登录社区云,与社区用户共同成长
邀请您加入社区
摘要: 时光胶囊App的MoodPicker和CountdownBadge组件通过简洁交互实现核心功能。MoodPicker采用受控组件设计,由父组件管理状态,支持五种预设心情(如开心、难过),并通过背景色、边框强化选中态。CountdownBadge根据胶囊状态显示倒计时(天/小时)或解锁提示,三种状态对应不同颜色标识。两者均遵循单向数据流原则,确保主题同步与交互一致性,适配窄屏自动换行,优化小
本文介绍了基于行空板K10的麦克纳姆轮智能小车项目。行空板K10是一款国产物联网与AI学习开发板,集成了摄像头、麦克风、扬声器、屏幕及多种传感器。作者利用胜利羽毛球筒制作车身,搭配TT电机、麦克纳姆轮和锂电池扩展板,构建了一个可通过语音控制的四驱全向移动平台。项目详细解析了麦克纳姆轮的结构原理、四轮布局与六种基础运动模式的电机控制逻辑(前进、后退、横移、旋转等),并提供了完整的语音识别控制代码框架
ASR : automatic speech recognition: 自动语音识别===》 语音转文字。esp32 —》 websocket —》 电脑服务器 —》 保存wav。小智类似方案也是 ESP32 作为终端,通过网络连接 LLM。你之前已经学了 socket,这一步正好串起来。ESP32 不适合跑大型 ASR。最后加 MQTT 控制设备。“今天北京天气怎么样”第4步:TTS语音合成。北
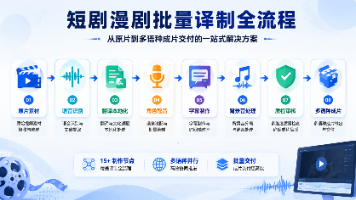
配音方面,漫剧的情绪表达通常比短剧更戏剧化,配音演员的风格选择也需要与漫剧的视觉风格匹配,而不只是参考真人短剧的配音标准。原片语音识别和文稿提取,时间轴标注,背景音初步分离,角色信息整理,翻译文稿制作,文化适配处理,翻译稿确认,配音演员选角和试配,批量录音,音频合成,字幕制作和时间轴对齐,背景音混合,多语种成片输出,质检,分批次交付。如果项目规模较大(50集以上),建议做3集样片,并且选一个情绪最
本文从架构角度分析了一个菜谱应用的数据流动和代码组织。项目包含5个页面和1个服务层,核心数据层RecipeData采用三层结构:接口定义、静态数据、共享状态与操作函数。数据流动呈现三种模式:静态数据直读、查询函数+@State副本、共享状态+操作函数。操作函数分为查询类、状态修改类和状态操作类,实现了跨页面数据同步。整体架构通过合理的分层和模式选择,在保持简洁的同时满足了功能需求,为类似应用开发提
随着全球化交流的不断深入,语音翻译已经成为跨语言沟通的重要工具。无论是跨境电商、国际会议、在线教育,还是海外旅游、智能客服等场景,都需要将一种语言快速转换为另一种语言,从而消除语言障碍,提高沟通效率。语音翻译API是一种基于人工智能技术的开放接口,能够自动完成"语音识别 → 文本翻译 → 语音播报"的整个处理流程。
行空板K10是一款专为快速体验物联网和学习人工智能而设计的开发学习板,100%采用国产芯片,知识产权自主可控,符合信息科技课程中编程学习、物联网及人工智能等教学需求。该板集成2.8寸LCD彩屏、WiFi蓝牙、摄像头、麦克风、扬声器、RGB指示灯、多种传感器及丰富的扩展接口。凭借高度集成的板载资源,教学过程中无需额外连接其他设备,便可轻松实现传感器控制、物联网应用以及人脸识别、语音识别、语音合成等A
