




- @cao919
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
C#中的Zip方法是System.Linq提供的扩展方法,用于将两个序列的对应元素组合。它按照元素位置配对,以较短序列为准,多余元素忽略。基本语法为:序列1.Zip(序列2,(元素1,元素2)=>结果)。该方法惰性执行,适用于合并相关数据、并行遍历等场景。示例展示了数字与单词配对、处理不同长度序列、数学运算等用法。在微信用户标签管理案例中,Zip将用户ID数组和标签数组组合成字典,实现批量打
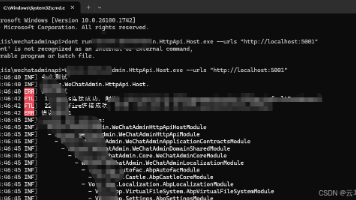
摘要:.NET Core项目可通过多种方式指定运行端口:1)命令行参数(--urls)最常用,支持FDD和SCD部署;2)环境变量ASPNETCORE_URLS设置;3)修改appsettings.json配置文件永久生效。注意:0.0.0.0允许外部访问,localhost仅限本机;HTTPS需配置证书。参数优先级:命令行>环境变量>配置文件。(149字)
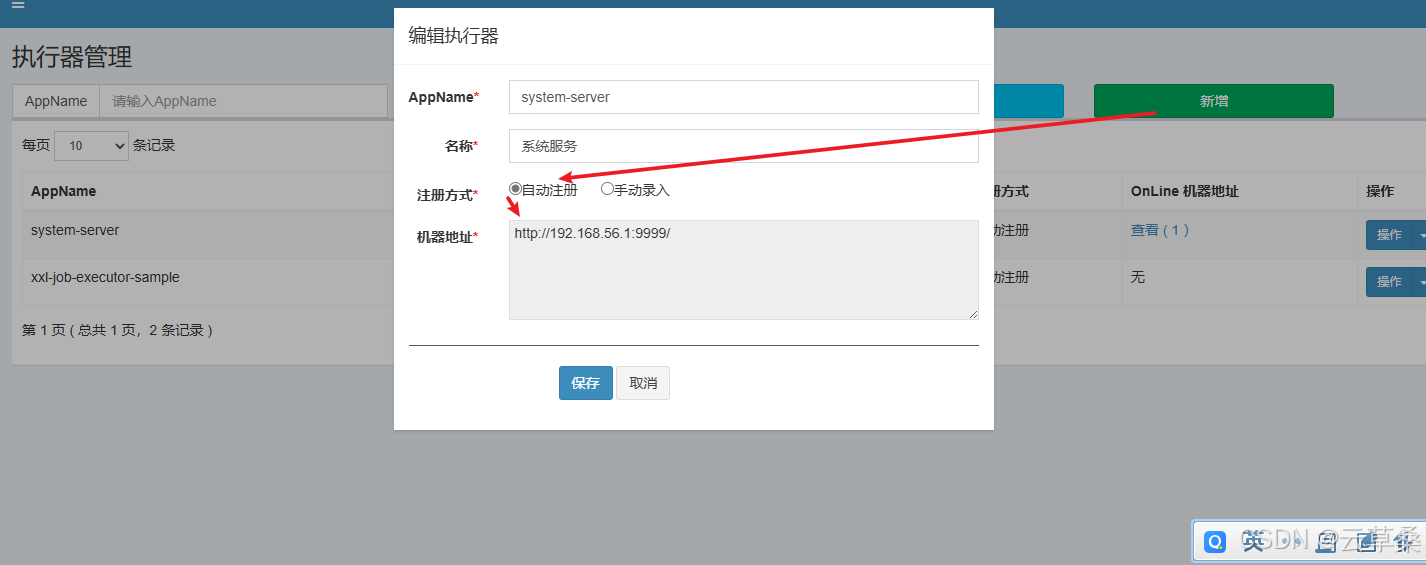
项目基于 XXL Job 实现分布式定时任务,支持动态控制任务的添加、修改、开启、暂停、删除、执行一次等操作。疑问:为什么使用 XXL-Job 呢?目前国内开源的 Job 框架,经历过大规模的中大厂的考验,稳定性和功能性都是有保障的,目前可能只有 XXL-Job 和 Elastic-Job 两个选择。相对来说,XXL-Job 更加轻量级,大家更容易上手。
本文提供了Windows系统下Docker Desktop环境的完整迁移方案,包含镜像、容器和数据卷的备份恢复方法。主要步骤包括:1)确保两台电脑安装相同版本Docker并启用WSL2;2)通过批处理脚本备份所有Docker镜像到tar文件;3)使用PowerShell命令迁移数据卷;4)在新电脑恢复镜像和数据。文章特别强调了常见问题的解决方案,如Docker未启动导致的命令报错、权限问题修复等,
数字孪生 是一种旨在精确反映物理对象的虚拟模型。给研究对象(例如风力涡轮机)配备与重要功能方面相关的各种传感器。这些传感器产生与物理对象性能各个方面有关的数据,例如,能量输出、温度和天气条件等等。然后将这些数据转发至处理系统并应用于数字副本。一旦获得此类数据,虚拟模型便可用于运行模拟、研究性能问题并生成可能的改进方案;所有这些都是为了获取富有价值的洞察成果,然后将之再应用于原始物理对象。

Service'MongoDB Server' failed to s配置启动服务创建数据目录MongoDB 将数据目录存储在 db 目录下。但是这个数据目录不会主动创建,我们在安装完成后需要创建它。请注意,数据目录应该放在根目录下 (如: C:\ 或者 D:\ 等 )。安装 管理软件创建数据库问题一:在安装过程中出现下面这个错误,这里我们先点‘Ignore’,先进行后续的安装。打开(servic

企业AI助理系统采用分层架构设计,包含智能体交互、知识中枢(RAG)、数据分析(NL2SQL)和工具调用(MCP)三大核心功能模块,支持自然语言查询、跨系统操作和可视化报表生成。技术选型上选用ASP.NET Core后端框架、Semantic Kernel AI框架、Qdrant向量数据库,并支持私有化部署。系统通过权限控制确保安全性,采用容器化云原生部署方案,为企业提供覆盖现有系统的智能化交互层
本文主要介绍了ERP系统中各类业务单据、产品、联系人模块的核心概念及区别,并分析了中英文术语翻译差异问题。主要内容包括:1. 采购、销售、库存等业务单据的区别与关联流程;2. Odoo中不同模块产品视图的侧重点;3. 联系人模块中客户、供应商等角色的统一数据模型;4. 术语翻译:分析中英翻译差异导致的常见混淆点,如"Invoicing"译为"发票"等案例;5. 中英翻译差异导致的术语混淆问题及案例

本文档提供.NET开发者进阶AI架构师的完整学习路径,包含五大核心模块:1)智能接口开发实战:基于.NET10原生AI能力实现自然语言驱动查询、动态参数校验等智能接口;2)智能业务系统构建:采用MicrosoftAgentFramework设计解耦的智能体架构;3)云原生微服务实战:涵盖Docker容器化、K8s集群部署及性能优化方案;4)50道架构师面试题库:覆盖AI技术栈、架构设计、性能优化等

本文档提供.NET开发者进阶AI架构师的完整学习路径,包含五大核心模块:1)智能接口开发实战:基于.NET10原生AI能力实现自然语言驱动查询、动态参数校验等智能接口;2)智能业务系统构建:采用MicrosoftAgentFramework设计解耦的智能体架构;3)云原生微服务实战:涵盖Docker容器化、K8s集群部署及性能优化方案;4)50道架构师面试题库:覆盖AI技术栈、架构设计、性能优化等