




- @pipisorry
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了直接偏好优化(DPO)算法,该算法通过隐式奖励模型优化语言模型偏好。DPO无需显式奖励模型和强化学习,直接优化策略模型,其损失函数通过推导最优奖励模型形式得出。训练分为两步:先用偏好数据微调基础模型,再通过DPO目标函数优化。虽然DPO理论上与RLHF等价,但在实际应用中,由于偏好数据有限,训练效果可能不如使用泛化性奖励模型的强化学习方法。文章还提供了DPO的训练数据格式示例和算法评价,
之前是写在[]里的,抽出来单独讲一下。InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。:先采样一些demonstration数据,其包括prompt和labeled answer。基于这些标注的数据,对GPT-3进行fine-tuning,得到SFT(Su
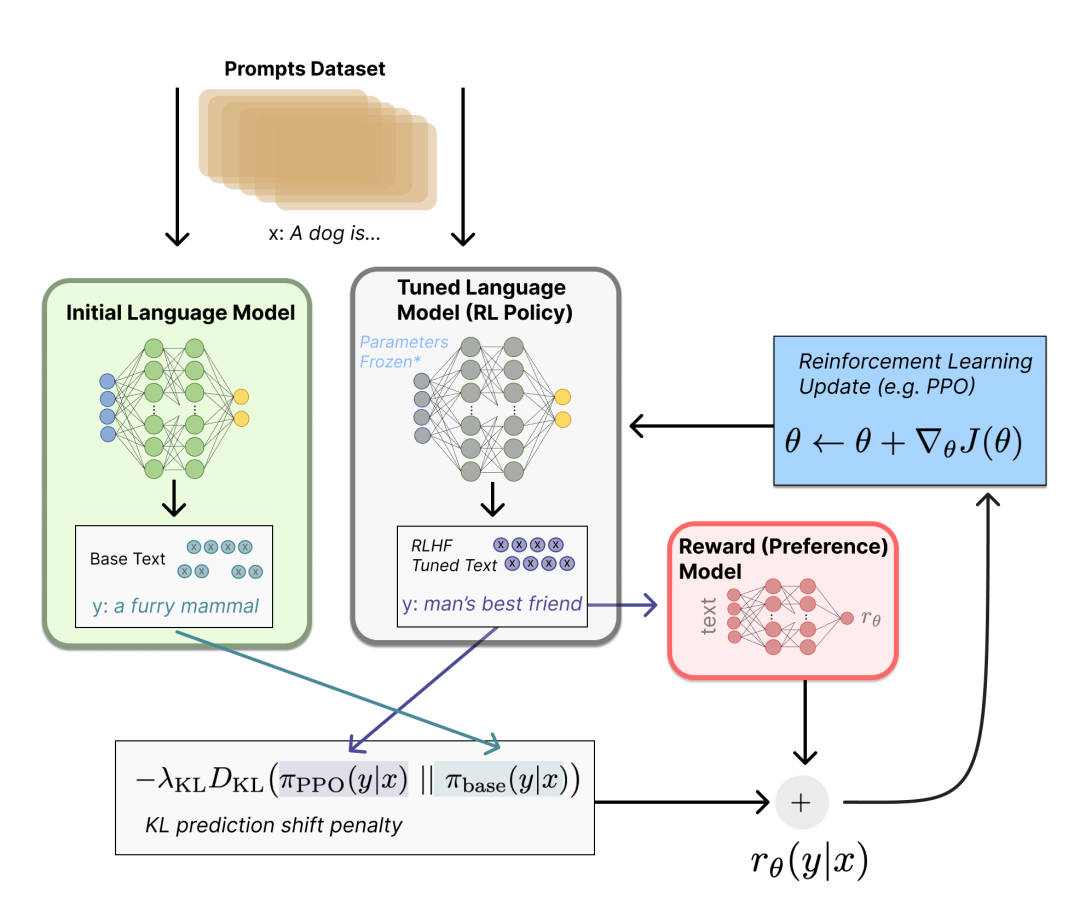
之前是写在[]里的,抽出来单独讲一下。InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。:先采样一些demonstration数据,其包括prompt和labeled answer。基于这些标注的数据,对GPT-3进行fine-tuning,得到SFT(Su
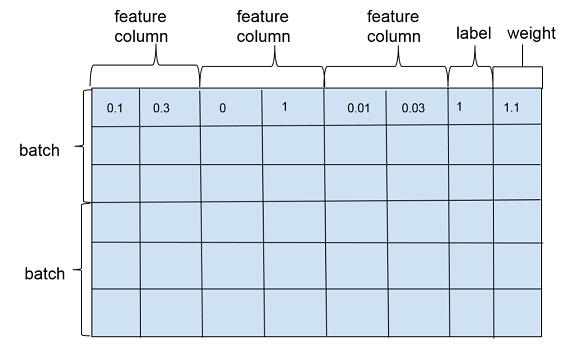
wide and deep 模型训练一般是以多个训练样本作为 1 个批次 (batch) 进行训练,训练样本在行维度上定义,每一行对应一个训练样本实例,包括特征(feature column),标注(label)以及权重(weight),如图 2。特征在列维度上定义,每个特征对应 1 个 feature column,feature column 由在列维度上的 1 个或者若干个张量 (tenso
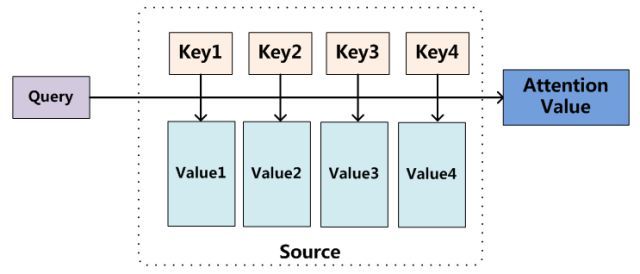
注意机制最早由Bahdanau等人于2014年提出(统计机器翻译中的对齐过程[NEURAL MACHINE TRANSLATION BY JOINTLY。