SpeechWrite 是一个中文语音识别(ASR)系统,采用双引擎架构,支持从单一入口脚本完成音频转文字并导出四种格式(TXT / SRT / VTT / JSON),直接用于字幕制作和内容整理。
# Apple的SpeechAnalyzer API实测:系统级语音识别与Whisper的差距在哪里
本文探讨了在双仓库(Polyrepo)架构下实施 Kotlin Multiplatform (KMP) 的实战方案,突破了官方教程中单仓库和全栈跨端的理想化设定。针对大中型企业 Android/iOS 独立仓库的现状,提出以下核心方案: 物理连接:通过同级目录结构(如Git/Android和Git/ios-app)实现跨仓库访问,要求团队统一开发环境路径。 心智模型:Xcode 将 KMP 编译产
本文深入探讨了C++面向对象编程中的继承特性,重点讲解了继承的核心概念及常见问题。主要内容包括:1)继承的基本语法和访问控制规则;2)构造/析构函数的调用顺序及其原理;3)三种继承方式的区别与适用场景;4)菱形继承问题及虚继承解决方案;5)继承与组合的设计选择原则。文章通过机器人系统的设计案例,分析了继承在实际开发中的应用,并针对面试中常见的考点如虚析构函数、类型转换等提供了详细解答。最后给出了准
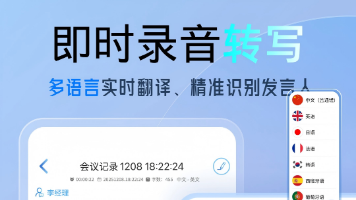
这类工具是利用语音识别技术和大语言模型,将会议录音、访谈音频、培训讲座等内容自动转写成文字,并进一步完成智能总结、纪要生成、发言人区分等结构化处理的软件产品。与传统录音笔只能录制声音不同,AI录音转文字工具能够在录音进行的同时实时生成文字稿,会议结束后直接输出可用的会议纪要,把原本需要一两个小时的人工整理压缩到几分钟的校对确认。
行空板K10是一款国产物联网与人工智能学习开发板,集成2.8寸彩屏、摄像头、麦克风、扬声器及多种传感器,支持离线语音识别、图像检测和语音合成功能。实验通过语音指令(如"启动"、"停车"、"转向")控制3630无刷减速电机驱动的双轮差速小车,结合行空板K10的语音识别模块和GPIO输出,实现语音交互控制。系统采用持续监听模式,唤醒词为"你好小新",支持多指令识别并在屏幕实时显示状态,适合人工智能与物
在当今科技飞速发展的时代,AI原生应用已经融入了我们生活的方方面面。语音识别作为其中一项重要的技术,其应用场景不断拓展。本文的目的就是深入研究语音识别在多种场景下的实际应用情况,探讨其技术原理、实现方法以及面临的挑战等内容。范围涵盖了语音识别的基本概念、算法原理、实际案例以及未来发展方向等多个方面。本文首先介绍语音识别的背景知识,包括相关术语和概念。接着讲解语音识别的核心概念及它们之间的关系,用形
2. 核心概念2.1 async/await 基础2.2 Task 系统3. 结构化并发3.1 TaskGroup 模式3.2 async let 绑定4. 数据竞争防护4.1 Actor 模型4.2 Sendable 协议5. 高级并发模式5.1 AsyncSequence 处理流数据5.2 AsyncStream 自定义异步序列6. 性能优化技巧6.1 任务优先级管理6.2 协作式取消检查7.
