登录社区云,与社区用户共同成长
邀请您加入社区
《一念成仙》创始人访谈:如何用CUI打造现象级修仙世界 2026年,QQ对话式机器人赛道迎来爆发,《一念成仙》以断崖式优势领跑行业。创始人分享了三大成功哲学:1)极致长板战略,在用户未提需求时就通过高品质内容建立壁垒;2)突破性好奇心,将浅层"玩具"发展为可沉浸多年的深度体验;3)技术前瞻性任性,坚信对话式交互终将超越传统APP界面。通过不计成本的内容打磨和对CUI赛道的坚定信念,这款独立开发产品
首先,您需要下载并安装官方的 Codex 桌面版应用程序。访问下载对应您操作系统的安装包。安装过程无需登录或激活任何账号,保持默认状态即可。安装后,建议让 Codex 在后台持续运行,以避免被系统静默关闭。Codex++ 是一个外部增强启动器,它不会修改 Codex 的原生文件,而是通过注入脚本的方式为 Codex 解锁额外功能。这是实现纯 API 模式接入和插件解锁的关键工具。这是最关键的一步,
摘要:本研究基于2000-2024年沪深A股上市公司年报数据,采用文本挖掘技术构建数字化转型信息披露数据库,涵盖42项数字技术特征词频。数据包含63,055条有效记录,支持数字化转型时序趋势、行业差异、资本市场影响等实证研究。重点探索企业转型强度(kw_sum)与资本市场表现的关系,识别"言-行"匹配度差异,为监管和企业决策提供数据支撑。研究选题涵盖数字金融调节效应、行业异质性
关于生成式AI对大学生学习投入度影响研究的调研问卷
鸿蒙上拉起微信、支付宝免弹窗实现
大家好,我是simple。我的理想是。
微信开发者需注意OpenID和UnionID的区别:OpenID是用户对单个公众号的唯一标识,同一用户在不同公众号拥有不同OpenID;UnionID则是同一微信开放平台账号下多应用间的用户统一标识。建议开发初期就记录UnionID,以实现多平台账号互通,避免后期因仅记录OpenID导致的账号打通困难与运营成本增加。
对于专利数据,首先对标题和摘要文本进行分词,分词后包含人工智能相关关键词的专利则记为人工智能专利,企业每年的人工智能专利数加1取对数则为人工智能专利指标。其研究价值体现在:通过构建企业层面的人工智能指标,发现人工智能能显著提升中国上市公司的生产率,揭示了人工智能通过调整企业劳动力技能结构来提升生产率的机制,同时还能探究企业层面因素和行业、地区层面因素对人工智能生产率效应的影响,进而加深对微观企业层
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。提示:以下是本篇文章正文内容,下面案例可供参考提示:这里对文章进行总结:例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
这不只是一本书,更是你通往AI技术前沿,掌握ChatGPT、OpenAI API和DeepSeek核心应用的实战地图。
C#中的Zip方法是System.Linq提供的扩展方法,用于将两个序列的对应元素组合。它按照元素位置配对,以较短序列为准,多余元素忽略。基本语法为:序列1.Zip(序列2,(元素1,元素2)=>结果)。该方法惰性执行,适用于合并相关数据、并行遍历等场景。示例展示了数字与单词配对、处理不同长度序列、数学运算等用法。在微信用户标签管理案例中,Zip将用户ID数组和标签数组组合成字典,实现批量打
