- @xzp740813
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细介绍了如何使用RAGFlow和GLM-4-FLASH免费API搭建专属AI知识库,解决工程文档查询难题。教程按前期准备、Docker安装、RAGFlow配置、API获取与接入步骤展开,包含硬件要求、环境搭建等详细内容,特别标注了新手要点和避坑提醒。零代码基础即可操作,让AI精准解答工程文档问题,适合工程领域技术人员收藏学习。
本文是一份面向个人用户和中小企业的零代码本地知识库搭建教程,介绍了"大语言模型+企业知识+RAG"的核心架构。推荐了Qwen3和DeepSeek两款适合中文场景的开源模型,并详细指导了NVIDIA 40/50系列显卡的选择。通过Ollama或LM Studio等工具无需编程即可部署模型,结合Open WebUI或Dify构建知识库,最终实现安全、可控的本地智能问答系统,让企业文档"活"起来。

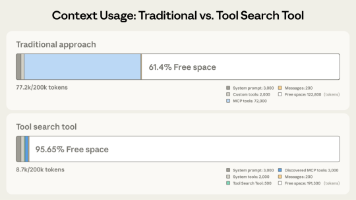
文章介绍了Anthropic最新发布的三个Beta功能:Tool Search Tool、Programmatic Tool Calling和Tool Use Examples,分别解决AI Agent工具选择、执行效率和参数准确性问题。这些功能通过按需加载工具定义、允许AI编写代码批量处理数据、提供具体使用示例等方式,显著降低了token消耗并提升了准确率。这些创新标志着AI Agent开发正从
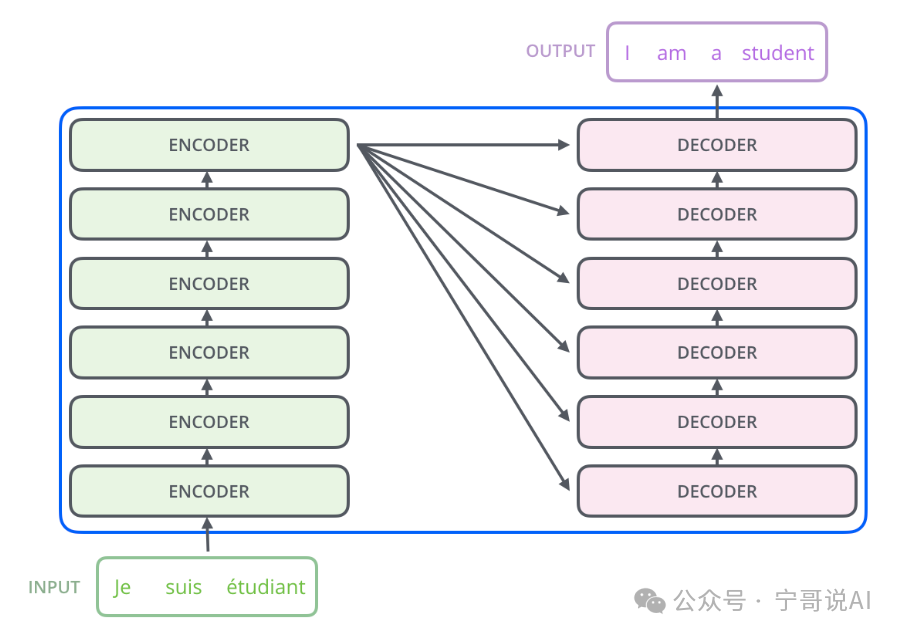
本文系统梳理了从LLM到Agentic AI的技术演进历程,从Agent概念溯源出发,分析了单智能体的局限性与多智能体的协作优势,阐述了Agentic AI的核心特征与本质内涵。文章指出,技术组合带来的能力涌现是推动AI从被动对话工具向主动智能伙伴进化的关键,Agentic AI作为通向AGI的重要前站,正在重塑人类与智能系统的协作范式。

MemMachine为AI Agent提供双层记忆系统(剧情脑和档案脑),解决LLM"金鱼记忆"问题。教程详述其安装配置(支持OpenAI和阿里云API),使AI能持久化记忆用户信息,适用于客服、陪伴型AI等场景,让AI真正"了解你、记得你"。
Datawhale社区推出的"Hello-Agents"项目是一个系统性AI智能体学习教程,旨在帮助读者从零开始构建AI Native Agent。教程结合理论与实战,使用自研HelloAgents框架,深入讲解智能体核心原理、架构和经典范式,让读者从大模型使用者蜕变为智能体系统构建者。项目提供在线阅读和PDF下载,适合有Python基础的开发者学习。
文章分享2026年个人AI知识库最优解:"自产内容存Obsidian,外部信息用NotebookLM"。Obsidian确保数据主权并支持AI集成,NotebookLM提供强大性能和深度研究功能。作者通过这套组合实现自动化工作流,既保证核心资产安全,又享受顶级AI处理效能,打造出"前店后厂"的高效知识管理体系。

本文详细介绍了LangGraph多智能体系统的两种核心架构模式:主管架构通过中央主管智能体管理多个专业智能体,适合结构化任务;分层架构引入团队层级概念,由顶层主管协调团队主管,有效解决了主管架构的扩展性问题。文章通过代码实例展示了两种架构的实现方式,帮助开发者构建更灵活、强大的多智能体应用,以应对复杂业务场景。
如果你还没有安装 Python 环境,那么推荐你安装 Anaconda,对于上手 Python 来说更加简单,不容易出差错。Anaconda 的安装教程网上很多,进入Anaconda下载网址(https://www.anaconda.com/products/individual) ,找到对应版本客户端安装即可。安装好后,即可上手。
ChatGPT很牛X,上知天文,下至地理,中间还通晓人情世故。类似它的产品还有一大帮,例如:文心一言、通义千问、kimiChat…等等。而且通过我们技术工作者的不懈地努力,AI的应用已经逐渐渗入我们工作和生活的很多场景和角落,在很多工作场景下,我们都不得不感叹一句”算你NB,在下告辞!那么我们究竟是该屈服于AI大老爷的淫威之下,还是要起来反抗将其玩弄于股掌之间,这是一个选择!但是无论我们如何选择,