




- @dou3516
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当git项目较大或网速不快的情况下,git clone可能会中断,其不支持断点续传,导致要重新操作,那如何进行断点续传呢。为了在断掉后,自动git fetch, 我写了一个bash脚本样例, 会循环执行,重试2000次,直到成功后退出。5.命令行执行 git remote add origin [项目地址]1.新建目录, 命令行进入目录,执行 git init。2. 命令行执行: git fetc

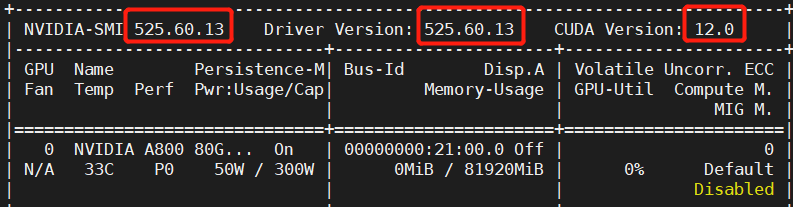
使用nvidia-smi命令查看显卡状态时,出现错误:而使用nvcc -V查看cuda版本时,显示正常。
【docker】容器启动多个终端docker exec -it cd3b79a85d7e /bin/bash
1 梯度爆炸原因:学习的过程中,梯度变得非常大,使得学习的过程偏离了正常的轨迹。症状:观察每次迭代的loss值,会发现loss明显增长,最后因为loss值太大以至于不能用浮点去表示,所以变成了Nan。可采取的措施:1 降低学习速率,2 如果模型中有多个loss层,就需要找到梯度爆炸的层,然后降低该层的loss weight。2 学习率过高原因:过高的学习率乘上所有的梯度使得所有参数变成无效的值。症
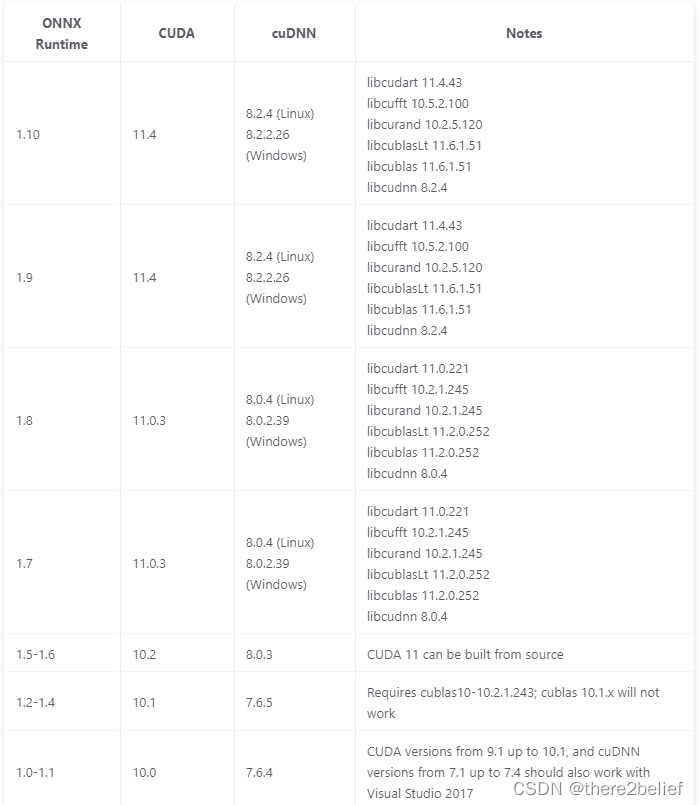
No worries. Then please check your CUDA and CuDNN versions. They must be compatible to each other. Here is the link which might be helpful:CUDA - onnxruntimeFor ONNXRuntime 1.9.0 package, I think it w
在使用dockerfile文件创建镜像的时候,采用docker build命令,例如docker build -t image_name会报错:"docker build" requires exactly 1 argument(s).出错原因是命令最后需要一个点,即:docker build -t image_name .为什么会有这个点呢,来看下Docker build命令docker bui

Windows 7电脑:依次打开“计算机”——“控制面板”——“Windows防火墙”,如下图所示:Windows 10电脑:依次打开“开始菜单”——“设置”——“Windows 防火墙”,如下图所示:入栈规则设置:打开高级设置,点击左侧“入站规则”,再点击右侧“新建规则...”,如下图:选择“端口(O)”,点击“下一步”按钮,如下图:“此规则应用...
1. 示例我有一个没有发布到PyPI源上的python包(主要有一个setup文件就行),位置在git上,我希望以pip install的方式安装,一步解决,而不是先git clone,再转到对应目录,进行安装。通常的安装# 两步走的安装(安装完还需要自己删除git文件)git clone http://127.0.0.1/XXX/demo.git#change dircd demo# insta
https://stackoverflow.com/questions/29846087/microsoft-visual-c-14-0-is-required-unable-to-find-vcvarsall-batPython采用PIP安装命令安装有时候会提示microsoft visual c++ 14.0 is required主要是由于安装包不是.whl格式,pip无法编码识别,...
为什么简单的「集成」便能够提升性能呢?本文是对上述问题的解析,作者解读了来自微软研究院高级研究员朱泽园博士,以及卡内基梅隆大学机器学习系助理教授李远志的最新论文《在深度学习中理解集成,知识蒸馏和自蒸馏》。本文授权转自智源社区,作者梦佳集成(Ensemble,又称模型平均)是一种「古老」而强大的方法。只需要对同一个训练数据集上,几个独立训练的神经网络的输出,简单地求平均,便可以获得比原有模型更高的性