【代码】Apple基础(Xcode-Flutter-Singbox-AI提示词)
第二步:在 Xcode---Setting---Accounts 登录苹果开发者账号,并点击下载描述文件,后续用到。第一步:使用xcode 打开flutter项目 ios/Runner.xcworkspace。我的项目这里已经添加上版本号,但是打包出来无效,所以我手动修改了版本号,如下图。第六步:点击 Distribute App上传。第五步:打包Product--Archive。第三步:输入包名
Go语言异常处理机制摘要:panic用于处理严重运行时错误(如除零、数组越界),会中断执行流程并执行defer语句,若未被捕获则程序崩溃。recover可捕获panic,需在defer函数中使用,使程序恢复执行。errors.New可创建自定义错误,而panic(errors.New(...))可主动触发异常。通过结合defer+recover可实现容错处理,区分可预期错误(error)与不可恢复
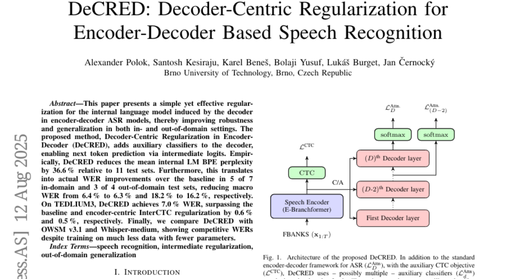
目前主流的解决方案主要依赖于大规模多领域训练,就像让学生在各种不同的环境中学习,从安静的图书馆到嘈杂的食堂,从正式的课堂到轻松的宿舍。布尔诺工业大学的研究团队发现了一个巧妙的解决方案,他们开发的DeCRED方法就像给这个"翻译官"增加了一位经验丰富的助手,专门负责理解语言的内在规律。DeCRED模型的训练过程体现了现代深度学习的最佳实践。说到底,DeCRED研究最重要的贡献可能不是具体的性能数字,
今天要分享的是我精心打磨的iOS开发子代理——这个配置能让Claude Code像一个精通苹果生态的资深iOS架构师,从SwiftUI到性能优化,从App Store审核到苹果全家桶集成,一个子代理搞定所有。:iOS开发不只是写代码,更是创造符合苹果设计哲学的精品应用。这个子代理帮你成为真正的iOS工匠。:如果你还不了解Claude Code子代理的基础概念,强烈建议先阅读我的上一篇文章。现在就配
语音识别技术在大数据领域的数据科学中扮演着至关重要的角色。随着大数据时代的到来,语音数据以海量的形式产生,如何高效地处理和利用这些语音数据成为了研究的热点。本文的目的在于全面介绍语音识别技术在大数据领域的应用,包括其核心原理、算法实现、实际应用场景等方面。范围涵盖了从基础的语音识别概念到前沿的技术应用,旨在为读者提供一个系统而深入的了解。本文将按照以下结构进行组织:首先介绍语音识别技术的核心概念与
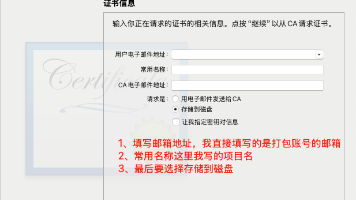
IOS打包证书申请 + xcode打包,纯图文详解,纯小白照抄2分钟学会。
是啊,以前我总想着把代码写得复杂才厉害,现在才明白,能简单解决问题的,才是真功夫。这‘Feature Flags’就像蓉儿你的打狗棒法,看似朴实,却能灵活应对各种场面 ——Debug 时‘大开大合’,TestFlight 时‘收放自如’,App Store 时‘稳如泰山’,真是妙极!