技术确实在进步。现代 SSR 拥有组件化、状态管理、渐进式增强等优势,这是 PHP 没有的。但同时,我们也不能否认:现在所谓的“创新”,很多其实只是“重新命名的轮子”。SSR 的回归不是因为它新,而是因为我们终于想起它为什么有效。下次当有人对你说:“我们公司正在采用最前沿的 SSR 技术!你不妨问一句:“这……不就是 PHP 换个皮?如果对方犹豫了,那你大概就知道答案了。
关于【C++嵌套 if 语句】
指向类的指针。
关于【C++中常用的排序方法之——冒泡排序】目录:一、 冒泡排序的定义二、冒泡排序的算法原理三、冒泡排序的算法示例四、冒泡排序的算法分析五、冒泡排序的特点六、冒泡排序的优点七、冒泡排序的缺点
关于【C++中常用的排序方法之4——希尔排序】一、希尔排序的定义二、希尔排序的发展历史三、希尔排序的的排序过程四、希尔排序的基本原理五、希尔排序的的特点六、希尔排序的的优点七、希尔排序的的缺点
关于【C++中常用的排序方法之3——插入排序】一、插入排序的定义二、插入排序的的思路及具体步骤三、插入排序的的算法性能四、 插入排序的适用场景五、 插入排序的的特点六、 插入排序的的优点七、插入排序的的缺点
关于【简单又好用的AI工具】目录:一、什么是AI二、AI工具汇总三、个人使用AI工具体验分享四、总结
关于【C++ 类构造函数 & 析构函数】
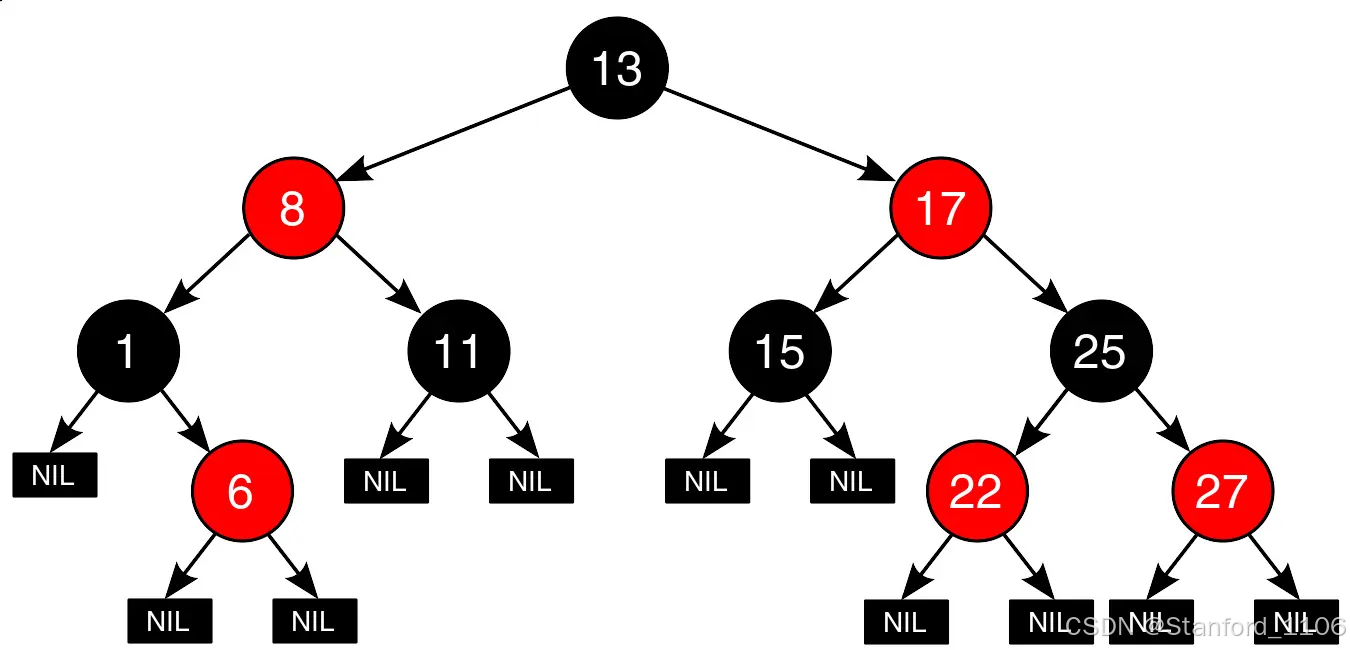
关于【C++数据结构红黑树】一、什么是数据结构二、什么是红黑树三、红黑树的性质四、红黑树的操作五、红黑树与其他平衡二叉树的区别六、红黑树的用途
https://blog.csdn.net/mr_yuanshen/article/details/151926211?sharetype=blogdetail&shareId=151926211&sharerefer=APP&sharesource=2401_85812043&sharefrom=link
https://blog.csdn.net/2401_82648291/article/details/152114383?sharetype=blogdetail&shareId=152114383&sharerefer=APP&sharesource=2401_85812043&sharefrom=link
读取图像后,可以使用`cv2.imshow()`函数在一个窗口中显示图像,并通过`cv2.waitKey()`控制窗口的显示时间,最后用`cv2.destroyAllWindows()`关闭所有窗口以释放资源。此外,我们经常需要在彩色图和灰度图之间进行转换,`cv2.cvtColor()`函数可以实现色彩空间的转换,其中`cv2.COLOR_BGR2GRAY`是将BGR图像转换为灰度图最常用的参数
/ 异步写入,避免阻塞。通过智能指针(`unique_ptr`/`shared_ptr`)自动释放资源,减少内存泄漏风险。| pprof| 结合gperftools的性能剖析工具|| ClusterControl| 并发性能瓶颈检测(CPU/内存/IO)|| gprof| 分析CPU时间分布与函数调用图|| Callgrind| 仿真执行跟踪,精准定位热点|CPU_SET(0, &cpu_set)
摘要:本研究基于豆包和Claude双模型对中国A股上市公司(2010-2024年)的经营范围文本进行智能识别,构建人工智能企业分类数据集。相比传统机器学习方法,双模型能更精准理解复杂语义,有效识别涉及AI技术的企业。数据包含股票代码、行业分类和AI企业标识(0/1),适用于AI企业发展轨迹、经营绩效、政策影响等研究方向,为产业分析和学术研究提供可靠数据支持。
