- @fufan_LLM
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
QwQ是Qwen系列的大模型之一,专注于推理能力(reasoning)。相比于传统的指令微调(instruction-tuned)模型,QwQ 具备思考与推理(thinking and reasoning)的能力,因此在各种下游任务(特别是复杂问题)上,能实现显著的性能提升。QwQ-32B是该系列的中等规模推理模型,其性能可媲美当前最先进的推理模型,如和o1-mini。

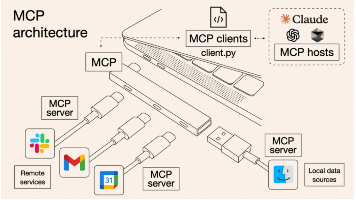
本期内容详解学习MCP必备技术基础,讲解MCP客户端、服务器开发方法及二者接入流程等等。

—这个项目用什么语言、什么框架、什么包管理器。
这篇讲的,是 Anthropic 内部已经有人验证过的用法。你的场景不一定和他们一样。试完之后会碰到这类工具在你具体场景里能做什么、做不到什么——那是下一步的事。第一步是:先看见这类工具在真实场景里用起来是什么样的,知道入场点在哪里。先别急着学工具。回头看看你这一周做过的活,哪一件是反复在重复的——那很可能就是你的第一张任务卡。如果你还不知道该怎么上手 Claude Code 和 Codex,这个

从一个已有的内部工作流出发,把其中某一段"人工处理"的环节替换成"AI 处理",然后设计这个替换的完整方案:AI 什么时候介入、处理什么、结果怎么呈现给下一步、什么情况下要人工 review。但写完之后,一个很具体的问题会浮现:这份设计里,什么是 AI 真正能做到的,什么是 AI 做不到的?这个角色出现的背景是:很多公司有技术团队,也有 AI 工具,但业务和技术之间缺一个会"翻译"的人——既能跟业
给 user-profile 模块添加邮箱 + 密码登录,复用现有的 auth-service,不新增第三方库,写测试覆盖主路径」是会用级描述——约束条件写进去,Codex 在计划阶段就能体现在步骤里。第一,测试命令写清楚。进入项目后,可以让 Codex 帮你起草——在对话框里说「扫描这个项目的结构,帮我生成一份 AGENTS.md」,它会读代码库,给出一份初始版本。装好 Codex App,没有
相比之下,Unsloth提出的动态量化方案会更加综合一些,所谓动态量化的技术,指的是可以围绕模型的不同层,进行不同程度的量化,关键层呢,就量化的少一些,非关键层量化的多一些,最终得到了一组比Q2量化程度更深的模型组,分别是1.58-bit、1.73-bit和2.22-bit模型组。· 确认硬件型号和运行模式:如果是CPU+GPU混合推理,那4代志强CPU推理性能更强,如果是纯GPU推理,需要确认是

LangGraph与MCP技术深度融合实现智能体开发 本文系统介绍了LangGraph框架与MCP(Model Context Protocol)技术的集成应用。主要内容包括: 技术基础 LangGraph作为LangChain的高级编排工具,支持图结构工作流 MCP技术规范统一了大模型调用外部工具的通信标准 两者结合可实现模块化、高效的智能体开发 核心实现 MCP工具的两种运行模式:离线(Std

阿里云百炼平台是一款一站式的大模型开发及应用构建平台,旨在帮助开发者和业务人员快速设计和构建大模型应用。用户可以通过简洁的界面操作,在短时间内开发出大模型应用或训练专属模型,从而将更多精力专注于应用创新。近期,阿里云百炼平台正式推出了全生命周期的MCP(Model-Connect-Protocol)服务,实现了从资源管理到部署运维的全流程自动化。用户仅需5分钟即可快速创建连接MCP服务的智能体(A

MCP,全称是Model Context Protocol,模型上下文协议,由Claude母公司Anthropic于去年11月正式提出。从本质上来说,MCP是一种技术协议,一种智能体Agent开发过程中共同约定的一种规范。这就好比秦始皇的“书同文、车同轨”,在统一的规范下,大家的协作效率就能大幅提高,最终提升智能体Agent的开发效率。截至目前,已上千种MCP工具诞生,在强悍的MCP生态加持下,