AI工具链正成为推动人工智能应用落地的关键力量。本文系统介绍了三大核心AI工具:智能编码工具GitHub Copilot基于Codex模型实现代码自动生成与补全;数据标注工具Label Studio支持多模态数据标注并提升数据质量;云端训练平台如Colab和SageMaker提供一站式模型开发环境。通过工具链整合,可构建从数据标注到模型部署的自动化流水线,显著提升AI开发效率。这些工具降低了AI应
本文系统解析了AI开发工具链三大核心组件:1)GitHub Copilot智能编码工具,通过Codex模型实现92%准确率的代码生成,结合结构化Prompt可显著提升效率;2)LabelStudio数据标注平台,支持多模态标注与智能预标注,配备双盲审核等质量控制机制;3)Canaan云训练平台,采用分布式架构实现15倍训练加速,集成混合精度等优化技术。
6.打包 OC 库,再别的 Swift 项目中导入后,就可以直接使用如下代码,而不会暴露 OC 库中的内容了。之前写过一篇 Xcode Pods自己编写的库Development Pods中的OC和Swift混编。5.创建暴露类 Project/ExposedModule.swift。4.创建包装 OC 功能的 Module/Module.swift。3.创建 Module/module.modu
我们的目标是解决**“语音识别的‘上下文盲区’”**——让AI不仅能“听懂 words(单词)”,更能“理解 context(上下文)”。什么是“上下文工程”?它和“提示工程”有什么关系?如何用技术手段给语音识别“加记忆”?实战:手把手搭一个“能记对话历史的智能语音助手”。故事引入:用“语音助手的尴尬瞬间”戳中你的痛点;核心概念:用“妈妈做饭”比喻讲清“提示工程”和“上下文工程”;原理拆解:用“老
的七个核心参数:1)核心线程数(corePoolSize):池中保持的最小线程数;2)最大线程数(maximumPoolSize):池允许创建的最大线程数;3)空闲线程存活时间(keepAliveTime):非核心线程空闲后的存活时长;6)线程工厂(threadFactory):用于创建新线程的工厂;7)拒绝策略(handler):当线程池和队列已满时的处理策略。其工作原理是预先创建一定数量的线程
当您需要创建自定义集合类时,实现GetEnumerator方法并使用yield return可以极大地简化代码。相比传统实现IEnumerator接口需要手动维护状态的方式,yield return让您可以用近乎同步的编码风格编写异步的迭代逻辑,代码可读性和维护性都得到显著提升。
运行Flutter Doctor检查环境。使用Homebrew安装Flutter。安装Homebrew(如果尚未安装)创建第一个Flutter应用。6.1 在iOS模拟器中运行。运行:flutter run。用USB线连接iPhone。4.1 Xcode未配置。在iPhone上信任电脑。升级Flutter和依赖。使用Xcode打开项目。6.2 在真机上运行。
在分布式语音识别服务中,核心功能是实现语音到文本的基本转换,这是用户最依赖的服务。语音输入处理:捕获和预处理音频信号。基本识别:将语音转换为文本,确保最低准确率(例如,$accuracy > 0.8$)。结果输出:返回文本结果给用户。高级语言模型优化(如上下文理解)。实时响应(延迟低于$100ms$)。多语种或多方言支持。附加功能如情感分析或噪音消除。核心功能的优先级最高,降级策略需确保其始终可用
选择。
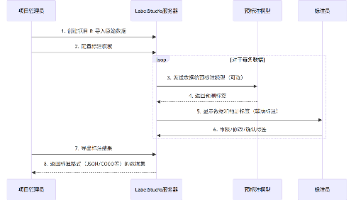
在分布式语音识别服务中,数据分片技术通过并行化提升效率(如降低延迟$T_{\text{parallel}}$),但必须与一致性需求(如错误率$P_{\text{error}}$)谨慎平衡。在分布式语音识别服务中,数据分片技术是将输入的音频数据分割成多个片段(如时间块或频率段),以便在多个计算节点上并行处理,从而提高系统的吞吐量和响应速度。例如,假设总音频时长为$T$,分片数为$n$,则理想情况下处
在 Objective-C 中,通过关联对象(Associated Objects)实现属性的动态添加。核心原理是将键值对与对象关联,突破类扩展的限制。通过灵活运用 Runtime,可在保持类型安全的前提下实现高度动态化编程,但需严格遵循内存管理规则和线程安全原则。实现方法注入,需处理选择器(SEL)与函数指针(IMP)的映射关系。动态方法需手动确保参数/返回值类型匹配,错误类型编码会导致崩溃。频
(在.m中),这是实现"公有只读,私有可写"的标准模式。控制写权限,利用类扩展重新声明为。
xcode
——xcode
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 HarmonyOS开发者社区
HarmonyOS开发者社区


 DAMO开发者矩阵
DAMO开发者矩阵


 人工智能6S服务平台
人工智能6S服务平台

 AI Agent技术社区
AI Agent技术社区



 AMD开发者中国社区
AMD开发者中国社区





 EazyDevelop社区
EazyDevelop社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区