点进去3步搞定,我用了2年多了,稳定,好用,操作也贼简单咯,建议先看一遍教程,3.点击确认✅,等个2分钟左右,刷新就可以切换使用各种模型,2.登录gpt,点我获取充值密钥,粘贴到第二部。1.买个卡密,点击24小时自助操作,
文章摘要: 本文介绍了SpringBoot整合微信开放平台网站应用扫码登录的简化实现方案。主要内容包括:1)微信开放平台配置(创建网站应用、获取AppID/Secret);2)核心接口设计,仅保留获取授权链接和授权回调两个关键接口;3)实现流程:生成带防CSRF的授权链接→用户扫码授权→回调获取用户信息→自动注册/登录并返回业务Token。方案特点:无需前端轮询,适配SpringBoot+Redi
当前博文未提及该问题,以下是基于C知道的知识内容为您回答在平台获取用于 Claude Code API 调用的 API 密钥,需要完成注册、认证和密钥生成等一系列操作。
这款学龄前儿童国学教育APP采用SpringBoot框架,为家长和孩子提供了一个内容丰富且互动性强的教育平台。家长可以通过注册和登录功能为孩子创建个性化账号,在主界面上浏览各种学习资源和育儿知识。平台的内容根据不同类别进行组织,帮助家长轻松找到符合孩子需求的学习内容。互动问答板块提供了多种题型,帮助家长了解孩子的学习进度,并且通过亲子互动活动,家长和孩子可以共同参与、学习和玩耍,增强教育的乐趣与效
本文介绍了CodeXCLI的安装与配置流程:首先下载对应系统的安装包并配置环境变量;然后在VSCode中安装插件并修改设置文件关联路径;接着通过初始化命令创建项目配置文件并进行功能测试;最后提供了环境变量配置和插件兼容性等常见问题的解决方法。全文提供了从安装到调试的完整指导,重点包括路径配置和问题排查步骤。
相较于GLM-5.1的40分,这是一次11分的代际式跳跃。与GLM-5.1相比,GLM-5.2在科学推理(CritPt)上跳跃了16个百分点至21%,在HLE上提升了12个百分点至40%,在AA-LCR语言理解上提升了9个百分点至71%,在tau3银行业务评测上提升了15个百分点至27%,在SciCode科学编程上提升了7个百分点至50%,在TerminalBench v2.1终端操作能力上提升了
不同国家和地区的观众有着不同的文化背景和审美习惯,如何创作出既符合当地观众口味又具有国际影响力的短剧作品,是短剧国际版需要解决的问题。随着国际短剧市场的不断扩大,越来越多的短剧作品涌现出来,如何脱颖而出,吸引观众的关注和喜爱,是短剧国际版需要思考的关键问题。同时,短剧国际版也吸引了众多优秀的创作者和演员,他们通过短剧平台,将自己的创意和才华展现给全球观众,推动了短剧艺术的不断发展。同时,随着技术的
微信开放平台
——微信开放平台
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区
 AtomGit AI 社区
AtomGit AI 社区

 HarmonyOS开发者社区
HarmonyOS开发者社区



 全球具身智能开发者社区
全球具身智能开发者社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 AI Agent技术社区
AI Agent技术社区

















 DAMO开发者矩阵
DAMO开发者矩阵