表项)以及读写操作。文件共享分为硬链接(直接修改索引节点计数)和软链接(创建路径快捷方式),删除规则不同。文件保护提供口令、加密和权限控制三种方式。通过系统调用和内存表管理,实现高效文件访问与多进程共享。(149字)
操作系统 AI 模拟试卷1及答案
操作系统代码改错题专项练习(10题)
本文通过分析Python3软链接报错`ln: failed to create symbolic link '/usr/bin/python3': File exists`,深入探讨了Linux文件系统中ln命令的工作原理和符号链接的设计哲学。文章详细解析了软硬链接的区别、inode机制以及Linux目录结构设计,并提供了安全管理符号链接的实用技巧,帮助读者深入理解Linux文件系统的核心概念。
路径处理是 Python 工程中高频却易错的基础能力。传统 os.path 将路径视为字符串,依赖函数拼接与手动校验,导致跨平台异常、符号链接误判、编码错误及调试困难。pathlib 通过 Path 对象将路径升格为一等公民,提供链式调用、类型提示、运算符重载(/)和原子化 I/O(read_text/write_bytes),从根本上提升可组合性、可测试性与可维护性。它不仅是语法糖,更是 Pyt
操作系统9000字大纲 一天看完 力挽狂澜!
本文深入解析USIM卡文件系统,通过APDU协议和Python脚本实战演示如何读取EFDIR等核心文件。从IMSI解码到网络列表分析,揭示SIM卡内200多种数据文件的组织结构与安全机制,并提供自动化诊断工具开发指南。
在软件开发中,文件系统操作是基础且频繁的需求,涉及目录遍历、文件属性读取和异常处理等核心概念。其原理是通过系统API访问文件系统元数据,进行逻辑判断与比较。这项技术的价值在于封装通用逻辑,提升代码复用性、可维护性,并增强程序的健壮性。应用场景广泛,例如在日志分析系统中自动定位最新的崩溃报告文件(如crash_2026-06-18_185652),或在数据管道中处理最新的上传文件。一个设计良好的静态
【飞牛云fnOS】告别数据孤岛:飞牛云fnOS私人资料管家
摘要:本文深入浅出地讲解了计算机swap技术(虚拟内存)的工作原理与应用。从历史背景出发,介绍了swap如何通过"空间换时间"的方式扩展内存容量,详细解析了页面置换、缺页中断等核心机制。对比了Linux、Windows和macOS三种系统的swap实现方式,客观分析了swap的优缺点,并提供了针对不同场景的优化建议。文章强调swap在现代计算环境中仍然发挥着重要作用,特别适合低
在AI Agent开发中,上下文管理正从传统RAG的向量化检索范式,转向更结构化、可追溯、可调试的新型架构。文件系统作为一种成熟、稳定、开发者高度熟悉的抽象模型,天然支持目录层级建模、URI资源定位与分层加载机制,为长程记忆、多源协同和跨会话状态保持提供底层支撑。OpenViking通过viking://协议实现上下文即文件、知识即目录、检索即路径遍历,结合L0/L1/L2三级摘要体系,在保障语义
操作类型 | 具体操作 | 工具方法 || ✅ 安全校验 | 查看允许目录 || ✅ 目录浏览 | 列出一级文件夹 || ✅ 目录创建 | 创建新文件夹 || ✅ 文件写入 | 创建并写入 Markdown 文件 || ✅ 文件读取 | 读取文件内容验证 |本文通过一个完整的实操案例,展示了 AI Agent 如何通过 MCP 协议调用 filesystem 工具,在受控目录内完成目录浏览、文件夹
本文为操作系统期末测试题,主要考察文件系统、设备管理和磁盘调度等知识点。单选题涵盖UNIX文件权限、文件类型、目录结构、索引文件等概念,设备管理部分涉及缓冲技术、SPOOLing系统和设备驱动程序等。判断题考察文件存取方式、Linux文件分类和设备虚拟化等知识。应用题通过SSTF磁盘调度算法计算磁头移动总量,正确答案为B选项(162)。测试题全面覆盖操作系统核心概念,重点考查UNIX/Linux系
操作系统期末复习摘要 一、核心概念 操作系统定义:控制和管理计算机资源,组织多道程序运行的系统软件(B)。 基本职能:资源管理、多道程序运行(D)。 系统类型: 分时系统:及时响应(C);实时系统:快速处理(C),如航空订票系统。 进程管理: 进程是动态执行的程序(B),状态转换由调度、I/O等事件触发。 同步与互斥:通过信号量(P/V操作)实现(D)。 死锁条件:互斥、占有等待、非抢占、循环等待
文件系统
——文件系统
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区


 openEuler 社区
openEuler 社区


 深开鸿 技术专区
深开鸿 技术专区



 AI编程社区
AI编程社区



















 AI硬件创业社区
AI硬件创业社区
 HarmonyOS开发者社区
HarmonyOS开发者社区




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 DAMO开发者矩阵
DAMO开发者矩阵



 MCP技术社区
MCP技术社区
 CSDN-OPC开发者社区
CSDN-OPC开发者社区