http://blog.csdn.net/pipisorry/article/details/76573696带步幅的多通道巻积很多时候,我们输入的是多通道图像。如RGB三通道图像,下图就是。也有可能我们出于特定目的,将几张图组成一组一次性输入处理。多通道巻积假定我们有一个 4 维的核张量 K,它的每一个元素是 K i,j,k,l ,表示输出中处于通道 i 的一个单元和输入中处于通...
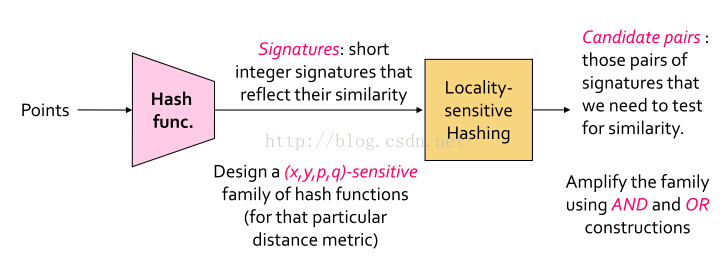
http://blog.csdn.net/pipisorry/article/details/48858661海量数据挖掘Mining Massive Datasets(MMDs) -Jure Leskoveccourses学习笔记之 Locality-Sensitive Hashing(LSH) 局部敏感哈希LSH第一部分。第二部分参考[海量数据挖掘MMDS week7: 局部敏感哈希...
http://blog.csdn.net/pipisorry/article/details/46972171Python经常被称作“胶水语言”,因为它能够轻易地操作其他程序,轻易地包装使用其他语言编写的库。在Python/wxPython环境下,执行外部命令或者说在Python程序中启动另一个程序的方法。1、os.system(command)os.system()函数用来运行shell命令。此
http://blog.csdn.net/pipisorry/article/details/45311229结巴分词jieba特点 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析; 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义; 搜索引擎模式,在精确模式的基础上,对长词再次切分...
http://blog.csdn.net/pipisorry/article/details/39234557这篇文章是python基本数据结构的高级教程,一般的用法请自行参考python入门教程python入门教程基础变量及其作用域[python变量及其作用域,闭包 ][python数据类型的内存分析 ]函数[python函数: 内置函数]运算符Pyt...
